What storage systems data (SHD) and what is it for? What is the difference between iSCSI and FiberChannel? Why did this phrase only in recent years become known to a wide circle of IT-specialists and why are the issues of data storage systems more and more worrying thoughtful minds?
I think many people noticed development trends in the computer world that surrounds us - the transition from an extensive development model to an intensive one. The increase of megahertz processors no longer gives a visible result, and the development of drives does not keep up with the amount of information. If in the case of processors everything is more or less clear - it’s enough to assemble multiprocessor systems and / or use several cores in one processor, then in case of issues of storage and processing of information it’s not so easy to get rid of problems. The current panacea for the information epidemic is storage. The name stands for Storage Area Network or Storage System. In any case, it’s special 
Main problems solved by storage
So, what tasks is the storage system designed to solve? Consider the typical problems associated with the growing volume of information in any organization. Suppose these are at least a few dozen computers and several geographically spaced offices.
1. Decentralization of information - if earlier all data could be stored literally on one hard disk, now any functional system requires a separate storage - for example, servers email, DBMS, domain and so on. The situation is complicated in the case of distributed offices (branches).
2. The avalanche-like growth of information - Often the number of hard drives that you can install in a particular server cannot cover the capacity of the system. Consequently:
The inability to fully protect the stored data is indeed, because it is quite difficult to even backup data that is not only on different servers, but also geographically dispersed.
Insufficient information processing speed - communication channels between remote sites still leave much to be desired, but even with a sufficiently “thick” channel it is not always possible to fully use existing networks, for example, IP, for work.
Complexity reserve copy - if the data is read and written in small blocks, then it can be unrealistic to make full archiving of information from a remote server through existing channels - it is necessary to transfer the entire amount of data. Local archiving is often impractical for financial reasons - backup systems (tape drives, for example), special software (which can cost a lot of money), and trained and qualified personnel are needed.
3. It is difficult or impossible to predict the required volume disk space when deploying a computer system. Consequently:
There are problems of expanding disk capacities - it is quite difficult to get terabyte capacities in the server, especially if the system is already running on existing small-capacity disks - at a minimum, a system shutdown and inefficient financial investments are required.
Inefficient utilization of resources - sometimes you can’t guess which server the data will grow faster. A critically small amount of disk space can be free in the e-mail server, while another unit will use only 20% of the volume of an expensive disk subsystem (for example, SCSI).
4. Low confidentiality of distributed data - it is impossible to control and restrict access in accordance with the security policy of the enterprise. This applies to both access to data on the channels existing for this (local area network) and physical access to media - for example, theft of hard drives and their destruction are not excluded (in order to complicate the business of the organization). Unqualified actions by users and maintenance personnel can be even more harmful. When a company in each office is forced to solve small local security problems, this does not give the desired result.
5. The complexity of managing distributed information flows - any actions that are aimed at changing data in each branch that contains part of the distributed data creates certain problems, ranging from the complexity of synchronizing various databases, versions of developer files to unnecessary duplication of information.
6. Low economic effect of the introduction of "classic" solutions - with the growth of the information network, large amounts of data and an increasingly distributed structure of the enterprise, financial investments are not so effective and often cannot solve the problems that arise.
7. The high costs of the resources used to maintain the efficiency of the entire enterprise information system - from the need to maintain a large staff of qualified personnel to numerous expensive hardware solutions that are designed to solve the problem of volumes and speeds of access to information, coupled with reliable storage and protection from failures.
In light of the above problems, which sooner or later, completely or partially overtake any dynamically developing company, we will try to describe the storage systems - as they should be. Consider typical connection schemes and types of storage systems.
Megabytes / transactions?
If earlier hard disks were inside the computer (server), now they have become cramped and not very reliable there. The simplest solution (developed long ago and used everywhere) is RAID technology.
images \\ RAID \\ 01.jpg
When organizing RAID in any storage systems, in addition to protecting information, we get several undeniable advantages, one of which is the speed of access to information.
From the point of view of the user or software, the speed is determined not only by the system capacity (MB / s), but also by the number of transactions - that is, the number of I / O operations per unit time (IOPS). Logically, a larger number of disks and those performance improvement techniques that a RAID controller provides (such as caching) contribute to IOPS.
If overall throughput is more important for viewing streaming video or organizing a file server, then for the DBMS and any OLTP (online transaction processing) applications, it is the number of transactions that the system is capable of processing that is critical. And with this option, modern hard drives are not so rosy as with growing volumes and, in part, speeds. All these problems are intended to be solved by the storage system itself.
Protection levels
You need to understand that the basis of all storage systems is the practice of protecting information based on RAID technology - without this, any technically advanced storage system will be useless, because the hard drives in this system are the most unreliable component. Organizing disks in RAID is the "lower link", the first echelon of information protection and increased processing speed.
However, in addition to RAID schemes, there is a lower-level data protection implemented “on top” of technologies and solutions embedded in the hard drive itself by its manufacturer. For example, one of the leading storage manufacturers, EMC, has a methodology for additional data integrity analysis at the drive sector level.
Having dealt with RAID, let's move on to the structure of the storage systems themselves. First of all, storage systems are divided according to the type of host (server) connection interfaces used. External connection interfaces are mainly SCSI or FibreChannel, as well as the fairly young iSCSI standard. Also, do not discount small intelligent stores that can even be connected via USB or FireWire. We will not consider rarer (sometimes simply unsuccessful in one way or another) interfaces, such as IBM SSA or interfaces developed for mainframes - for example, FICON / ESCON. Stand alone NAS storage, connected to the Ethernet network. The word “interface” basically means an external connector, but do not forget that the connector does not determine the communication protocol of the two devices. We will dwell on these features a little lower.
images \\ RAID \\ 02.gif
It stands for Small Computer System Interface (read "tell") - a half-duplex parallel interface. In modern storage systems, it is most often represented by a SCSI connector:
images \\ RAID \\ 03.gif
images \\ RAID \\ 04.gif
And a group of SCSI protocols, and more specifically - SCSI-3 Parallel Interface. The difference between SCSI and the familiar IDE is a larger number of devices per channel, a longer cable length, a higher data transfer rate, as well as “exclusive” features like high voltage differential signaling, command quequing and some others — we won’t go into this issue.
If we talk about the main manufacturers of SCSI components, such as SCSI adapters, RAID controllers with SCSI interface, then any specialist will immediately remember two names - Adaptec and LSI Logic. I think this is enough, there have been no revolutions in this market for a long time and probably is not expected.
FiberChannel Interface
Full duplex serial interface. Most often, in modern equipment it is represented by external optical connectors such as LC or SC (LC - smaller in size):
images \\ RAID \\ 05.jpg
images \\ RAID \\ 06.jpg
... and the FibreChannel Protocols (FCP). There are several FibreChannel device switching schemes:
Point-to-point - point-to-point, direct connection of devices to each other:
images \\ RAID \\ 07.gif
Crosspoint switched - connecting devices to the FibreChannel switch (similar to the Ethernet network implementation on the switches):
images \\ RAID \\ 08.gif
Arbitrated loop - FC-AL, loop with arbitration access - all devices are connected to each other in a ring, the circuit is somewhat reminiscent of Token Ring. A switch can also be used - then the physical topology will be implemented according to the “star” scheme, and the logical one - according to the “loop” (or “ring”) scheme:
images \\ RAID \\ 09.gif
Connection according to the FibreChannel Switched scheme is the most common scheme, in terms of FibreChannel such connection is called Fabric - in Russian there is a tracing-paper from it - “factory”. It should be noted that FibreChannel switches are quite advanced devices that are close in complexity to IP-level 3 IP switches. If the switches are interconnected, they operate in a single factory with a pool of settings that are valid for the entire factory at once. Changing some options on one of the switches can lead to a re-switching of the entire factory, not to mention access authorization settings, for example. On the other hand, there are SAN schemes that involve several factories within a single SAN. Thus, a factory can only be called a group of interconnected switches - two or more devices not interconnected, introduced into the SAN to increase fault tolerance, form two or more different factories.
Components that allow combining hosts and storage systems into a single network are commonly referred to as “connectivity”. Connectivity is, of course, duplex connecting cables (usually with an LC interface), switches (switches) and FibreChannel adapters (HBA, Host Base Adapters) - that is, those expansion cards that, when installed in the hosts, allow you to connect the host to the network SAN. HBAs are typically implemented as PCI-X or PCI-Express cards.
images \\ RAID \\ 10.jpg
Do not confuse fiber and fiber - the signal propagation medium can be different. FiberChannel can work on "copper". For example, all FibreChannel hard drives have metal contacts, and the usual switching of devices via copper is not uncommon, they just gradually switch to optical channels as the most promising technology and functional replacement of copper.
ISCSI interface
Usually represented by an external RJ-45 connector for connecting to an Ethernet network and the protocol itself iSCSI (Internet Small Computer System Interface). By the definition of SNIA: “iSCSI is a protocol that is based on TCP / IP and is designed to establish interoperability and manage storage systems, servers and clients.” We’ll dwell on this interface in more detail, if only because each user is able to use iSCSI even on a regular “home” network.
You need to know that iSCSI defines at least the transport protocol for SCSI, which runs on top of TCP, and the technology for encapsulating SCSI commands in an IP-based network. Simply put, iSCSI is a protocol that allows block access to data using SCSI commands sent over a network with a TCP / IP stack. iSCSI appeared as a replacement for FibreChannel and in modern storage systems has several advantages over it - the ability to combine devices over long distances (using existing IP networks), the ability to provide a specified level of QoS (Quality of Service, quality of service), lower cost connectivity. However, the main problem of using iSCSI as a replacement for FibreChannel is the long time delays that occur on the network due to the peculiarities of the TCP / IP stack implementation, which negates one of the important advantages of using storage systems - information access speed and low latency. This is a serious minus.
A small remark about hosts - they can use both regular network cards (then iSCSI stack processing and encapsulation of commands will be done by software), as well as specialized cards supporting technologies similar to TOE (TCP / IP Offload Engines). This technology provides hardware processing of the corresponding part of the iSCSI protocol stack. Software method cheaper, but it loads the server’s central processor more and, in theory, can lead to longer delays than a hardware processor. With the current speed of Ethernet networks at 1 Gbit / s, it can be assumed that iSCSI will work exactly twice as slow as the FibreChannel at a speed of 2 Gbit, but in real use the difference will be even more noticeable.
In addition to those already discussed, we briefly mention a couple of protocols that are more rare and are designed to provide additional services to existing storage area networks (SANs):
FCIP (Fiber Channel over IP) - A tunneling protocol built on TCP / IP and designed to connect geographically dispersed SANs through a standard IP environment. For example, you can combine two SANs into one over the Internet. This is achieved by using an FCIP gateway that is transparent to all devices in the SAN.
iFCP (Internet Fiber Channel Protocol) - A protocol that allows you to combine devices with FC interfaces via IP networks. An important difference from FCIP is that it is possible to combine FC devices through an IP network, which allows for a different pair of connections to have a different level of QoS, which is not possible when tunneling through FCIP.
We briefly examined the physical interfaces, protocols, and switching types for storage systems, without stopping at listing all possible options. Now let's try to imagine what parameters characterize data storage systems?
Main hardware parameters of storage
Some of them were listed above - these are the type of external connection interfaces and types internal drives (hard drives). The next parameter, which makes sense to consider after the two of the above when choosing a disk storage system, is its reliability. Reliability can be assessed not by the banal running hours of failure of any individual components (the fact that this time is approximately equal for all manufacturers), but by the internal architecture. A “regular” storage system often “externally” is a disk shelf (for mounting in a 19-inch cabinet) with hard drives, external interfaces for connecting hosts, several power supplies. Inside, usually everything that provides the storage system is installed - processor units, disk controllers, input-output ports, cache memory and so on. Typically, the rack is managed from the command line or via the web interface, the initial configuration often requires a serial connection. The user can “split” the disks in the system into groups and combine them into RAID (of different levels), the resulting disk space is divided into one or more logical units (LUNs), to which hosts (servers) have access and “see” them as local hard drives. The number of RAID groups, LUNs, the logic of the cache, the availability of LUNs to specific servers and everything else is configured by the system administrator. Typically, storage systems are designed to connect to them not one, but several (up to hundreds, in theory) servers - therefore, such a system should have high performance, a flexible control and monitoring system, and well-thought-out data protection tools. Data protection is provided in many ways, the easiest of which you already know - the combination of disks in RAID. However, the data must also be constantly accessible - after all, stopping one data storage system central to the enterprise can cause significant losses. The more systems store data on the storage system, the more reliable access to the system must be provided - because in the event of an accident, the storage system stops working immediately on all servers that store data there. High rack availability is ensured by complete internal duplication of all system components - access paths to the rack (FibreChannel ports), processor modules, cache memory, power supplies, etc. We will try to explain the principle of 100% redundancy (duplication) with the following figure:
images \\ RAID \\ 11.gif
1. The controller (processor module) of the storage system, including:
* Central processor (or processors) - usually on the system runs special software that acts as the "operating system";
* interfaces for switching with hard disks - in our case, these are boards that provide connection of FibreChannel disks according to the arbitration access loop scheme (FC-AL);
* cache memory;
* FibreChannel external port controllers
2. The external interface of FC; as we see, there are 2 of them for each processor module;
3. Hard drives - the capacity is expanded with additional disk shelves;
4. Cache memory in such a scheme is usually mirrored so as not to lose the data stored there when any module fails.
Regarding the hardware, disk racks can have different interfaces for connecting hosts, different interfaces of hard drives, different connection schemes for additional shelves, which serve to increase the number of disks in the system, as well as other purely “iron parameters”.
Storage Software
Naturally, the hardware power of the storage systems must be somehow managed, and the storage systems themselves are simply obliged to provide a level of service and functionality that is not available in conventional server-client schemes. If you look at the figure “Structural diagram of a data storage system”, it becomes clear that when the server is connected directly to the rack in two ways, they must be connected to the FC ports of various processor modules in order for the server to continue to work if the entire processor module fails immediately. Naturally, to use multipathing, support for this functionality should be provided by hardware and software at all levels involved in data transfer. Of course, full backup without monitoring and alerting does not make sense - therefore, all serious storage systems have such capabilities. For example, notification of any critical events can occur by various means - an e-mail alert, an automatic modem call to the technical support center, a message to a pager (now more relevant than SMS), SNMP mechanisms, and more.
Well, and as we already mentioned, there are powerful controls for all this magnificence. Usually this is a web-based interface, a console, the ability to write scripts and integrate control into external software packages. About the mechanisms that provide high performance storage, we only mention briefly - non-blocking architecture with several internal buses and large quantity hard drives, powerful central processors, specialized control system (OS), a large amount of cache memory, many external I / O interfaces.
The services provided by storage systems are typically determined by software running on the disk rack itself. Almost always, these are complex software packages purchased under separate licenses that are not included in the cost of storage itself. Immediately mention the familiar software for providing multipathing - here it just functions on the hosts, and not on the rack itself.
The next most popular solution is software for creating instant and complete copies of data. Different manufacturers have different names for their software products and mechanisms for creating these copies. To summarize, we can manipulate the words snapshot and clone. A clone is made using the disk rack inside the rack itself - this is a complete internal copy of the data. The scope of application is quite wide - from backup to creating a “test version” of the source data, for example, for risky upgrades in which there is no certainty and which is unsafe to use on current data. Anyone who closely followed all the charms of storage that we were analyzing here would ask - why do you need a data backup inside the rack if it has such high reliability? The answer to this question on the surface is that no one is immune from human errors. The data is stored reliably, but if the operator did something wrong, for example, deleted the desired table in the database, no hardware tricks will save him. Data cloning is usually done at the LUN level. More interesting functionality is provided by the snapshot mechanism. To some extent, we get all the charms of a full internal copy of the data (clone), while not taking up 100% of the amount of data copied inside the rack itself, because such a volume is not always available to us. In fact, snapshot is an instant “snapshot” of data that does not take time and processor resources of storage.
Of course, one cannot fail to mention the data replication software, which is often called mirroring. This is a mechanism for synchronous or asynchronous replication (duplication) of information from one storage system to one or more remote storage systems. Replication is possible through various channels - for example, racks with FibreChannel interfaces can be replicated to another storage system asynchronously, via the Internet and over long distances. This solution provides reliable information storage and protection against disasters.
In addition to all of the above, there are a large number of other software mechanisms for data manipulation ...
DAS & NAS & SAN
After getting acquainted with the data storage systems themselves, the principles of their construction, the capabilities provided by them and the functioning protocols, it's time to try to combine the acquired knowledge into a working scheme. Let's try to consider the types of storage systems and the topology of their connection to a single working infrastructure.
Devices DAS (Direct Attached Storage) - storage systems that connect directly to the server. This includes both the simplest SCSI systems connected to the server's SCSI / RAID controller, and FibreChannel devices connected directly to the server, although they are designed for SANs. In this case, the DAS topology is a degenerate SAN (storage area network):
images \\ RAID \\ 12.gif
In this scheme, one of the servers has access to data stored on the storage system. Clients access data by accessing this server through the network. That is, the server has block access to data on the storage system, and clients already use file access - this concept is very important for understanding. The disadvantages of such a topology are obvious:
* Low reliability - in case of network problems or server crashes, data becomes inaccessible to everyone at once.
* High latency due to the processing of all requests by one server and the transport used (most often - IP).
* High network load, often defining scalability limits by adding clients.
* Poor manageability - the entire capacity is available to one server, which reduces the flexibility of data distribution.
* Low utilization of resources - it is difficult to predict the required data volumes, some DAS devices in an organization may have an excess of capacity (disks), others may lack it - redistribution is often impossible or time-consuming.
Devices NAS (Network Attached Storage) - storage devices connected directly to the network. Unlike other systems, NAS provides file access to data and nothing else. NAS devices are a combination of the storage system and the server to which it is connected. In its simplest form, a regular network server providing file resources is a NAS device:
images \\ RAID \\ 13.gif
All the disadvantages of such a scheme are similar to the DAS topology, with some exceptions. Of the minuses that have been added, we note an increased, and often significantly, cost - however, the cost is proportional to functionality, and here already often there is "something to pay for". NAS devices can be the simplest “boxes” with one ethernet port and two hard drives in RAID1, allowing access to files using only one CIFS (Common Internet File System) protocol to huge systems in which hundreds of hard drives can be installed, and file access provided by a dozen specialized servers inside the NAS system. The number of external Ethernet ports can reach many tens, and the capacity of the stored data is several hundred terabytes (for example, EMC Celerra CNS). Reliability and performance of such models can bypass many SAN midrange devices. Interestingly, NAS devices can be part of a SAN network and do not have their own drives, but only provide file access to data stored on block storage devices. In this case, the NAS assumes the function of a powerful specialized server, and the SAN assumes the storage device, that is, we get the DAS topology, composed of NAS and SAN components.
NAS devices are very good in a heterogeneous environment where you need fast file access to data for many clients at the same time. It also provides excellent storage reliability and system management flexibility coupled with ease of maintenance. We will not dwell on reliability - this aspect of storage is discussed above. As for a heterogeneous environment, access to files within a single NAS system can be obtained via TCP / IP, CIFS, NFS, FTP, TFTP and others, including the ability to work as a NAS iSCSI-target, which ensures operation with different operating systems, installed on hosts. As for ease of maintenance and management flexibility, these capabilities are provided by a specialized OS, which is difficult to disable and does not need to be maintained, as well as the ease of delimiting file permissions. For example, it is possible to work in a Windows Active Directory environment with support for the required functionality - it can be LDAP, Kerberos Authentication, Dynamic DNS, ACLs, quotas, Group Policy Objects and SID history. Since access is provided to files, and their names may contain symbols of various languages, many NAS provide support for UTF-8, Unicode encodings. The choice of NAS should be approached even more carefully than to DAS devices, because such equipment may not support the services you need, for example, Encrypting File Systems (EFS) from Microsoft and IPSec. By the way, one can notice that NASs are much less widespread than SAN devices, but the percentage of such systems is still constantly, albeit slowly, growing - mainly due to the crowding out of DAS.
Devices to connect to SAN (Storage Area Network) - devices for connecting to a data storage network. A storage area network (SAN) should not be confused with a local area network - these are different networks. Most often, the SAN is based on the FibreChannel protocol stack and in the simplest case consists of storage systems, switches and servers connected by optical communication channels. In the figure we see a highly reliable infrastructure in which servers are connected simultaneously to the local network (left) and to the storage network (right):
images \\ RAID \\ 14.gif
After a fairly detailed discussion of the devices and their principles of operation, it will be quite easy for us to understand the SAN topology. In the figure, we see a single storage system for the entire infrastructure, to which two servers are connected. Servers have redundant access paths - each has two HBAs (or one dual-port, which reduces fault tolerance). The storage device has 4 ports by which it is connected to 2 switches. Assuming that there are two redundant processor modules inside, it is easy to guess that the best connection scheme is when each switch is connected to both the first and second processor modules. Such a scheme provides access to any data located on the storage system in the event of failure of any processor module, switch, or access path. We have already studied the reliability of storage systems, two switches and two factories further increase the availability of the topology, so if one of the switching units suddenly fails due to a failure or an administrator error, the second will function normally, because these two devices are not connected.
The server connection shown is called a high availability connection, although an even larger number of HBAs can be installed in the server if necessary. Physically, each server has only two connections in the SAN, but logically, the storage system is accessible through four paths - each HBA provides access to two connection points on the storage system, separately for each processor module (this feature provides a double connection of the switch to the storage system). In this diagram, the most unreliable device is the server. Two switches provide reliability of the order of 99.99%, but the server may fail for various reasons. If highly reliable operation of the entire system is required, the servers are combined into a cluster, the above diagram does not require any hardware addition to organize such work and is considered the reference scheme of the SAN organization. The simplest case is the servers connected in a single way through one switch to the storage system. However, the storage system with two processor modules must be connected to the switch with at least one channel for each module - the remaining ports can be used for direct connection of servers to the storage system, which is sometimes necessary. And do not forget that the SAN can be built not only on the basis of FibreChannel, but also on the basis of iSCSI protocol - at the same time, you can use only standard ethernet devices for switching, which reduces the cost of the system, but has a number of additional disadvantages (specified in the section on iSCSI ) Also interesting is the ability to load servers from the storage system - it is not even necessary to have internal hard drives in the server. Thus, the task of storing any data is finally removed from the servers. In theory, a specialized server can be turned into an ordinary number crusher without any drives, the defining blocks of which are central processors, memory, as well as interfaces to interact with the outside world, such as Ethernet and FibreChannel ports. Some semblance of such devices are modern blade servers.
I would like to note that the devices that can be connected to the SAN are not limited only to disk storage systems - they can be disk libraries, tape libraries (streamers), devices for storing data on optical disks (CD / DVD, etc.) and many others.
Of the minuses of SAN, we note only the high cost of its components, but the advantages are undeniable:
* High reliability of access to data located on external storage systems. Independence of SAN topology from used storage systems and servers.
* Centralized data storage (reliability, security).
* Convenient centralized management of switching and data.
* Transfer intensive I / O traffic to a separate network, offloading LAN.
* High speed and low latency.
* Scalability and flexibility logical structure San
* Geographically, SAN sizes, unlike classic DASs, are virtually unlimited.
* Ability to quickly distribute resources between servers.
* Ability to build fault-tolerant cluster solutions at no additional cost based on the existing SAN.
* Simple backup scheme - all data is in one place.
* The presence of additional features and services (snapshots, remote replication).
* High security SAN.
Finally
I think we have adequately covered the main range of issues related to modern storage systems. Let's hope that such devices will even more rapidly develop functionally, and the number of data management mechanisms will only grow.
In conclusion, we can say that NAS and SAN solutions are currently experiencing a real boom. The number of manufacturers and the variety of solutions are increasing, and the technical literacy of consumers is growing. We can safely assume that in the near future in almost every computing environment, one or another data storage system will appear.
Any data appears before us in the form of information. The meaning of the work of any computing devices is information processing. IN lately its growth volumes are sometimes scary, so storage systems and specialized software will undoubtedly be the most sought-after IT products in the coming years.
What is it?
Data storage network, or Storage Area Network is a system consisting of the actual storage devices - disk, or RAID - arrays, tape libraries and other things, the data transmission medium and the servers connected to it. It is usually used by large enough companies with well-developed IT infrastructure for reliable data storage and high-speed access to them.
Simplified, storage is a system that allows you to distribute reliable servers fast drives variable capacitance with different devices data storage.
A bit of theory.
The server can be connected to the data warehouse in several ways.
The first and simplest one is DAS, Direct Attached Storage (direct connection), we put drives into the server, or an array into the server adapter, and we get a lot of gigabytes of disk space with relatively quick access, and when using a RAID array - sufficient reliability, although spears on the topic of reliability have been around for a long time.
However, this use of disk space is not optimal - on one server the place runs out, on the other there is still a lot of it. The solution to this problem is NAS, Network Attached Storage (network-attached storage). However, with all the advantages of this solution - flexibility and centralized management - there is one significant drawback - the speed of access, the network of 10 gigabits is not yet implemented in all organizations. And we are approaching a storage network.
The main difference between a SAN and a NAS (in addition to the letter order in abbreviations) is how the connected resources are seen on the server. If the NAS resources are connected to the NFS or SMB protocols, in the SAN we get a connection to the disk, with which we can work at the level of block I / O operations, which is much faster than a network connection (plus an array controller with a large cache adds speed to many operations).
Using SAN, we combine the advantages of DAS - speed and simplicity, and NAS - flexibility and controllability. Plus, we get the ability to scale storage systems until there is enough money, while simultaneously killing several more birds with one stone, which are not immediately visible:
* remove restrictions on the connection range of SCSI devices, which are usually limited to a wire of 12 meters,
* reduce backup time,
* we can boot from SAN,
* in case of refusal from NAS we unload a network,
* we get a high input-output speed due to optimization on the storage system side,
* get the opportunity to connect multiple servers to one resource, then it gives us the following two birds with one stone:
o make full use of the capabilities of VMWare - for example VMotion (virtual machine migration between physical machines) and others like them,
o we can build failover clusters and organize geographically distributed networks.
What does it give?
In addition to developing the budget for optimizing the storage system, we get, in addition to what I wrote above:
* increase in productivity, load balancing and high availability of storage systems due to several ways to access arrays;
* savings on disks by optimizing the location of information;
* accelerated recovery from failures - you can create temporary resources, deploy backup to them and connect the servers to them, and restore information yourself without haste, or transfer resources to other servers and calmly deal with dead iron;
* Reduced backup time - thanks to the high transfer speed, you can back up to the tape library faster, or even take a snapshot (snapshot) from the file system and safely archive it;
* disk space on demand - when we need it - you can always add a couple of shelves to the storage system.
* reduce the cost of storing a megabyte of information - of course, there is a certain threshold from which these systems are cost-effective.
* A reliable place to store mission critical and business critical data (without which the organization cannot exist and function normally).
* I want to mention VMWare separately - all the chips like migrating virtual machines from server to server and other goodies are available only on the SAN.
What does it consist of?
As I wrote above - SHD consists of storage devices, transmission media and connected servers. Let's consider in order:
Data storage systems usually consist of hard drives and controllers, in a self-respecting system, usually only 2 - 2 controllers, 2 paths to each drive, 2 interfaces, 2 power supplies, 2 administrators. Among the most respected system manufacturers, mention should be made of HP, IBM, EMC, and Hitachi. Here I will quote one representative of EMC at the seminar - “HP makes excellent printers. Well, let her make them! ”I suspect that HP also loves EMC. Competition between manufacturers is serious, however, as elsewhere. The consequences of competition are sometimes sane prices per megabyte of storage system and problems with compatibility and support of competitor standards, especially for old equipment.
Data transfer medium. Typically, SANs are built on optics, which currently gives a speed of 4, sometimes 8 gigabits per channel. When building, specialized hubs were used before, now there are more switches, mainly from Qlogic, Brocade, McData and Cisco (I have never seen the last two on the sites). Cables are used traditional for optical networks - single-mode and multi-mode, single-mode longer.
Inside, FCP is used - Fiber Channel Protocol, a transport protocol. Typically, classic SCSI runs inside it, and FCP provides addressing and delivery. There is an option with a connection via a regular network and iSCSI, but it usually uses (and heavily loads) a local, and not a dedicated network for data transfer, and requires adapters with iSCSI support, well, the speed is slower than in optics.
There is also a smart word topology, which is found in all textbooks on SAN. There are several topologies, the simplest option is point to point, we connect 2 systems. This is not DAS, but a spherical horse in vacuum is the simplest version of SAN. Next comes the controlled loop (FC-AL), it works on the principle of “pass on” - the transmitter of each device is connected to the receiver of the subsequent one, the devices are closed in a ring. Long chains tend to initialize for a long time.
Well, the final option is a switched fabric (Fabric), it is created using switches. The structure of connections is built depending on the number of connected ports, as in the construction of a local network. The basic construction principle is that all paths and connections are duplicated. This means that there are at least 2 different paths to each device on the network. Here, the word topology is also used, in the sense of organizing a device connection diagram and connecting switches. In this case, as a rule, switches are configured so that the servers do not see anything other than the resources intended for them. This is achieved by creating virtual networks and is called zoning, the closest analogy is VLAN. Each device on the network is assigned an analog MAC address on the Ethernet network, it is called WWN - World Wide Name. It is assigned to each interface and each resource (LUN) of storage systems. Arrays and switches can distinguish between WWN access for servers.
Server Connect to storage via HBA - Host Bus Adapters. By analogy with network cards, there are one-, two-, and four-port adapters. The best dog breeders recommend installing 2 adapters per server, this allows both load balancing and reliability.
And then resources are cut into the storage systems, they are the LUNs for each server and a place is left in the reserve, everything is turned on, the system installers prescribe the topology, catch glitches in the configuration of switches and access, everything starts and everyone lives happily ever after *
I specifically do not touch on different types of ports in the optical network, whoever needs it - he already knows or reads, who does not need it - just hammer his head. But as usual, if the port type is incorrectly set, nothing will work.
From experience.
Usually, when creating a SAN, arrays with several types of disks are ordered: FC for high-speed applications, and SATA or SAS for not very fast ones. Thus, 2 disk groups with different megabyte cost are obtained - expensive and fast, and slow and sad cheap. Usually, all databases and other applications with active and fast I / O are hung on the fast one, while file resources and everything else are hung on the slow one.
If a SAN is created from scratch, it makes sense to build it on the basis of solutions from one manufacturer. The fact is that, despite the declared compliance with standards, there are underwater rakes of the equipment compatibility problem, and not the fact that part of the equipment will work with each other without dancing with a tambourine and consulting with manufacturers. Usually, to tackle such problems, it is easier to call an integrator and give him money than to communicate with manufacturers switching arrows.
If the SAN is created on the basis of the existing infrastructure, everything can be complicated, especially if there are old SCSI arrays and an old technology zoo from different manufacturers. In this case, it makes sense to call for help from the terrible beast of an integrator who will unravel compatibility problems and make a third villa in the Canary Islands.
Often when creating storage systems, firms do not order manufacturer support for the system. This is usually justified if the company has a staff of competent competent admins (who have already called me a teapot 100 times) and a fair amount of capital, which makes it possible to purchase spare parts in the required quantities. However, competent administrators are usually lured by integrators (I saw it myself), but they don’t allocate money for the purchase, and after failures, a circus begins with the cries of “I'll fire everyone!” Instead of a call to support and an engineer with a spare part.
Support usually comes down to replacing dead disks and controllers, and to adding disk shelves and new servers to the system. A lot of trouble happens after a sudden prevention of the system by local specialists, especially after a complete shutdown and disassembly-assembly of the system (and this happens).
About VMWare. As far as I know (virtualization specialists correct me), only VMWare and Hyper-V have functionality that allows you to transfer virtual machines between physical servers on the fly. And for its implementation, it is required that all servers between which the virtual machine moves are connected to the same disk.
About clusters. Similar to the case with VMWare, the systems I know of building failover clusters (Sun Cluster, Veritas Cluster Server) that I know require storage connected to all systems.
While writing an article - they asked me - in which RAIDs do drives usually combine?
In my practice, they usually made either RAID 1 + 0 on each disk shelf with FC disks, leaving 1 spare disk (Hot Spare) and cut LUNs from this piece for tasks, or did RAID5 from slow disks, again leaving 1 disk to replace. But here the question is complex, and usually the way to organize disks in an array is selected for each situation and justified. The same EMC, for example, goes even further, and they have additional array settings for applications that work with it (for example, under OLTP, OLAP). I didn’t dig so deeply with the other vendors, but I guess everyone has a fine-tuning.
* before the first major failure, after which support is usually bought from the manufacturer or supplier of the system.
Since there are no comments in the sandbox, I'll post it on my personal blog.
Tags: Add Tags
If Servers are universal devices that perform in most cases
- either an application server function (when executed on the server special programs, and there are intensive calculations)
- either a file server function (i.e. a certain place for centralized storage of data files)
then SHD (Data Storage Systems) - devices specially designed to perform such server functions as data storage.
The need to purchase storage
usually arises in sufficiently mature enterprises, i.e. those who think about how
- store and manage information, the company's most valuable asset
- ensure business continuity and protection against data loss
- increase adaptability of IT infrastructure
Storage and virtualization
Competition forces SMEs to work more efficiently, without downtime and with high efficiency. Change of production models, tariff plans, types of services is happening more and more often. The whole business of modern companies is “tied” to information technology. Business needs change quickly, and instantly affect IT - requirements for reliability and adaptability of IT infrastructure are growing. Virtualization provides these capabilities, but it requires low-cost, easy-to-maintain storage systems.
Storage classification by connection type
Das. The first disk arrays connected to the servers via SCSI. At the same time, one server could work with only one disk array. This is a direct storage connection (DAS - Direct Attached Storage).
NAS. For a more flexible organization of the structure of the data center - so that every user can use any storage system - it is necessary to connect the storage system to the local network. This is NAS - Network Attached Storage). But the data exchange between the server and the storage system is many times more intense than between the client and the server, so in this version there were objective difficulties associated with the bandwidth of the Ethernet network. And from a security point of view, it’s not entirely correct to show storage systems in a shared network.
San. But you can create your own, separate, high-speed network between servers and storage. Such a network was called SAN (Storage Area Network). Performance is ensured by the fact that the physical transmission medium there is optics. Special adapters (HBA) and optical FC switches provide data transmission at speeds of 4 and 8Gbit / s. The reliability of such a network was enhanced by redundancy (duplication) of channels (adapters, switches). The main disadvantage is the high price.
iSCSI. With the advent of low-cost Ethernet technologies 1Gbit / s and 10Gbit / s, optics with a transmission speed of 4Gbit / s does not look so attractive, especially considering the price. Therefore, iSCSI (Internet Small Computer System Interface) protocol is increasingly being used as a SAN environment. An iSCSI SAN can be built on any fast enough physical basis that supports IP.
Classification of Storage Systems by Application:
| the class | description |
| personal |
Most often they are a regular 3.5 "or 2.5" or 1.8 " hDDplaced in a special case and equipped with USB and / or FireWire 1394 and / or Ethernet, and / or eSATA interfaces. |
small workgroup  |
Usually this is a stationary or portable device, in which you can install several (most often from 2 to 5) SATA hard drives, with or without hot-swappability, having an Ethernet interface. Disks can be organized into RAID arrays of various levels to achieve high reliability of storage and access speed. The storage system has a specialized OS, usually based on Linux, and allows you to differentiate the level of access by user name and password, organize quotas for disk space, etc. |
|
workgroup |
The device is usually mounted in a 19 "rack (rack-mount) in which you can install 12-24 SATA or SAS hot-swappable HotSwap drives. It has an external Ethernet and / or iSCSI interface. The drives are organized in RAID arrays to achieve high reliability of storage and access speed. Storage comes with specialized software that allows you to differentiate access levels, organize quotas for disk space, organize BackUp (back up information), etc. Such storage systems are suitable for medium and large enterprises, and are used in conjunction with one or more servers. |
enterprise   |
A stationary device or device mounted in a 19 "rack (rack-mount) in which you can install up to hundreds of hard drives. In addition to the previous class, storage systems may have the ability to build, upgrade, and replace components without stopping the monitoring system. Software can support snapshots and other advanced features. These storage systems are suitable for large enterprises and provide increased reliability, speed and protection of critical data. |
|
high-end enterprise |
In addition to the previous class, storage can support thousands of hard drives. |


The history of the issue.
The first servers combined all functions (like computers) in one package - both computing (application server) and data storage (file server). But as the demand for applications in computing power grows on the one hand, and as the amount of processed data grows on the other hand, it has become simply inconvenient to place everything in one package. It turned out to be more effective to take out disk arrays in separate cases. But here the question arose of connecting the disk array to the server. The first disk arrays connected to the servers via SCSI. But in this case, one server could work with only one disk array. The people wanted a more flexible organization of the structure of the data center - so that any server could use any storage system. Connecting all devices directly to the local network and organizing data exchange via Ethernet is, of course, a simple and universal solution. But the exchange of data between servers and storage is many times more intense than between clients and servers, therefore, in this version (NAS - see below) there were objective difficulties associated with the bandwidth of the Ethernet network. There was an idea to create your own separate high-speed network between servers and storage. Such a network was called a SAN (see below). It is similar to Ethernet, only the physical transmission medium there is optics. There are also adapters (HBAs) that are installed in servers and switches (optical). Standards for data transmission speed for optics - 4Gbit / s. With the advent of Ethernet technologies 1Gbit / s and 10Gbit / s, as well as iSCSI protocol, Ethernet is increasingly being used as a SAN environment.
So, issue number 1 - "Data Storage Systems".
Data storage systems.
In English they are called in one word - storage, which is very convenient. But this word is translated rather clumsily into Russian - “repository”. Often, on the slang of “IT Schnicks,” they use the word “store” in Russian transcription, or the word “custodian,” but this is already quite bad. Therefore, we will use the term “storage systems”, abbreviated as SHD, or simply “storage systems”.
Storage devices include any device for recording data: the so-called. "Flash drives", compact discs (CD, DVD, ZIP), tape drives (Tape), hard disks (Hard disk, they are also called “Winchesters” in the old fashion, since their first models resembled a clip with cartridges of the same name rifle of the 19th century), etc. Hard disks are used not only inside computers, but also as external USB devices for recording information, and even for example, one of the first iPods was a small 1.8-inch hard drive with headphone output and a built-in screen.
Recently, the so-called. “Solid-state” SSD storage systems (Solid State Disk, or Solid State Drive), which are similar in principle to the “flash drive” for a camera or smartphone, only have a controller and a larger amount of stored data. Unlike hard driveThe SSD has no mechanically moving parts. So far, the prices of such storage systems are quite high, but are rapidly declining.
All these are consumer devices, and among industrial systems it is necessary to single out, first of all, hardware storage systems: arrays of hard drives, the so-called RAID controllers for them, tape storage systems for long-term storage data. In addition, there is a separate class: controllers for storage systems, for managing data backup, creating “snapshots” in the storage system for their subsequent recovery, data replication, etc.). Storage systems also include network devices (HBA, Fiber Channel Switches, FC / SAS cables, etc.). And finally, large-scale solutions have been developed for data storage, archiving, data recovery and disaster recovery.
Where does the data to be stored come from? From us, loved ones, users, from application programs, e-mail, as well as from various equipment - file servers, and database servers. In addition, the supplier a large number data - the so-called M2M devices (Machine-to-Machine communication) - all kinds of sensors, sensors, cameras, etc.
By the frequency of use of stored data, storage systems can be divided into short-term storage systems (online storage), medium-term storage (near-line storage) and long-term storage systems (offline storage).
The first include the hard drive (or SSD) of any personal computer. The second and third are external DAS (Direct Attached Storage) storage systems, which can be an array of external disks (Disk Array) with respect to the computer. They, in turn, can also be subdivided into “just an array of disks” JBOD (Just a Bunch Of Disks) and an array with an iDAS (intelligent disk array storage) controller.
External storage systems come in three types of DAS (Direct Attached Storage), SAN (Storage Area Network) and NAS (Network attached Storage). Unfortunately, even many experienced IT employees cannot explain the difference between SAN and NAS, saying that once there was this difference, but now it supposedly no longer exists. In fact, there is a significant difference (see Fig. 1).
Figure 1. The difference between SAN and NAS.
In a SAN, the servers themselves are actually connected to the storage system through the SAN storage area network. In the case of NAS, network servers are connected via LAN to a shared file system in RAID.
Basic storage connectivity protocols
SCSI protocol (Small Computer System Interface), pronounced "Squeeze", a protocol developed in the mid-80s to connect external devices to mini-mini-computers. Its SCSI-3 version is the basis for all storage communication protocols and uses a common SCSI command system. Its main advantages: independence from the server used, the possibility of parallel operation of several devices, high data transfer speed. Disadvantages: limited number of connected devices, the range of the connection is very limited.
FC protocol(Fiber Channel), an internal protocol between the server and shared storage, controller, disks. It is a widely used serial communication protocol operating at 4 or 8 Gigabits per second (Gbps) speeds. It, as its name implies, works through fiber, but it can also work on copper. Fiber Channel is the primary protocol for FC SAN storage systems.
ISCSI protocol(Internet Small Computer System Interface), a standard protocol for transferring data blocks over the well-known TCP / IP protocol i.e. SCSI over IP iSCSI can be regarded as a high-speed, low-cost solution for remotely connected storage systems over the Internet. iSCSI encapsulates SCSI commands in TCP / IP packets for transmission over an IP network.
SAS Protocol(Serial Attached SCSI). SAS uses serial data transfer and is compatible with SATA hard drives. Currently, SAS can transmit data at 3Gpbs or 6Gpbs, and supports full duplex mode, i.e. can transmit data in both directions at the same speed.
Types of storage systems.
Three main types of storage systems can be distinguished:
- DAS (Direct Attached Storage)
- NAS (Network attached Storage)
- SAN (Storage Area Network)
Storage systems with direct connection of DAS disks were developed at the end
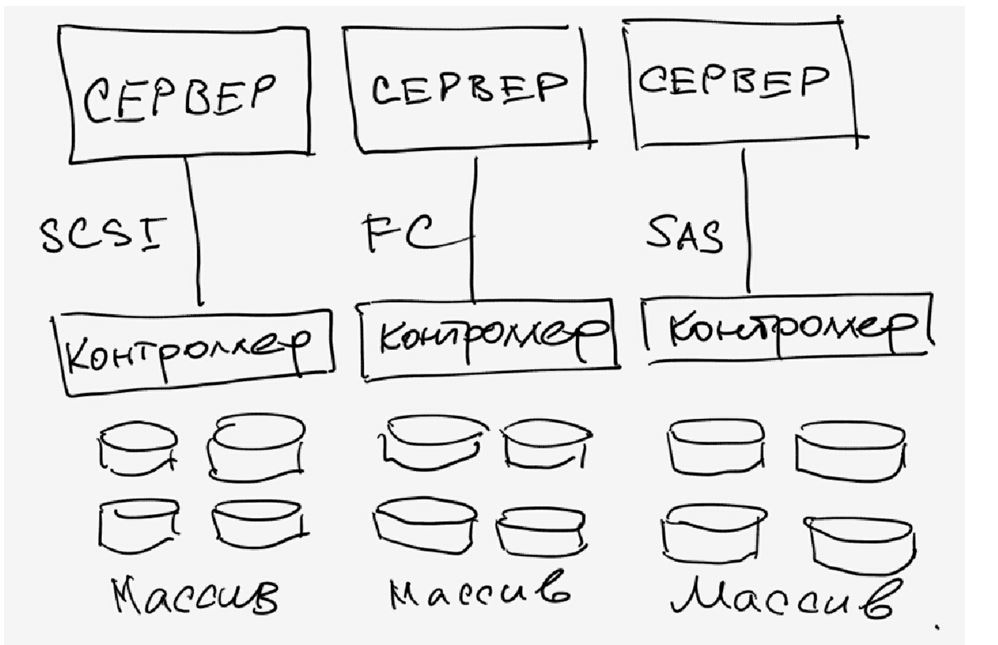
Figure 2. DAS
70s, due to the explosive increase in user data, which simply could not physically fit in the internal long-term memory of computers (for young people, we note that we are not talking about staff there, they were not there then, but large computers, the so-called mainframes). The data transfer rate in the DAS was not very low, from 20 to 80 Mbps, but it was enough for the then needs.
SHD with network connection NAS appeared in the early 90s. The reason was the rapid development of networks and critical requirements for sharing large amounts of data within the enterprise or operator network. The NAS used a special network file system CIFS (Windows) or NFS (Linux), so different servers of different users could read the same file from the NAS at the same time. The data transfer speed was already higher: 1 - 10Gbps.

Figure 3. NAS
In the mid-90s, networks for connecting FC SAN storage devices appeared. Their development was caused by the need to organize data scattered across the network. A single storage device in a SAN can be divided into several small nodes called LUNs (Logical Unit Number), each of which belongs to one server. Data transfer rate increased to 2-8 Gbps. Such storage systems could provide data loss protection technologies (snapshot, backup).
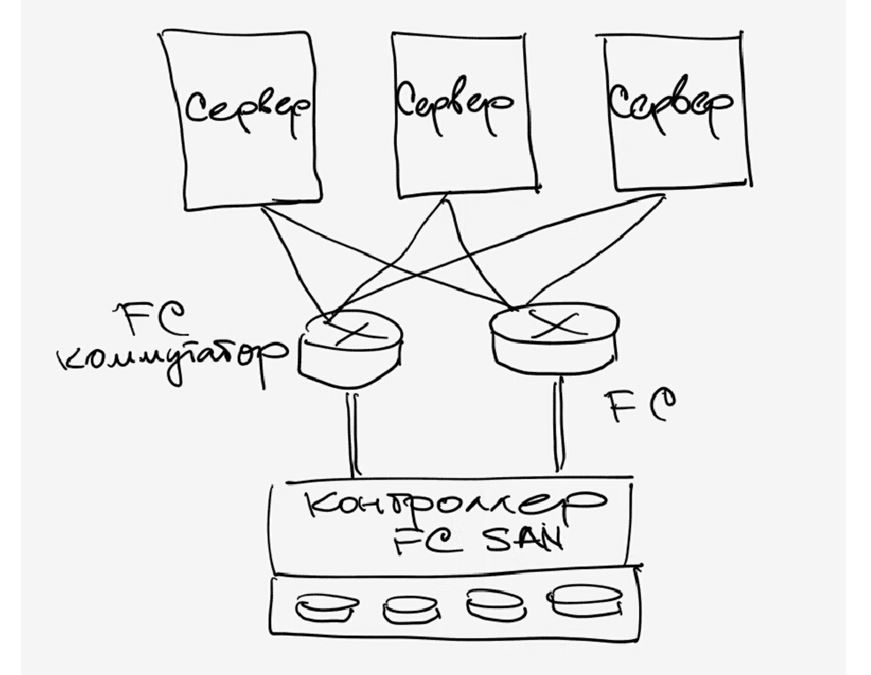
Figure 4. FC SAN
Another type of SAN is IP SAN (IP Storage Area Network), developed in the early 2000s. FC SAN systems were expensive, difficult to manage, and IP networks were at the peak of development, which is why this standard appeared. Storage connected to servers using an iSCSI controller through IP switches. Data transfer rate: 1 - 10 Gbit / s.
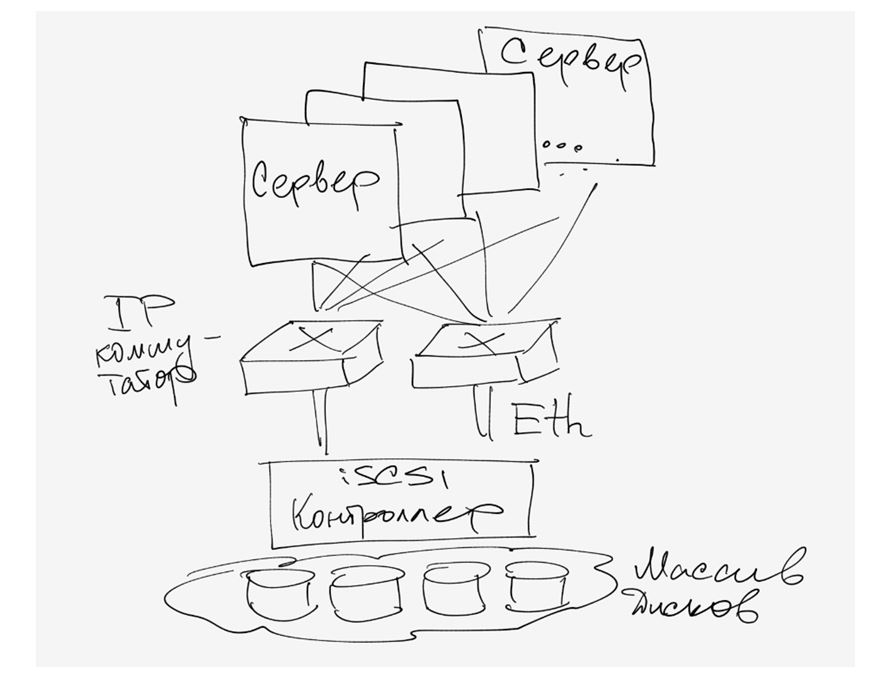
Fig. 5. IP SAN.
The table shows some comparative characteristics all storage systems reviewed:
| Das | NAS | San | ||
| FC SAN | IP SAN | |||
| Gear type | SCSI, FC, SAS | IP | FC | IP |
| Data type | Data block | File | Data block | Data block |
| Typical application | Any | File server | Database | CCTV |
| Advantage | Ease of understanding Superior Compatibility |
Easy installation, low cost | Good scalability | Good scalability |
| disadvantages | Difficulty management. Inefficient use of resources. Poor scalability |
Slow performance. Not applicable for some applications. |
High price. Configuration complexity |
Low productivity |
Briefly, SANs are designed to transfer massive data blocks to storage, while NASs provide file-level access to data. By combining SAN + NAS, you can get a high degree of data integration, high-performance access and file sharing. Such systems are called unified storage - "unified storage systems."
Unified Storage Systems:network storage architecture that supports both file-based NAS and block-oriented SAN. Such systems were developed in the early 2000s in order to solve the problems of administration and the high total cost of ownership of separate systems in one enterprise. Such a storage system supports almost all protocols: FC, iSCSI, FCoE, NFS, CIFS.
Hard disks
All hard drives can be divided into two main types: HDD (Hard Disk Drive, which, in fact, translates as “hard drive”) and SSD (Solid State Drive, - the so-called “solid-state drive”). That is, both drives are hard drives. What, then, is a “soft disk”, are there such a thing? Yes, in the past there were called “floppy disks” (as they were called because of the characteristic “popping” sound in the drive during operation). Drives for them can still be seen in the system blocks of old computers that have been preserved in some government agencies. However, with all the desire, such magnetic disks can hardly be attributed to storage systems. These were some analogues of the current "flash drives".
The difference between HDD and SSD is that the HDD has several coaxial magnetic disks inside and complex mechanics that move the magnetic read-write heads, and the SSD does not have mechanically moving parts, and is, in fact, just a chip pressed into plastic. Therefore, to call “HDDs” only HDD, strictly speaking, is incorrect.
Hard drives can be classified by the following parameters:
- Design: HDD, SSD;
- HDD diameter in inches: 5.25, 3.5, 2.5, 1.8 inches;
- Interface: ATA / IDE, SATA / NL SAS, SCSI, SAS, FC
- To a class of use: individual (desktop class), corporate (entreprenesie class).
| SATA | SAS | NL-SAS | SSD | |
| Rotational Speed \u200b\u200b(RPM) | 7200 | 15000/10000 | 7200 | NA |
| Typical Capacity (TB) | 1T / 2T / 3T | 0.3T / 0.6T / 0.9T | 2T / 3T / 4T | 0.1T / 0.2T / 0.4T |
| MTBF (hour) | 1 200 000 | 1 600 000 | 1 200 000 | 2 000 000 |
| Notes | The development of ATA serial drives. SATA 2.0 supports transfer rates of 300MB / s, SATA3.0 supports up to 600MB / s. The average% failure rate AFR (Annualized Failure Rate) for SATA drives is about 2%. |
Hard sATA drives with SAS interface are suitable for hierarchical (tiering). The average annual failure rate AFR (Annualized Failure Rate) for NL-SAS drives is about 2%. | Solid state drives made of electronic memory chips, including a control device and a chip (FLASH / DRAM). The specification of the interface, functions and method of use are the same as that of the HDD, size and shape, too. |
Hard drive specifications:
- Capacity
In modern hard drives capacity is measured in gigabytes or terabytes. For HDD, this value is a multiple of the capacity of one magnetic disk inside the box, multiplied by the number of magnetic, which is usually several.
- Rotation Speed \u200b\u200b(HDD only)
The speed of rotation of the magnetic disks inside the drive, measured in revolutions per minute RPM (Rotation Per Minute), is usually 5400 RPM or 7200 RPM. HDDs with SCSI / SAS interfaces have a rotation speed of 10,000-15,000 RPM.
- Average access time \u003dMean seek time + Mean wait time, i.e. time to extract information from the disk.
- Data rate
These are the read and write speeds of data on the hard drive, measured in megabytes per second (MB / S). They usually differ from each other in size.
- IOPS (Input / Output Per Second)
The number of input / output operations (or read / write) per second (Input / Output Operations Per Second), one of the main indicators of measuring disk performance. For applications with frequent read and write operations, such as OLTP (Online Transaction Processing) - online transaction processing, IOPS is the most important indicator, because the performance of the business application depends on it. Another important indicator is data throughput, which can roughly be translated as “data throughput”, i.e. how much data can be transferred per unit of time.
RAID
No matter how reliable the hard drives are, still the data in them is sometimes lost, for various reasons. Therefore, RAID technology (Redundant Array of Independent Disks) was proposed - an array of independent disks with data storage redundancy. Redundancy means that all data bytes are duplicated on another disk on another disk, and can be used if the first disk fails. In addition, this technology helps increase IOPS.
The basic concepts of RAID are stripping (the so-called "streaming" or separation) and mirroring (the so-called "mirroring", or duplication) of data. Their combinations determine different kinds RAID arrays of hard drives.
The following RAID levels are distinguished:
Combinations of these types give rise to several new types of RAID:
The figure illustrates the principle of RAID 0 (partitioning):
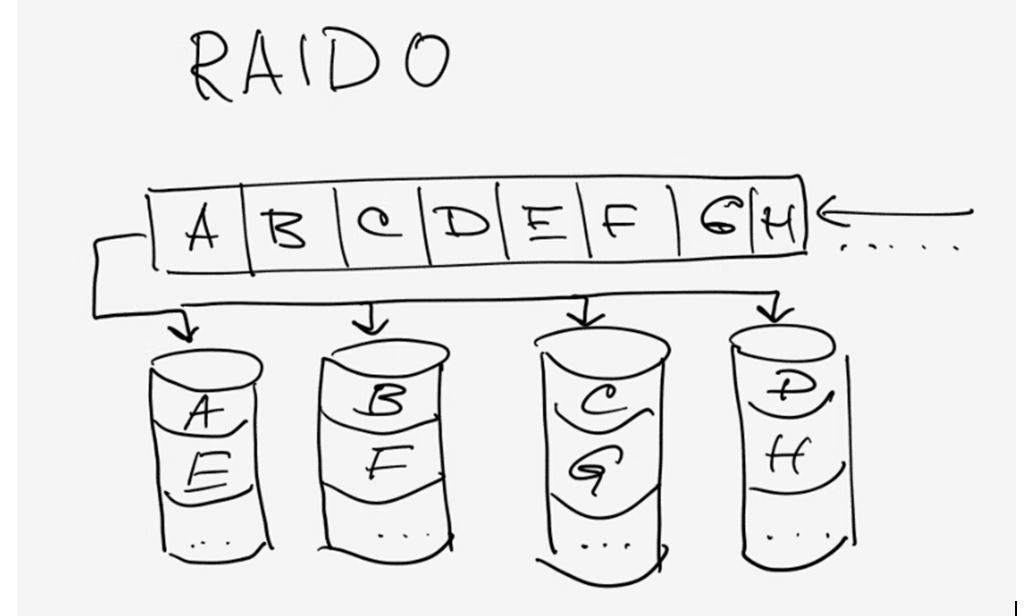
Fig. 6. RAID 0.
And so RAID 1 (duplication) is performed:
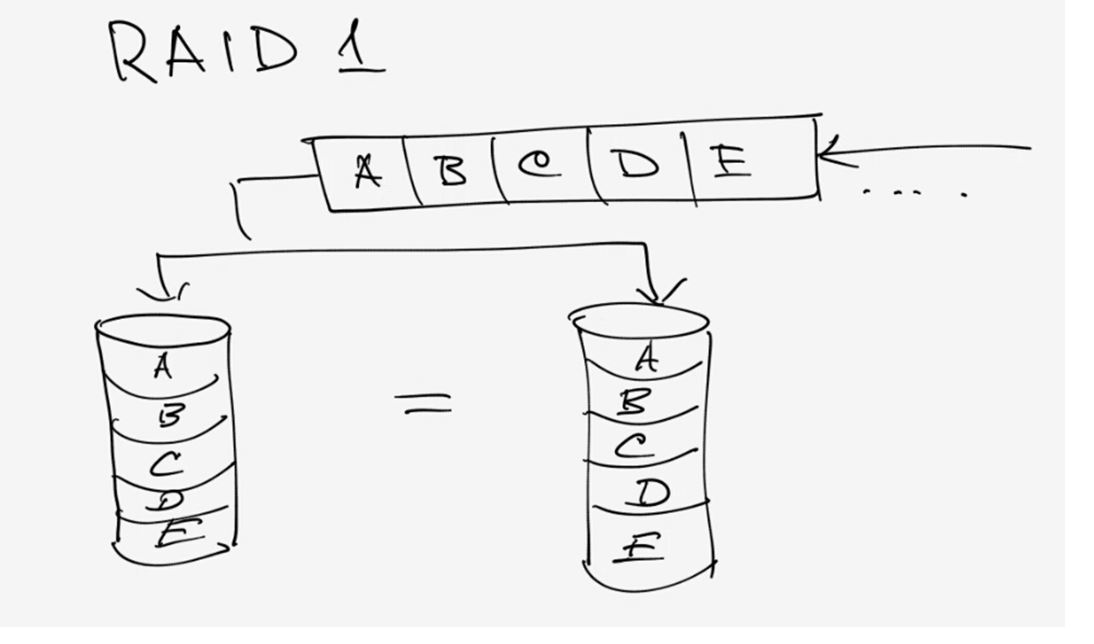
Fig. 7. RAID 1.
And this is how RAID 3 works. XOR is a logical function exclusive OR (eXclusive OR). Using it, the parity value for data blocks A, B, C, D ... is calculated, which is recorded on a separate disk.
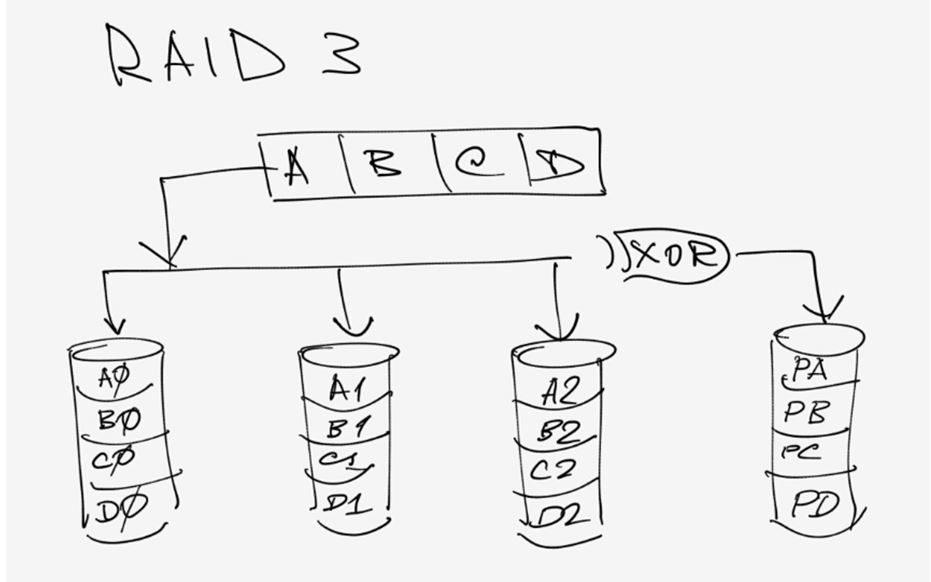
Fig. 8. RAID 3.
The above schemes illustrate well the principle of RAID and do not need comments. We will not give the operation schemes of the remaining RAID levels; those who wish can find them on the Internet.
The main characteristics of the types of RAID are given in the table.
Storage Software
Storage software can be divided into the following categories:
- Management and administration (Management): management and specification of infrastructure parameters: ventilation, cooling, disk operation modes, etc., time-of-day management, etc.
- Data protection: Snapshot (“snapshot” of disk status), copying the contents of LUN, multiple duplication (split mirror), remote data duplication (Remote Replication), continuous data protection CDP (Continuous Data Protection), etc.
- Reliability Improvement:various software for multiple copying and reservation of data transmission routes within the data center and between them.
- Increase Efficiency: Thin Provisioning technology, automatic storage tiered storage, deduplication, quality of service management, cache prefetch, partitioning, automatic data migration , decrease in disk spin down
Very interesting technology " thin provisioning". As is often the case in IT, the terms are often difficult to adequately translate into Russian, for example, it is difficult to accurately translate the word “provisioning” (“provision”, “support”, “provision” - none of these terms fully conveys meaning). And when it is “thin” ...
According to the principle of "thin provisioning", for example, a bank loan works. When a bank gives out ten thousand loans with a limit of 500 thousand, it does not need to have 5 billion in the account, as card users usually do not spend all the credit at once. Nevertheless, each user individually can use the entire or almost the entire loan amount if the total amount of the bank’s funds has not been exhausted.
Water and electric companies also work. Providing water or electricity supply services, they expect that all residents will not immediately open all the taps or turn on all electrical appliances in their homes. Due to more flexible consumption of resources, it is possible to save on their price and resource capacity.

Fig. 9. Thin provisioning.
Thus, the use of thin provisioning allows us to solve the problem of inefficient distribution of space in the SAN, save space, facilitate administrative procedures for allocating space to applications on the storage, and use the so-called oversubscribing, that is, to allocate more space for applications than we physically have in mind that That applications do not demand all space at the same time. As the need arises in it later, it is possible to increase the physical capacity of the storage.
The division of the storage system into tiered storage levels assumes that various data are stored in storage devices whose performance corresponds to the frequency of access to this data. For example, frequently used data can be placed in “online storage” on sSD drives with high access speed, high performance. However, the price of such disks is still high, so it is advisable to use them only for online storage (for now).
FC / SAS drives are also quite fast, and the price is moderate. Therefore, such disks are well suited for “near-line storage”, where data is stored, access to which occurs not so often, but at the same time and not so rarely.
Finally, SATA / NL-SAS drives have a relatively low access speed, but they are distinguished by high capacity and relatively cheap. Therefore, they usually do offline storage, for data of rare use.
As soon as the management system notices that data access to offline storage has become more frequent, it transfers them to near-line storage, and with further activation of its use, it also goes to online storage on SSD disks.
Deduplication (repetition elimination) of data (deduplication, DEDUP): as the name implies, eliminates duplicate data in the disk space commonly used in data backup. Although the system is unable to determine what information is redundant, it can determine whether data is duplicated. Due to this, it becomes possible to significantly reduce the requirements for the capacity of the backup system.
Disk spin-down reduction) - what is usually called the "hibernation" (falling asleep) of the disk. Data on some drive may not be used long time, in this case, the technology of reducing the speed of the disk puts them in hibernation mode in order to reduce the energy consumption for useless rotation of the disk at normal speed. This also increases the life of the disk, and increases the reliability of the system as a whole. When you receive the first request for data on this disk, it "wakes up", its rotation speed increases. The cost to save energy and increase reliability is some delay when you first access the data on the disk, but this board is justified.
Snapshot of the state of the disk (Snapshot) Snapshot is a fully usable copy of a specific data set on the disk at the time this copy was taken (which is why it is called a “snapshot”). Such a copy is used to partially restore the state of the system at the time of copying. At the same time, the continuity of the system is not affected at all, and the performance is not deteriorated.
Remote Replication: Works using mirroring technology. May support multiple copies of data on two or more sites to prevent data loss in the event of natural disasters. There are two types of replication: synchronous and asynchronous, the difference between them is explained in the figure.
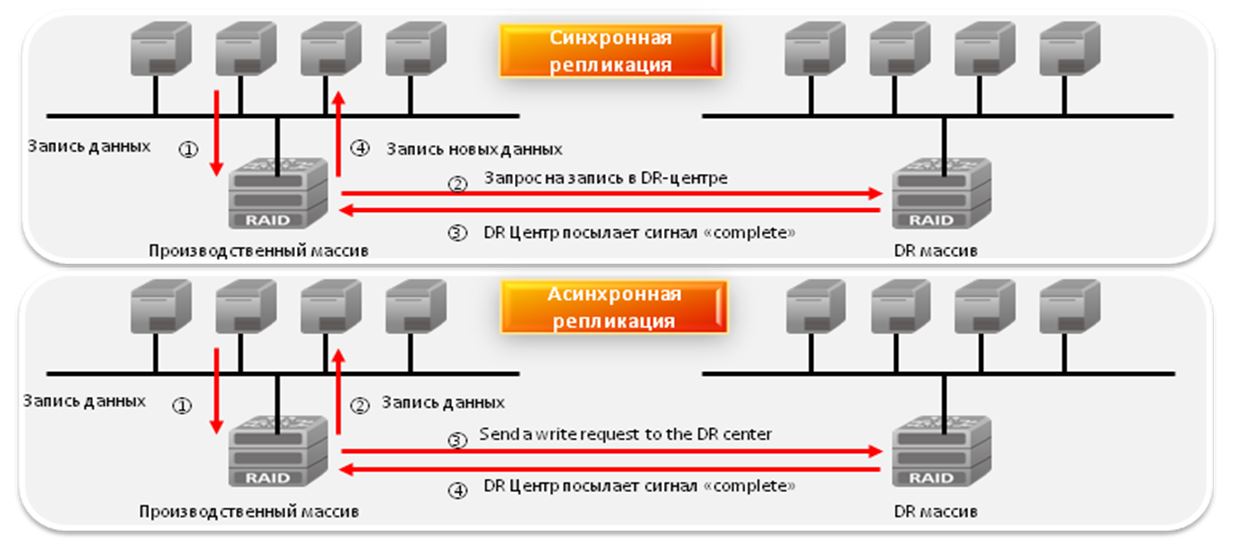
Fig. 10. Remote replication of data (Remote Replication).
Continuous data protection (CDP)Also known as continuous backup or real-time backup, it creates a backup automatically every time you change data. At the same time, it becomes possible to recover data from any accidents at any time, and at the same time, an actual copy of the data is available, and not those that were a few minutes or hours ago.
Management and Administration Programs (Management Software):this includes a variety of software for managing and administering various devices: simple programs configuration (cofiguration wizards), central monitoring programs: topology mapping, real-time monitoring, failure reporting mechanisms. Also included are the Business Guarantee programs: multi-dimensional performance statistics, performance reports and queries, etc.
Disaster Recovery (DR, Disaster Recovery). This is a rather important component of serious industrial storage systems, although it is quite expensive. But these costs must be borne so as not to lose overnight “what has been gained through overwork” and where significant funds have already been invested. The data protection systems discussed above (Snapshot, Remote Replication, CDP) are good as long as there is no natural disaster in the settlement where the storage system is located: tsunami, flood, earthquake or (pah-pah-pah) - nuclear war. Yes, and any war is also capable of greatly spoiling the lives of people who are engaged in useful things, for example, storing data, and not running around with a gun to chop off other people's territories or punish some "infidels." Remote replication implies that the replicating storage system is in the same city, or at least nearby. Which, for example, does not save during the tsunami.
Disaster Recovery technology assumes that the backup center used to recover data from natural disasters is located at a considerable distance from the main data center, and interacts with it through a data network superimposed on a transport network, most often an optical one. Using such a location of the main and backup data centers, for example, CDP technology will simply be technically impossible.
DR technology uses three fundamental concepts:
- BW (Backup Window) - “Reservation window”, the time required for the reservation system in order to copy the received data volume of the working system.
- RPO (Recovery Point Objective) - “Permissible recovery point”, the maximum period of time and the corresponding amount of data that is acceptable to lose for the user of storage.
- RTO (Recovery Time Objective) - “allowable unavailability time”, the maximum time during which the storage system may be unavailable without critical impact on the core business.

Fig. 11. Three fundamental concepts of DR technology.
This essay does not claim to be complete and only explains the basic principles of operation of storage systems, although by no means in full. Various sources on the Internet contain many documents that describe in more detail all the points set forth (and not set out) here.
Data Storage System (SHD) is a conglomerate of specialized equipment and software that is designed to store and transfer large amounts of information. Allows you to organize the storage of information on disk platforms with optimal resource allocation.
Another factor is the appearance on the market of many companies that offer their solutions to support the business of enterprises: ERP, billing systems, decision support systems, etc. All of them allow you to collect detailed data of various nature in huge volumes. If your organization has a developed IT infrastructure, you can collect this data together and analyze it.
The next factor is technological. Until some time, application manufacturers independently developed different versions of their solutions for different server platforms or offered open solutions. An important technological trend for the industry was the creation of adaptable platforms for solving various analytical problems, which include the hardware component and the DBMS. Users no longer care who made a processor for their computer or random access memory, - they see the data warehouse as a kind of service. And this is a major shift in consciousness.
Technologies that allow you to use data warehouses to optimize operational business processes in almost real time, not only for highly qualified analysts and top managers, but also for front office employees, in particular for employees of sales offices and contact centers. Decision making is delegated to employees at the lower levels of the corporate ladder. The reports they need are usually simple and concise, but they require a lot, and the formation time should be short.
Storage Applications
Traditional data warehouses can be found everywhere. They are designed to generate reports that help to understand what happened in the company. However, this is the first step, the basis.
It’s not enough for people to know what happened, they want to understand why it happened. For this, business intelligence tools are used to help understand what the data says.
Following this comes the use of the past to predict the future, building predictive models: which customers will stay and which will leave; which products will succeed, and which will fail, etc.
Some organizations are already at the stage when data warehouses are beginning to be used to understand what is happening in the business today. Therefore, the next step is the "activation" of the front systems with the help of solutions based on data analysis, often in automatic mode.
Volumes digital information grow like an avalanche. In the corporate sector, this growth is caused, on the one hand, by stricter regulation and the requirement to retain more and more information related to doing business. On the other hand, toughening competition requires more and more accurate and detailed information about the market, customers, their preferences, orders, actions of competitors, etc.
In the public sector, an increase in the volume of stored data is supported by the ubiquitous transition to interdepartmental electronic document management and the creation of departmental analytical resources based on a variety of primary data.
No less powerful wave create and ordinary userswho post on the Internet their photos, videos and actively share multimedia content on social networks.
Storage Requirements

What is the most important criterion for choosing disk storage? The result of the survey on the site www.timcompany.ru, February 2012
In 2008, the TIM group of companies conducted a survey among customers in order to find out which characteristics are most important for them when choosing storage systems. The first positions were the quality and functionality of the proposed solution. At the same time, the calculation of the total cost of ownership for the Russian consumer is an atypical phenomenon. Customers most often do not fully understand what costs await them, for example, rental and equipment costs, electricity, air conditioning, training and salaries of qualified personnel, etc.
When there is a need to purchase storage, the maximum that the buyer estimates for himself is the direct costs that go through the accounting department to purchase this equipment. However, the price in terms of importance was in ninth place out of ten. Of course, customers take into account possible difficulties associated with the maintenance of equipment. Usually, extended warranty support packages, which are usually offered in projects, help to avoid them.
Reliability and fault tolerance. The storage system provides for full or partial redundancy of all components - power supplies, access paths, processor modules, disks, cache, etc. It is imperative to have a monitoring and notification system about possible and existing problems.
Data availability. It is provided with thought-out functions for maintaining data integrity (using RAID technology, creating full and instant copies of data inside a disk rack, replicating data to a remote storage system, etc.) and the ability to add (update) equipment and software in hot mode without stopping the complex;
Management and control tools. Storage management is carried out through a web interface or command line, there are monitoring functions and several options for notifying the administrator about problems. Available hardware technology diagnostic performance.
Performance. It is determined by the number and type of drives, the amount of cache memory, the processing power of the processor subsystem, the number and type of internal and external interfaces, as well as the flexibility of customization and configuration.
Scalability. In a storage system, there is usually the possibility of increasing the number of hard drives, cache size, hardware upgrades and expanding functionality with the help of special software. All these operations are performed without significant reconfiguration and loss of functionality, which allows you to save money and flexibly approach the design of IT infrastructure.
Storage Types
Disk Storage
Used for operational work with data, as well as for creating intermediate backups.
The following types of disk storage systems are available:
- Storage for operational data (high-performance equipment);
- Storage for backups (disk libraries);
- SHD for long-term storage of archives (CAS systems).
Tape Storage
Designed to create backups and archives.
The following types of tape storage systems exist:
- individual drives;
- autoloaders (one drive and several tape slots);
- tape libraries (more than one drive, many tape slots).
Storage Connectivity Options
Various internal interfaces are used to connect devices and hard drives within the same storage:
The most common external storage connection interfaces:
The popular Infiniband internode cluster interaction interface is now also used to access storage.
Storage Topology Options
The traditional approach to data warehouses is to directly connect servers to the Direct Attached Storage, DAS (Direct Attached Storage) storage system. In addition to Direct Attached Storage, DAS, there are network attached storage devices - NAS (Network Attached Storage), as well as storage area network components - SAN (Storage Area Networks). Both NAS and SAN systems have emerged as an alternative to the Direct Attached Storage, DAS architecture. Moreover, each solution was developed as a response to the growing requirements for data storage systems and was based on the use of technologies available at that time.
Network storage system architectures were developed in the 1990s, and their task was to address the main shortcomings of Direct Attached Storage, DAS systems. In the general case, network solutions in the field of storage systems had to implement three tasks: reduce costs and data management complexity, reduce traffic local networks, increase data availability and overall performance. At the same time, NAS and SAN architectures solve various aspects of a common problem. The result was the simultaneous coexistence of two network architectures, each of which has its own advantages and functionality.
Direct Attached Storage Systems (DAS)
Since storage systems are inseparable from computing resources, it is not surprising that many of the world's largest manufacturers of storage systems are simultaneously leaders in the server market. Of the above manufacturers, only three are exclusively engaged in storage - these are EMC, Hitachi and NetApp.
Among the manufacturers of storage systems represented in our country, we note the companies that belong to the above-mentioned class “B”.
- Cisco (Linksys)
The growing concept of public clouds has an impact on the storage segment. Owners of public clouds are less likely to pay brand premiums, which may open up great opportunities for second-tier manufacturers, niche or new players.
Domestic disk drives manufacturers (for example, DEPO Computers (DEPO Electronics)) assemble their systems based on components from foreign manufacturers, including Microsemi (formerly Adaptec), Chenbro, Falconstore, Intel, LSI Logic, Luster and others. In general, local storage systems are delivered mainly to small projects. In addition, it is important to note that in the storage segment there is a persistent trend towards crowding out domestic companies by global ones.
An important difference between A-brand systems and local storage systems is that they have special software designed to restore and protect data, backup, remote control and monitoring, "Information Lifecycle Management (ILM), diagnostics, etc. Software with similar functions is developed by many independent companies, so it can be purchased separately. Of course, in the absence of compatibility problems.
Storage cost is very dependent on functionality and additional options - expansion modules, such as hard drives, service, etc.
Russian storage market
In the past few years, the Russian storage market has been successfully developing and growing. So, at the end of 2010, the revenue of manufacturers of storage systems sold on the Russian market exceeded $ 65 million, which is 25% and 59% more than in the second quarter of the same year. Total capacity data storage amounted to approximately 18 thousand terabytes, which is an indicator of growth of more than 150% per year.
The Russian market for data storage systems is developing extremely dynamically due to the fact that it is still very young. The lack of legacy equipment does not have a significant impact on it, because due to the explosive growth in data volumes, old systems simply do not meet customer requirements and are “washed out” much faster than, for example, ancient servers and workstations.
The rapid growth of data volumes is increasingly forcing domestic companies to purchase external disk storage systems. This is largely due to the traditional trend of lowering the cost of IT components. If previously external storage systems were perceived only as an attribute of large organizations, now even small companies do not reject the need for these systems.
Milestones for data warehouse projects
A data warehouse is a very complex object. One of the main conditions for its creation is the availability of competent specialists who understand what they are doing - not only on the supplier side, but also on the client side. Storage consumption is becoming an integral part of the implementation of integrated infrastructure solutions. As a rule, we are talking about impressive investments for 3-5 years, and customers expect that during the entire period of operation the system will fully meet the requirements of the business.
Next, you need to have data warehousing technologies. If you started to create a repository and are developing a logical model for it, then you should have a dictionary that defines all the basic concepts. Even such common concepts as “customer” and “product” have hundreds of definitions. Only after gaining an idea of \u200b\u200bwhat these or those terms mean in this organization, you can determine the sources of the necessary data that should be uploaded to the repository.
Now you can start creating logical model data. This is a critical phase of the project. It is necessary from all participants in the project to create a data warehouse to reach agreement on the relevance of this model. Upon completion of this work, it becomes clear what the client really needs. And only then it makes sense to talk about technological aspects, for example, about the size of the storage. The client finds himself face to face with a gigantic data model that contains thousands of attributes and relationships.
Keep in mind that data warehousing should not be a toy for the IT department and a cost to the business. And first of all, the data warehouse should help customers solve their most critical problems. For example, help telecommunications companies prevent customer diversion. To solve the problem, it is necessary to fill in certain fragments of a large data model, and then we help to select applications that will help solve this problem. These can be very simple applications, say Excel. The first step is to try to solve the main problem with these tools. Trying to fill the whole model at once, using all data sources will be a big mistake. Data in the sources must be carefully analyzed to ensure their quality. After successfully solving one or two problems of paramount importance, during which the quality of the data sources necessary for this is ensured, you can begin to solve the following problems, gradually filling in other fragments of the data model, as well as using previously filled fragments.
The TAdviser catalog lists a number of Russian companies related to the supply and implementation of storage systems and the provision of related services. At the same time, it’s worthwhile to understand that in a number of large projects, some vendors can participate directly, primarily HP and IBM. Some customers in this case feel more confident, fully relying on service support from leading manufacturers. Of course, the cost of ownership in this case increases markedly.
Trends and Prospects
Rapid evolution annually makes major changes to the main trends in the development of storage systems. So, in 2009, the ability to economically allocate resources (Thin Provisioning) was paramount, the last few years have been marked by the work of storage in the clouds. The range of the proposed systems is diverse: a huge number of models presented, various options and combinations of solutions from the entry level to the Hi-End class, turnkey solutions and component-wise assembly using the most modern filling, software and hardware solutions from Russian manufacturers.
The desire to reduce costs for IT infrastructure requires a constant balance between the cost of storage resources and the value of the data that is stored on them at a given time. To decide on how to most efficiently allocate resources on software and hardware, data center specialists are guided not only by ILM and DLM approaches, but also by the practice of multi-tier data storage. Each unit of information to be processed and stored is assigned specific metrics. These include the degree of accessibility (speed of providing information), importance (cost of data loss in the event of a hardware and software failure), the period through which information goes to the next stage.
 An example of separation of storage systems in accordance with the requirements for the storage and processing of information according to the method of multilevel data storage.
An example of separation of storage systems in accordance with the requirements for the storage and processing of information according to the method of multilevel data storage.
At the same time, the performance requirements of transactional systems have increased, which implies an increase in the number of disks in the system and, accordingly, the choice of a higher-class storage system. In response to this challenge, manufacturers have provided storage systems with new solid-state drives that are more than 500 times faster than the previous ones in “short” read / write operations (typical of transactional systems).
The popularization of the cloud paradigm has increased the requirements for storage performance and reliability, since in the event of a data failure or loss, more than one or two directly connected servers will suffer - a denial of service will occur for all users of the cloud. Owing to the same paradigm, a tendency has been shown to unite devices of different manufacturers into a federation. It creates a unified pool of resources that are provided on demand with the ability to dynamically move applications and data between geographically dispersed sites and service providers.
A certain shift was noted in 2011 in the area of \u200b\u200bBig Data management. Previously, such projects were under discussion, but now they have entered the implementation stage, going all the way from sale to implementation.
A breakthrough is planned on the market, which has already happened on the server market, and, possibly, already in 2012 we will see mass storage systems supporting deduplication and Over Subscribing technology in the mass segment. As a result, as in the case of server virtualization, this will provide large-scale utilization of storage capacity.
Further development of storage optimization will be to improve data compression methods. For unstructured data, which accounts for 80% of the total volume, the compression ratio can reach several orders of magnitude. This will significantly reduce the unit cost of data storage for modern SSDs.