What are storage systems (SHD) and what are they for? What is the difference between iSCSI and FiberChannel? Why did this phrase only in recent years become known to a wide circle of IT-specialists and why are the issues of data storage systems more and more worrying thoughtful minds?
I think many people noticed development trends in the computer world that surrounds us - the transition from an extensive development model to an intensive one. The increase of megahertz processors no longer gives a visible result, and the development of drives does not keep up with the amount of information. If in the case of processors everything is more or less clear - it’s enough to assemble multiprocessor systems and / or use several cores in one processor, then in case of issues of storage and processing of information it’s not so easy to get rid of problems. The current panacea for the information epidemic is storage. The name stands for Storage Area Network or Storage System. In any case, it’s special 
Main problems solved by storage
So, what tasks is the storage system designed to solve? Consider the typical problems associated with the growing volume of information in any organization. Suppose these are at least a few dozen computers and several geographically spaced offices.
1. Decentralization of information - if earlier all data could be stored literally on one hard disk, now any functional system requires a separate storage - for example, servers email, DBMS, domain and so on. The situation is complicated in the case of distributed offices (branches).
2. The avalanche-like growth of information - Often the number of hard drives that you can install in a particular server cannot cover the capacity of the system. Consequently:
The inability to fully protect the stored data is indeed, because it is quite difficult to even backup data that is not only on different servers, but also geographically dispersed.
Insufficient information processing speed - communication channels between remote sites still leave much to be desired, but even with a sufficiently “thick” channel it is not always possible to fully use existing networks, for example, IP, for work.
The complexity of the backup - if the data is read and written in small blocks, then it can be unrealistic to make complete archiving of information from a remote server through existing channels - it is necessary to transfer the entire amount of data. Local archiving is often impractical for financial reasons - backup systems (tape drives, for example), special software (which can cost a lot of money), and trained and qualified personnel are needed.
3. It is difficult or impossible to predict the required volume disk space when deploying a computer system. Consequently:
There are problems of expanding disk capacities - it is quite difficult to get terabyte capacities in the server, especially if the system is already running on existing small-capacity disks - at a minimum, a system shutdown and inefficient financial investments are required.
Inefficient utilization of resources - sometimes you can’t guess which server the data will grow faster. A critically small amount of disk space can be free in the e-mail server, while another unit will use only 20% of the volume of an expensive disk subsystem (for example, SCSI).
4. Low confidentiality of distributed data - it is impossible to control and restrict access in accordance with the security policy of the enterprise. This applies to both access to data on the channels existing for this (local area network) and physical access to media - for example, theft of hard drives and their destruction are not excluded (in order to complicate the business of the organization). Unqualified actions by users and maintenance personnel can be even more harmful. When a company in each office is forced to solve small local security problems, this does not give the desired result.
5. The complexity of managing distributed information flows - any actions that are aimed at changing data in each branch that contains part of the distributed data creates certain problems, ranging from the complexity of synchronizing various databases, versions of developer files to unnecessary duplication of information.
6. Low economic effect of the introduction of "classic" solutions - with the growth of the information network, large amounts of data and an increasingly distributed structure of the enterprise, financial investments are not so effective and often cannot solve the problems that arise.
7. The high costs of the resources used to maintain the efficiency of the entire enterprise information system - from the need to maintain a large staff of qualified personnel to numerous expensive hardware solutions that are designed to solve the problem of volumes and speeds of access to information, coupled with reliable storage and protection from failures.
In light of the above problems, which sooner or later, completely or partially overtake any dynamically developing company, we will try to describe the storage systems - as they should be. Consider typical connection schemes and types of storage systems.
Megabytes / transactions?
If earlier hard disks were inside the computer (server), now they have become cramped and not very reliable there. The simplest solution (developed long ago and used everywhere) is RAID technology.
images \\ RAID \\ 01.jpg
When organizing RAID in any storage systems, in addition to protecting information, we get several undeniable advantages, one of which is the speed of access to information.
From the point of view of the user or software, the speed is determined not only by the system capacity (MB / s), but also by the number of transactions - that is, the number of I / O operations per unit time (IOPS). Logically, a larger number of disks and those performance improvement techniques that a RAID controller provides (such as caching) contribute to IOPS.
If overall throughput is more important for viewing streaming video or organizing a file server, then for the DBMS and any OLTP (online transaction processing) applications, it is the number of transactions that the system is capable of processing that is critical. And with this option, modern hard drives are not so rosy as with growing volumes and, in part, speeds. All these problems are intended to be solved by the storage system itself.
Protection levels
You need to understand that the basis of all storage systems is the practice of protecting information based on RAID technology - without this, any technically advanced storage system will be useless, because the hard drives in this system are the most unreliable component. Organizing disks in RAID is the "lower link", the first echelon of information protection and increased processing speed.
However, in addition to RAID schemes, there is a lower-level data protection implemented “on top” of technologies and solutions embedded in the hard drive itself by its manufacturer. For example, one of the leading storage manufacturers, EMC, has a methodology for additional data integrity analysis at the drive sector level.
Having dealt with RAID, let's move on to the structure of the storage systems themselves. First of all, storage systems are divided according to the type of host (server) connection interfaces used. External connection interfaces are mainly SCSI or FibreChannel, as well as the fairly young iSCSI standard. Also, do not discount small intelligent stores that can even be connected via USB or FireWire. We will not consider rarer (sometimes simply unsuccessful in one way or another) interfaces, such as IBM SSA or interfaces developed for mainframes - for example, FICON / ESCON. Stand alone NAS storage, connected to the Ethernet network. The word “interface” basically means an external connector, but do not forget that the connector does not determine the communication protocol of the two devices. We will dwell on these features a little lower.
images \\ RAID \\ 02.gif
It stands for Small Computer System Interface (read "tell") - a half-duplex parallel interface. In modern storage systems, it is most often represented by a SCSI connector:
images \\ RAID \\ 03.gif
images \\ RAID \\ 04.gif
And a group of SCSI protocols, and more specifically - SCSI-3 Parallel Interface. The difference between SCSI and the familiar IDE is a larger number of devices per channel, a longer cable length, a higher data transfer rate, as well as “exclusive” features like high voltage differential signaling, command quequing and some others — we won’t go into this issue.
If we talk about the main manufacturers of SCSI components, such as SCSI adapters, RAID controllers with SCSI interface, then any specialist will immediately remember two names - Adaptec and LSI Logic. I think this is enough, there have been no revolutions in this market for a long time and probably is not expected.
FiberChannel Interface
Full duplex serial interface. Most often, in modern equipment it is represented by external optical connectors such as LC or SC (LC - smaller in size):
images \\ RAID \\ 05.jpg
images \\ RAID \\ 06.jpg
... and the FibreChannel Protocols (FCP). There are several FibreChannel device switching schemes:
Point-to-point - point-to-point, direct connection of devices to each other:
images \\ RAID \\ 07.gif
Crosspoint switched - connecting devices to the FibreChannel switch (similar to the Ethernet network implementation on the switches):
images \\ RAID \\ 08.gif
Arbitrated loop - FC-AL, loop with arbitration access - all devices are connected to each other in a ring, the circuit is somewhat reminiscent of Token Ring. A switch can also be used - then the physical topology will be implemented according to the “star” scheme, and the logical one - according to the “loop” (or “ring”) scheme:
images \\ RAID \\ 09.gif
Connection according to the FibreChannel Switched scheme is the most common scheme, in terms of FibreChannel such connection is called Fabric - in Russian there is a tracing-paper from it - “factory”. It should be noted that FibreChannel switches are quite advanced devices that are close in complexity to IP-level 3 IP switches. If the switches are interconnected, they operate in a single factory with a pool of settings that are valid for the entire factory at once. Changing some options on one of the switches can lead to a re-switching of the entire factory, not to mention access authorization settings, for example. On the other hand, there are SAN schemes that involve several factories within a single sAN. Thus, a factory can only be called a group of interconnected switches - two or more devices not interconnected, introduced into the SAN to increase fault tolerance, form two or more different factories.
Components that allow combining hosts and storage systems into a single network are commonly referred to as “connectivity”. Connectivity is, of course, duplex connecting cables (usually with an LC interface), switches (switches) and FibreChannel adapters (HBA, Host Base Adapters) - that is, those expansion cards that, when installed in the hosts, allow you to connect the host to the network SAN. HBAs are typically implemented as PCI-X or PCI-Express cards.
images \\ RAID \\ 10.jpg
Do not confuse fiber and fiber - the signal propagation medium can be different. FiberChannel can work on "copper". For example, all FibreChannel hard drives have metal contacts, and the usual switching of devices via copper is not uncommon, they just gradually switch to optical channels as the most promising technology and functional replacement of copper.
ISCSI interface
Usually represented by an external RJ-45 connector for connecting to an Ethernet network and the protocol itself iSCSI (Internet Small Computer System Interface). By the definition of SNIA: “iSCSI is a protocol that is based on TCP / IP and is designed to establish interoperability and manage storage systems, servers and clients.” We’ll dwell on this interface in more detail, if only because each user is able to use iSCSI even on a regular “home” network.
You need to know that iSCSI defines at least the transport protocol for SCSI, which runs on top of TCP, and the technology for encapsulating SCSI commands in an IP-based network. Simply put, iSCSI is a protocol that allows block access to data using SCSI commands sent over a network with a TCP / IP stack. iSCSI appeared as a replacement for FibreChannel and in modern storage systems has several advantages over it - the ability to combine devices over long distances (using existing IP networks), the ability to provide a specified level of QoS (Quality of Service, quality of service), lower cost connectivity. However, the main problem of using iSCSI as a replacement for FibreChannel is the long time delays that occur on the network due to the peculiarities of the TCP / IP stack implementation, which negates one of the important advantages of using storage systems - speed of access to information and low latency. This is a serious minus.
A small remark about hosts - they can use both regular network cards (then iSCSI stack processing and encapsulation of commands will be done by software), as well as specialized cards supporting technologies similar to TOE (TCP / IP Offload Engines). This technology provides hardware processing of the corresponding part of the iSCSI protocol stack. Software method cheaper, but it loads the server’s central processor more and, in theory, can lead to longer delays than a hardware processor. With the current speed of Ethernet networks at 1 Gbit / s, it can be assumed that iSCSI will work exactly twice as slow as the FibreChannel at a speed of 2 Gbit, but in real use the difference will be even more noticeable.
In addition to those already discussed, we briefly mention a couple of protocols that are more rare and are designed to provide additional services to existing storage area networks (SANs):
FCIP (Fiber Channel over IP) - A tunneling protocol built on TCP / IP and designed to connect geographically dispersed SANs through a standard IP environment. For example, you can combine two SANs into one over the Internet. This is achieved by using an FCIP gateway that is transparent to all devices in the SAN.
iFCP (Internet Fiber Channel Protocol) - A protocol that allows you to combine devices with FC interfaces via IP networks. An important difference from FCIP is that it is possible to unite FC devices through an IP network, which allows for a different pair of connections to have a different level of QoS, which is not possible when tunneling through FCIP.
We briefly examined the physical interfaces, protocols, and switching types for storage systems, without stopping at listing all possible options. Now let's try to imagine what parameters characterize data storage systems?
Main hardware parameters of storage
Some of them were listed above - these are the type of external connection interfaces and types internal drives (hard drives). The next parameter, which makes sense to consider after the two of the above when choosing a disk storage system, is its reliability. Reliability can be assessed not by the banal running hours of failure of any individual components (the fact that this time is approximately equal for all manufacturers), but by the internal architecture. A “regular” storage system often “externally” is a disk shelf (for mounting in a 19-inch cabinet) with hard drives, external interfaces for connecting hosts, several power supplies. Inside, usually everything that provides the storage system is installed - processor units, disk controllers, input-output ports, cache memory and so on. Typically, the rack is controlled from command line or via the web interface, the initial configuration often requires a serial connection. The user can “split” the disks in the system into groups and combine them into RAID (of different levels), the resulting disk space is divided into one or more logical units (LUNs), to which hosts (servers) have access and “see” them as local hard drives. The number of RAID groups, LUNs, the logic of the cache, the availability of LUNs to specific servers and everything else is configured by the system administrator. Typically, storage systems are designed to connect to them not one, but several (up to hundreds, in theory) servers - therefore, such a system should have high performance, a flexible control and monitoring system, and well-thought-out data protection tools. Data protection is provided in many ways, the easiest of which you already know - the combination of disks in RAID. However, the data must also be constantly accessible - after all, stopping one data storage system central to the enterprise can cause significant losses. The more systems store data on the storage system, the more reliable access to the system must be provided - because in the event of an accident, the storage system stops working immediately on all servers that store data there. High rack availability is ensured by complete internal duplication of all system components - access paths to the rack (FibreChannel ports), processor modules, cache memory, power supplies, etc. We will try to explain the principle of 100% redundancy (duplication) with the following figure:
images \\ RAID \\ 11.gif
1. The controller (processor module) of the storage system, including:
* central processor (or processors) - usually special software runs on the system, performing the role of " operating system»;
* interfaces for switching with hard disks - in our case, these are boards that provide connection of FibreChannel disks according to the arbitration access loop scheme (FC-AL);
* cache memory;
* FibreChannel external port controllers
2. The external interface of FC; as we see, there are 2 of them for each processor module;
3. Hard disks - the capacity is expanded with additional disk shelves;
4. Cache memory in such a scheme is usually mirrored so as not to lose the data stored there when any module fails.
Regarding the hardware - disk racks can have different interfaces for connecting hosts, different interfaces of hard drives, different connection schemes for additional shelves, which serve to increase the number of disks in the system, as well as other purely “iron parameters”.
Software SHD
Naturally, the hardware power of the storage systems must be somehow managed, and the storage systems themselves are simply obliged to provide a level of service and functionality that is not available in conventional server-client schemes. If you look at the figure “Structural diagram of a data storage system”, it becomes clear that when the server is connected directly to the rack in two ways, they must be connected to the FC ports of various processor modules in order for the server to continue to work if the entire processor module fails immediately. Naturally, to use multipathing, support for this functionality should be provided by hardware and software at all levels involved in data transfer. Of course, full backup without monitoring and alerting does not make sense - therefore, all serious storage systems have such capabilities. For example, notification of any critical events can occur by various means - an e-mail alert, an automatic modem call to the technical support center, a message to a pager (now more relevant than SMS), SNMP mechanisms, and more.
Well, and as we already mentioned, there are powerful controls for all this magnificence. Usually this is a web-based interface, a console, the ability to write scripts and integrate control into external software packages. We'll only mention briefly about the mechanisms that ensure high performance of storage systems - non-blocking architecture with several internal buses and a large number of hard drives, powerful central processors, a specialized control system (OS), a large amount of cache memory, and many external I / O interfaces.
The services provided by storage systems are typically determined by software running on the disk rack itself. Almost always, these are complex software packages purchased under separate licenses that are not included in the cost of storage itself. Immediately mention the familiar software for providing multipathing - here it just functions on the hosts, and not on the rack itself.
The next most popular solution is software for creating instant and complete copies of data. Different manufacturers have different names for their software products and mechanisms for creating these copies. To summarize, we can manipulate the words snapshot and clone. A clone is made using the disk rack inside the rack itself - this is a complete internal copy of the data. The scope of application is quite wide - from backup to creating a “test version” of the source data, for example, for risky upgrades in which there is no confidence and which is unsafe to use on current data. Anyone who closely followed all the charms of storage that we were analyzing here would ask - why do you need a data backup inside the rack if it has such high reliability? The answer to this question on the surface is that no one is immune from human errors. The data is stored reliably, but if the operator did something wrong, for example, deleted the desired table in the database, no hardware tricks will save him. Data cloning is usually done at the LUN level. More interesting functionality is provided by the snapshot mechanism. To some extent, we get all the charms of a full internal copy of the data (clone), while not taking up 100% of the amount of data copied inside the rack itself, because such a volume is not always available to us. In fact, snapshot is an instant “snapshot” of data that does not take time and processor resources of storage.
Of course, one cannot fail to mention the data replication software, which is often called mirroring. This is a mechanism for synchronous or asynchronous replication (duplication) of information from one storage system to one or more remote storage systems. Replication is possible through various channels - for example, racks with FibreChannel interfaces can be replicated to another storage system asynchronously, via the Internet and over long distances. This solution provides reliable information storage and protection against disasters.
In addition to all of the above, there are a large number of other software mechanisms for data manipulation ...
DAS & NAS & SAN
After getting acquainted with the data storage systems themselves, the principles of their construction, the capabilities they provide and the functioning protocols, it's time to try to combine the acquired knowledge into a working scheme. Let's try to consider the types of storage systems and the topology of their connection to a single working infrastructure.
Devices DAS (Direct Attached Storage) - storage systems that connect directly to the server. This includes both the simplest SCSI systems connected to the server's SCSI / RAID controller, and FibreChannel devices connected directly to the server, although they are designed for SANs. In this case, the DAS topology is a degenerate SAN (storage area network):
images \\ RAID \\ 12.gif
In this scheme, one of the servers has access to data stored on the storage system. Clients access data by accessing this server through the network. That is, the server has block access to data on the storage system, and clients already use file access - this concept is very important for understanding. The disadvantages of such a topology are obvious:
* Low reliability - in case of network problems or server crashes, data becomes inaccessible to everyone at once.
* High latency due to the processing of all requests by one server and the transport used (most often - IP).
* High network load, often defining scalability limits by adding clients.
* Poor manageability - the entire capacity is available to one server, which reduces the flexibility of data distribution.
* Low utilization of resources - it is difficult to predict the required data volumes, some DAS devices in an organization may have an excess of capacity (disks), others may lack it - redistribution is often impossible or time-consuming.
Devices NAS (Network Attached Storage) - storage devices connected directly to the network. Unlike other systems, NAS provides file access to data and nothing else. NAS devices are a combination of the storage system and the server to which it is connected. In its simplest form, a regular network server providing file resources is a NAS device:
images \\ RAID \\ 13.gif
All the disadvantages of such a scheme are similar to the DAS topology, with some exceptions. Of the minuses that have been added, we note an increased, and often significantly, cost - however, the cost is proportional to functionality, and here already often there is "something to pay for". NAS devices can be the simplest “boxes” with one ethernet port and two hard drives in RAID1, allowing access to files using only one CIFS (Common Internet File System) protocol to huge systems in which hundreds of hard drives can be installed, and file access provided by a dozen specialized servers inside the NAS system. The number of external Ethernet ports can reach many tens, and the capacity of the stored data is several hundred terabytes (for example, EMC Celerra CNS). Reliability and performance of such models can bypass many SAN midrange devices. Interestingly, NAS devices can be part of a SAN network and do not have their own drives, but only provide file access to data stored on block storage devices. In this case, the NAS assumes the function of a powerful specialized server, and the SAN assumes the storage device, that is, we get the DAS topology composed of NAS and SAN components.
NAS devices are very good in a heterogeneous environment where you need fast file access to data for many clients at the same time. It also provides excellent storage reliability and system management flexibility coupled with ease of maintenance. We will not dwell on reliability - this aspect of storage is discussed above. As for a heterogeneous environment, access to files within a single NAS system can be obtained via TCP / IP, CIFS, NFS, FTP, TFTP and others, including the ability to work as a NAS iSCSI-target, which ensures operation with different operating systems, installed on hosts. As for ease of maintenance and management flexibility, these capabilities are provided by a specialized OS, which is difficult to disable and does not need to be maintained, as well as the ease of delimiting file permissions. For example, it is possible to work in the Windows Active Directory environment with support for the required functionality - it can be LDAP, Kerberos Authentication, Dynamic DNS, ACLs, quotas (quotas), Group Policy Objects and SID-history. Since access is provided to files, and their names may contain symbols of various languages, many NAS provide support for UTF-8, Unicode encodings. The choice of NAS should be approached even more carefully than to DAS devices, because such equipment may not support the services you need, for example, Encrypting File Systems (EFS) from Microsoft and IPSec. By the way, one can notice that NASs are much less widespread than SAN devices, but the percentage of such systems is still constantly, albeit slowly, growing - mainly due to the crowding out of DAS.
Devices to connect to SAN (Storage Area Network) - devices for connecting to a data storage network. A storage area network (SAN) should not be confused with a local area network - these are different networks. Most often, the SAN is based on the FibreChannel protocol stack and in the simplest case consists of storage systems, switches and servers connected by optical communication channels. In the figure we see a highly reliable infrastructure in which servers are included simultaneously in local network (left) and to the storage network (right):
images \\ RAID \\ 14.gif
After a fairly detailed discussion of the devices and their principles of operation, it will be quite easy for us to understand the SAN topology. In the figure, we see a single storage system for the entire infrastructure, to which two servers are connected. Servers have redundant access paths - each has two HBAs (or one dual-port, which reduces fault tolerance). The storage device has 4 ports by which it is connected to 2 switches. Assuming that there are two redundant processor modules inside, it is easy to guess that the best connection scheme is when each switch is connected to both the first and second processor modules. Such a scheme provides access to any data located on the storage system in the event of failure of any processor module, switch, or access path. We have already studied the reliability of storage systems, two switches and two factories further increase the availability of the topology, so if one of the switching units suddenly fails due to a failure or an administrator error, the second will function normally, because these two devices are not interconnected.
The server connection shown is called a high availability connection, although an even larger number of HBAs can be installed in the server if necessary. Physically, each server has only two connections in the SAN, but logically, the storage system is accessible through four paths - each HBA provides access to two connection points on the storage system, separately for each processor module (this feature provides a double connection of the switch to the storage system). In this diagram, the most unreliable device is the server. Two switches provide reliability of the order of 99.99%, but the server may fail for various reasons. If highly reliable operation of the entire system is required, the servers are combined into a cluster, the above diagram does not require any hardware addition to organize such work and is considered the reference scheme of the SAN organization. The simplest case is the servers connected in a single way through one switch to the storage system. However, the storage system with two processor modules must be connected to the switch with at least one channel for each module - the remaining ports can be used for direct connection of servers to the storage system, which is sometimes necessary. And do not forget that the SAN can be built not only on the basis of FibreChannel, but also on the basis of iSCSI protocol - at the same time, you can use only standard ethernet devices for switching, which reduces the cost of the system, but has a number of additional disadvantages (specified in the section on iSCSI ) Also interesting is the ability to load servers from the storage system - it is not even necessary to have internal hard drives in the server. Thus, the task of storing any data is finally removed from the servers. In theory, a specialized server can be turned into an ordinary number crusher without any drives, the defining blocks of which are central processors, memory, as well as interfaces to interact with the outside world, such as Ethernet and FibreChannel ports. Some semblance of such devices are modern blade servers.
I would like to note that the devices that can be connected to the SAN are not limited only to disk storage systems - they can be disk libraries, tape libraries (tape drives), devices for storing data on optical disks (CD / DVD, etc.) and many others.
Of the minuses of SAN, we note only the high cost of its components, but the advantages are undeniable:
* High reliability of access to data located on external storage systems. Independence of SAN topology from used storage systems and servers.
* Centralized data storage (reliability, security).
* Convenient centralized management of switching and data.
* Transfer intensive I / O traffic to a separate network, offloading LAN.
* High speed and low latency.
* Scalability and flexibility logical structure San
* Geographically, SAN sizes, unlike classic DASs, are virtually unlimited.
* Ability to quickly distribute resources between servers.
* Ability to build fault-tolerant cluster solutions at no additional cost based on the existing SAN.
* Simple backup scheme - all data is in one place.
* The presence of additional features and services (snapshots, remote replication).
* High security SAN.
Finally
I think we have adequately covered the main range of issues related to modern storage systems. Let's hope that such devices will even more rapidly develop functionally, and the number of data management mechanisms will only grow.
In conclusion, we can say that NAS and SAN solutions are currently experiencing a real boom. The number of manufacturers and the variety of solutions are increasing, and technical literacy of consumers is growing. We can safely assume that in the near future in almost every computing environment, one or another data storage system will appear.
Any data appears before us in the form of information. The meaning of the work of any computing devices is information processing. IN lately its growth volumes are sometimes scary, so storage systems and specialized software will undoubtedly be the most sought-after IT products in the coming years.
How to classify the architecture of storage systems? It seems to me that the relevance of this issue will only grow in the future. How to understand all this variety of offers available on the market? I want to warn you right away that this post is not intended for the lazy or those who do not want to read a lot.
It is possible to classify storage systems quite successfully, similar to how biologists build family ties between species of living organisms. If you want, you can call it the "tree of life" of the world of information storage technologies.
The construction of such trees helps to better understand the world. In particular, you can build a diagram of the origin and development of any types of storage systems, and quickly understand what lies at the basis of any new technology that appears on the market. This allows you to immediately determine the strengths and weaknesses of a solution.
Repositories that allow you to work with information of any kind, architecturally, can be divided into 4 main groups. The main thing is not to get hung up on some things that are confusing. Many people tend to classify platforms based on such “physical” criteria as interconnect (“They all have an internal bus between nodes!”), Or a protocol (“This is a block, or NAS, or multi-protocol system!”), or divided into hardware and software ("This is just software on the server!").
it completely wrong approach to classification. The only true criterion is the software architecture used in a particular solution, since all the basic characteristics of the system depend on it. The remaining components of the storage system depend on which software architecture was chosen by the developers. And from this point of view, “hardware” and “software” systems can only be variations of this or that architecture.
But do not get me wrong, I do not want to say that the difference between them is small. It’s just not fundamental.
And I want to clarify something else before I get down to business. It is common for our nature to ask the questions “And which of this is the best / right?”. There is only one answer to this: "There are better solutions for specific situations or types of workload, but there is no universal ideal solution." Exactly features of the load dictate the choice of architecture, and nothing else.
By the way, I recently participated in a funny conversation on the topic of data centers that work exclusively on flash drives. I am impressed with passion in any manifestations, and it is clear that flash is beyond competition in situations where performance and latency play a decisive role (among many other factors). But I must admit that my interlocutors were wrong. We have one client, many people use his services every day without even realizing it. Can he switch to flash completely? Not.

This is a great customer. And here is another, HUGE, 10 times more. And again, I can’t agree that this client can switch exclusively to flash:
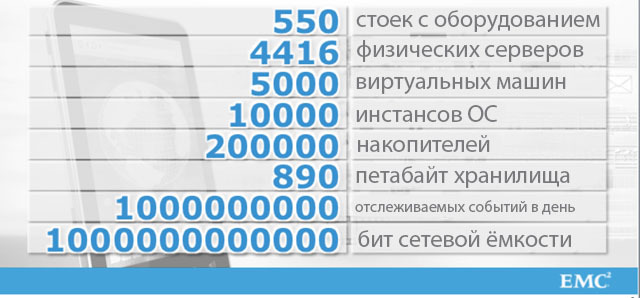
Usually, as a counterargument, they say that in the end the flash will reach such a level of development that it will eclipse magnetic drives. With the caveat that flash will be used paired with deduplication. But not in all cases it is advisable to apply deduplication, as well as compression.
Well, on the one hand, flash memory will become cheaper, to a certain limit. It seemed to me that this would happen somewhat faster, but SSDs with a capacity of 1 TB for $ 550 are already available, this is a big progress. Of course, the developers of traditional hard drives are also not idle. In the 2017-2018 region, competition should intensify, as new technologies will be introduced (most likely, phase shift and carbon nanotubes). But the point is not at all the confrontation between flash and hard drives, or even software and hardware solutions, the main thing is architecture.
It is so important that it is almost impossible to change the architecture of storage without modifying almost everything. That is, in fact, without creating a new system. Therefore, storages are usually created, developed and die within the framework of a single initially selected architecture.
Four types of storage
Type 1. Clustered Architecture. They are not designed for sharing memory nodes, in fact, all the data is in one node. One of the features of the architecture is that sometimes devices “intersect” (trespass), even if they are “accessible from several nodes”. Another feature is that you can select a machine, tell it some drives and say "this machine has access to data on these media." The blue in the figure indicates the CPU / memory / input-output system, and the green indicate the media on which the data is stored (flash or magnetic drives).
This type of architecture is characterized by direct and very fast access to data. There will be slight delays between machines because I / O mirroring and caching are used to ensure high availability. But in general, relatively direct access is provided along the code branch. Software storages are quite simple and have a low latency, so they often have rich functionality, data services are easily added. Not surprisingly, most startups start with such repositories.
Please note that one of the varieties of this type of architecture is PCIe equipment for non-HA servers (Fusion-IO, XtremeCache expansion cards). If we add distributed storage software, coherence, and an HA model to it, then such software storage will correspond to one of the four types of architectures described in this post.
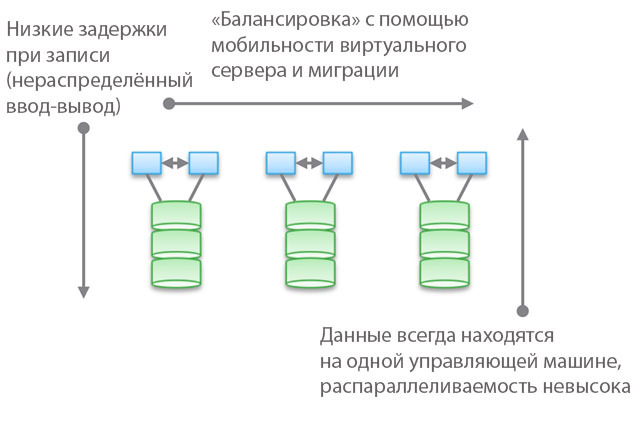
The use of “federated models” helps to improve the horizontal scalability of this type of architecture from a management point of view. These models can use different approaches to increasing data mobility to rebalance between host machines and storage. For example, within VNX, this means “VDM mobility”. But I think that calling it “horizontally scalable architecture” will be a stretch. And, in my experience, most customers share this view. The reason for this is the location of data on one control machine, sometimes - “in a hardware cabinet” (behind an enclosure). They can be moved, but they will always be in one place. On the one hand, this allows you to reduce the number of cycles and recording delay. On the other hand, all your data is served by a single control machine (indirect access from another machine is possible). Unlike the second and third types of architectures, which we will discuss below, balancing and tuning play an important role here.
Objectively speaking, this abstract federal level entails a slight increase in latency because it uses software redirection. This is similar to complicating the code and increasing latency in types of architectures 2 and 3, and partly eliminates the advantages of the first type. As a concrete example, UCS Invicta, a kind of "Silicon Storage Routers". In the case of NetApp FAS 8.x, working in cluster mode, the code is pretty complicated by the introduction of a federated model.
Products using cluster architectures - VNX or NetApp FAS, Pure, Tintri, Nimble, Nexenta and (I think) UCS Invicta / UCS. Some are “hardware” solutions, others are “purely software”, and others are “software in the form of hardware complexes”. All of them are VERY different in terms of data processing (in Pure and UCS Invicta / Whiptail, only flash drives are used). But architecturally, all of the products listed are related. For example, you configure data processing services exclusively for backup, the software stack becomes the Data Domain, your NAS acts as the best backup tool in the world - and this is also the “first type” architecture.
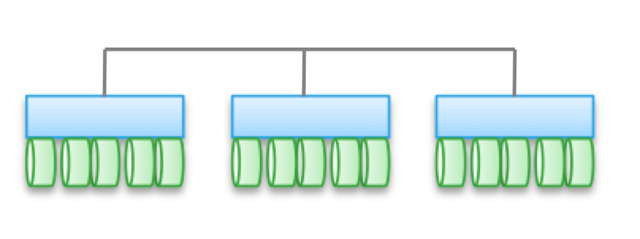
Type 2. Weakly interfaced, horizontally scaled architectures. Nodes do not share memory, but the data itself is for several nodes. This architecture implies the use of more internatal connections to record data, which increases the number of cycles. Although write operations are distributed, they are always coherent.
Note that these architectures do not provide high availability for the node due to copying and data distribution operations. For the same reason, there are always more I / O operations compared to simple cluster architectures. So the performance is slightly lower, despite the small level of recording delay (NVRAM, SSD, etc.).
In some varieties of architectures, nodes are often assembled into subgroups, while the rest are used to manage subgroups (metadata nodes). But the effects described above for “federated models” are manifested here.

Such architectures are quite easy to scale. Since data is stored in several places and can be processed by multiple nodes, these architectures can be great for tasks when distributed reading is required. In addition, they combine well with server / storage software. But it’s best to use similar architectures under transactional loads: due to their distributed nature, you can not use a HA server, and weak conjugation allows you to bypass Ethernet.
This type of architecture is used in products such as EMC ScaleIO and Isilon, VSAN, Nutanix, and Simplivity. As in the case of Type 1, all these solutions are completely different from each other.
Weak connectivity means that often these architectures can significantly increase the number of nodes. But, let me remind you, they DO NOT use memory together, the code of each node works independently of the others. But the devil, as they say, in detail:
- The more recording operations are distributed, the higher the latency and lower the efficiency of the IOP. For example, in Isilon, the distribution level is very high for files, and although with each update the delays are reduced, but still it will never demonstrate the highest performance. But Isilon is extremely strong in terms of parallelization.
- If you reduce the degree of distribution (albeit with a large number of nodes), then the delays may decrease, but at the same time you will reduce your ability to parallelize data reading. For example, VSAN uses the “virtual machine as an object” model, which allows you to run multiple copies. It would seem that a virtual machine should be accessible to a specific host. But, in fact, in VSAN it “shifts” towards the node that stores its data. If you use this solution, you can see for yourself how increasing the number of copies of an object affects latency and I / O operations throughout the system. Hint: more copies \u003d higher load on the system as a whole, and the dependence is non-linear, as you might expect. But for VSAN, this is not a problem due to the advantages of the virtual machine as an object model.
- It is possible to achieve low latency under conditions of high scaling and parallelization during reading, but only if data and writing are precisely separated. a large number copies. This approach is used in ScaleIO. Each volume is divided into a large number of fragments (1 MB by default), which are distributed across all involved nodes. The result is an extremely high read and redistribution speed along with powerful parallelization. The write delay can be less than 1 ms when using the appropriate network infrastructure and SSD / PCIe Flash in the cluster nodes. However, each write operation is performed in two nodes. Of course, unlike VSAN, a virtual machine is not considered an object here. But if considered, then scalability would be worse.
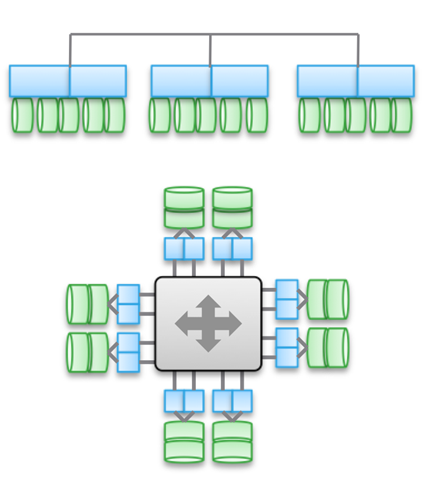
Type 3. Strongly interfaced, horizontally scaled architectures. This uses memory sharing (for caching and some types of metadata). Data is distributed across various nodes. This type of architecture involves the use of a very large number of internode connections for all types of operations.
Sharing memory is the cornerstone of these architectures. Historically, through all control machines symmetrical I / O operations can be carried out (see illustration). This allows you to rebalance the load in case of any malfunctions. This idea was laid in the foundation of products such as Symmetrix, IBM DS, HDS USP and VSP. They provide shared access to the cache, so the I / O procedure can be controlled from any machine.
The top diagram in the illustration reflects the EMC XtremIO architecture. At first glance, it is similar to Type 2, but it is not. In this case, the model of shared distributed metadata implies the use of IB and remote direct memory access so that all nodes have access to the metadata. In addition, each node is an HA pair. As you can see, Isilon and XtremIO are very architecturally different, although this is not so obvious. Yes, both have horizontally scaled architectures, and both use IB for interconnect. But in Isilon, unlike XtremIO, this is done to minimize latency when exchanging data between nodes. It is also possible to use Ethernet in Isilon for communication between nodes (in fact, this is how a virtual machine works on it), but this increases delays in input-output operations. As for XtremIO, remote direct memory access is of great importance for its performance.
By the way, do not be fooled by the presence of two diagrams in the illustration - in fact, they are the same architecturally. In both cases, pairs of HA controllers, shared memory, and very low latency interconnects are used. By the way, VMAX uses a proprietary inter-component bus, but in the future it will be possible to use IB.
Highly coupled architectures are characterized by the high complexity of the program code. This is one of the reasons for their low prevalence. Excessive software complexity also affects the number of data processing services that are added, as this is a more difficult computing task.
The advantages of this type of architecture include fault tolerance (symmetrical I / O in all control machines), as well as, in the case of XtremIO, great opportunities in the field of AFA. Once we are talking about XtremIO again, it is worth mentioning that its architecture implies the distribution of all data processing services. It is also the only AFA solution on the market with a horizontally scaled architecture, although dynamic adding / disabling nodes has not yet been implemented. Among other things, XtremIO uses "natural" deduplication, that is, it is constantly active and "free" in terms of performance. True, all this increases the complexity of system maintenance.
It is important to understand the fundamental difference between Type 2 and Type 3. The more interconnected the architecture, the better and more predictable it is to ensure low latency. On the other hand, within the framework of such an architecture, it is more difficult to add nodes and scale the system. After all, when you use shared access to memory, it is a single, highly conjugated distributed system. The complexity of decisions is growing, and with it the likelihood of errors. Therefore, VMAX can have up to 16 control cars in 8 engines, and XtemIO - up to 8 cars in 4 X-Brick (it will soon increase to 16 cars in 8 blocks). Quadrupling, or even doubling these architectures is an incredibly difficult engineering challenge. For comparison, VSAN can be scaled to “vSphere cluster size” (now 32 nodes), Isilon can contain more than 100 nodes, and ScaleIO allows you to create a system of more than 1000 nodes. Moreover, all this is an architecture of the second type.
Again, I want to emphasize that architecture is implementation independent. The above products use both Ethernet and IB. Some are purely software solutions, others are hardware-software complexes, but at the same time they are united by architectural schemes.
Despite the variety of interconnects, the use of distributed recording plays an important role in all the examples given. This allows you to achieve transactionality and atomicity, but careful monitoring of data integrity is necessary. It is also necessary to solve the problem of the growth of the “failure area”. These two points limit the maximum possible degree of scaling of the described types of architectures.
A small check on how carefully you read all of the above: What type of Cisco UCS Invicta - 1 or 3 belongs to? Physically, it looks like Type 3, but this is a set of C-series USC servers connected via Ethernet, running the Invicta software stack (formerly Whiptail). Hint: look at the architecture, not the specific implementation 🙂
In the case of UCS Invicta, the data is stored in each node (UCS server with flash drives based on MLC). A single non-HA node, which is a separate server, can directly transmit a logical unit number (LUN). If you decide to add more nodes, it is possible that the system scales poorly, like ScaleIO or VSAN. All this brings us to Type 2.
However, the increase in the number of nodes, apparently, is done through configuration and migration to the “Invicta Scaling Appliance”. With this configuration, you have several “Silicon Storage Routers” (SSRs) and an address storage of several hardware nodes. Data is accessed through a single SSR node, but this can be done through another node that works as an HA pair. The data itself is always on the only UCS node in the C series. So what kind of architecture is this? No matter what the solution looks like physically, it is Type 1. The SSR is a cluster (maybe more than 2). In the Scaling Appliance configuration, each UCS server with MLC drives performs a function similar to VNX or NetApp FAS - disk storage. Although not connected via SAS, the architecture is similar.
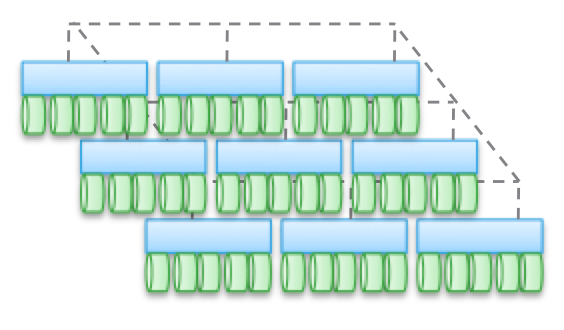
Type 4. Distributed architectures without sharing any resources. Despite the fact that the data is distributed across different nodes, this is done without any transactionality. Usually, data is stored on one node and live there, and from time to time copies are made on other nodes, for the sake of security. But these copies are not transactional. This is the key difference between this type of architecture and Type 2 and 3.
Communication between non-HA nodes is via Ethernet, as it is cheap and universal. Distribution by nodes is mandatory and from time to time. The “correctness” of the data is not always respected, but the software stack is checked quite often to ensure the correctness of the data used. For some types of load (for example, HDFS), data is distributed so as to be in memory at the same time as the process for which it is required. This property allows us to consider this type of architecture as the most scalable among all four.
But this is far from the only advantage. Such architectures are extremely simple; they are very easy to manage. They are in no way dependent on equipment and can be deployed on the cheapest hardware. These are almost always exclusively software solutions. This type of architecture is just as easy to handle with petabytes of data as terabytes with other data. Objects and non-POSIX file systems are used here, and both are often located on top of the local file system of each ordinary node.
These architectures can be combined with blocks and transactional models of data presentation based on NAS, but this greatly limits their capabilities. No need to create a transactional stack by placing Type 1, 2, or 3 on top of Type 4.
Best of all, these architectures are "revealed" on those tasks for which some restrictions are not peculiar.
Above, I gave an example with a very large client with 200,000 drives. Services such as Dropbox, Syncplicity, iCloud, Facebook, eBay, YouTube and almost all Web 2.0 projects are based on repositories built using the fourth type of architecture. All processed information in Hadoop clusters is also contained in Type 4 repositories. In general, in the corporate segment these are not very common architectures, but they quickly gain popularity.
Type 4 is the basis of products such as AWS S3 (by the way, no one outside AWS knows how EBS works, but I’m willing to argue that it is Type 3), Haystack (used on Facebook), Atmos, ViPR, Ceph, Swift ( used in Openstack), HDFS, Centera. Many of the listed products can take a different form, the type of specific implementation is determined using their API. For example, the ViPR object stack can be implemented through the S3, Swift, Atmos, and even HDFS object APIs! And in the future, Centera will also be on this list. For some, this will be obvious, but Atmos and Centera will be used for a long time, however, in the form of APIs, and not specific products. Implementations may change, but the APIs remain unshakable, which is very good for customers.
I want to draw your attention once again to the fact that the “physical embodiment” can be confusing, and you will mistakenly classify Type 4 architectures as Type 2, since they often look the same. At the physical level, a solution may look like ScaleIO, VSAN, or Nutanix, although these will be just Ethernet servers. And the presence or absence of transactionality will help to classify a particular solution correctly.
And now I offer you a second verification test. Let's look at the UCS Invicta architecture. Physically, this product looks like Type 4 (servers connected via Ethernet), but it is impossible to scale it architecturally to the corresponding loads, since it is actually Type 1. Moreover, Invicta, like Pure, was developed for AFA.
Please accept my sincere gratitude for your time and attention if you have read up to this place. I re-read the above - it’s amazing that I managed to get married and have children 🙂
Why did I write all this?
In the world of IT storage, they occupy a very important place, a sort of "kingdom of mushrooms." The variety of products on offer is very large, and this only benefits the whole business. But you need to be able to understand all this, do not allow yourself to cloud your mind with marketing slogans and nuances of positioning. For the benefit of both customers and the industry itself, it is necessary to simplify the process of building storage. Therefore, we are working hard to make the ViPR controller an open, free platform.
But the repository itself is hardly exciting. What I mean? Imagine a kind of abstract pyramid, on top of which is a "user". Below are the "applications" designed to serve the "user". Even lower is the “infrastructure” (including SDDC) serving the “applications” and, accordingly, the “user”. And at the very bottom of the "infrastructure" is the repository.
That is, you can imagine the hierarchy in this form: User-\u003e Application / SaaS-\u003e PaaS-\u003e IaaS-\u003e Infrastructure. So: in the end, any application, any PaaS stack must calculate or process some kind of information. And these four types of architectures are designed to work with different types of information, different types of load. In the hierarchy of importance, information immediately follows the user. The purpose of the existence of the application is to enable the user to interact with the information he needs. That is why storage architecture is so important in our world.
This entry was posted in Uncategorized by the author. Bookmark it.And other things, the data transmission medium and the servers connected to it. It is usually used by large enough companies with well-developed IT infrastructure for reliable data storage and high-speed access to them.
Simplified, storage is a system that allows you to distribute reliable servers fast drives variable capacitance with different devices data storage.
A bit of theory.
The server can be connected to the data warehouse in several ways.
The first and simplest one is DAS, Direct Attached Storage (direct connection), we put drives into the server, or an array into the server adapter, and we get a lot of gigabytes of disk space with relatively quick access, and when using a RAID array - sufficient reliability, although spears on the topic of reliability have been breaking for a long time.
However, this use of disk space is not optimal - on one server the place runs out, on the other there is still a lot of it. The solution to this problem is NAS, Network Attached Storage (network-attached storage). However, with all the advantages of this solution - flexibility and centralized management - there is one significant drawback - the speed of access, the network of 10 gigabits is not yet implemented in all organizations. And we are approaching a storage network.
The main difference between a SAN and a NAS (in addition to the letter order in abbreviations) is how the connected resources are seen on the server. If the NAS resources are connected to the NFS or SMB protocols, in the SAN we get a connection to the disk, with which we can work at the level of block I / O operations, which is much faster network connection (plus an array controller with a large cache adds speed on many operations).
Using SAN, we combine the advantages of DAS - speed and simplicity, and NAS - flexibility and controllability. Plus, we get the ability to scale storage systems until there is enough money, while simultaneously killing several more birds with one stone, which are not immediately visible:
* remove restrictions on the connection range of SCSI devices, which are usually limited to a wire of 12 meters,
* reduce backup time,
* we can boot from SAN,
* in case of refusal from NAS we unload a network,
* we get a high input-output speed due to optimization on the storage system side,
* we get the opportunity to connect several servers to one resource, this gives us the following two birds with one stone:
- we fully use the capabilities of VMWare - for example, VMotion (virtual machine migration between physical machines) and others like them,
- we can build fault-tolerant clusters and organize geographically distributed networks.
What does it give?
In addition to developing the budget for optimizing the storage system, we get, in addition to what I wrote above:
* increase in productivity, load balancing and high availability of storage systems due to several ways to access arrays;
* savings on disks by optimizing the location of information;
* accelerated recovery from failures - you can create temporary resources, deploy a backup to them and connect servers to them, and restore information yourself without haste, or transfer resources to other servers and calmly deal with dead iron;
* Reduced backup time - thanks to the high transfer speed, you can back up to the tape library faster, or even take a snapshot (snapshot) from the file system and safely archive it;
* disk space on demand - when we need it - you can always add a couple of shelves to the storage system.
* reduce the cost of storing a megabyte of information - of course, there is a certain threshold from which these systems are cost-effective.
* A reliable place to store mission critical and business critical data (without which the organization cannot exist and function normally).
* I want to mention VMWare separately - all the chips like migrating virtual machines from server to server and other goodies are available only on the SAN.
What does it consist of?
As I wrote above - SHD consists of storage devices, transmission media and connected servers. Let's consider in order:
Data storage systems usually consist of hard drives and controllers, in a self-respecting system, usually only 2 - 2 controllers, 2 paths to each disk, 2 interfaces, 2 power supplies, 2 administrators. Among the most respected system manufacturers, mention should be made of HP, IBM, EMC, and Hitachi. Here I will quote one representative of EMC at the seminar - “HP makes excellent printers. Well, let her make them! ”I suspect that HP also loves EMC. Competition between manufacturers is serious, however, as elsewhere. The consequences of competition are sometimes sane prices per megabyte of storage system and problems with compatibility and support of competitor standards, especially for old equipment.
Data transfer medium.
Typically, SANs are built on optics, which currently gives a speed of 4, sometimes 8 gigabits per channel. When building, specialized hubs were used before, now there are more switches, mainly from Qlogic, Brocade, McData and Cisco (I have never seen the last two on the sites). Cables are used traditional for optical networks - single-mode and multi-mode, single-mode longer.
Inside, FCP is used - Fiber Channel Protocol, a transport protocol. Typically, classic SCSI runs inside it, and FCP provides addressing and delivery. There is an option with connecting via a regular network and iSCSI, but it usually uses (and heavily loads) a local, and not dedicated for data transfer network, and requires adapters with iSCSI support, well, the speed is slower than in optics.
There is also a smart word topology, which is found in all textbooks on SAN. There are several topologies, the simplest option is point to point, we connect 2 systems. This is not DAS, but a spherical horse in vacuum is the simplest version of SAN. Next comes the controlled loop (FC-AL), it works on the principle of “pass on” - the transmitter of each device is connected to the receiver of the subsequent one, the devices are closed in a ring. Long chains tend to initialize for a long time.
Well, the final option is a switched fabric (Fabric), it is created using switches. The structure of connections is built depending on the number of connected ports, as in the construction of a local network. The basic construction principle is that all paths and connections are duplicated. This means that there are at least 2 different paths to each device on the network. Here, the word topology is also used, in the sense of organizing a device connection diagram and connecting switches. In this case, as a rule, switches are configured so that the servers do not see anything other than the resources intended for them. This is achieved by creating virtual networks and is called zoning, the closest analogy is VLAN. Each device on the network is assigned an analog MAC address on the Ethernet network, it is called WWN - World Wide Name. It is assigned to each interface and each resource (LUN) of storage systems. Arrays and switches can distinguish between WWN access for servers.
Server Connect to storage via HBA - Host Bus Adapters. By analogy with network cards, there are one-, two-, and four-port adapters. The best "dog breeders" recommend installing 2 adapters per server, this allows both load balancing and reliability.
And then resources are cut into the storage systems, they are the LUNs for each server and a place is left in the reserve, everything is turned on, the system installers prescribe the topology, catch glitches in the configuration of switches and access, everything starts and everyone lives happily ever after *.
I specifically do not touch on different types of ports in the optical network, whoever needs it - he already knows or reads, who does not need it - just hammer his head. But as usual, if the port type is incorrectly set, nothing will work.
From experience.
Usually, when creating a SAN, arrays with several types of disks are ordered: FC for high-speed applications, and SATA or SAS for not very fast ones. Thus, 2 disk groups with different megabyte cost are obtained - expensive and fast, and slow and sad cheap. Usually, all databases and other applications with active and fast I / O are hung on the fast one, while file resources and everything else are hung on the slow one.
If a SAN is created from scratch, it makes sense to build it on the basis of solutions from one manufacturer. The fact is that, despite the declared compliance with standards, there are underwater rakes of the equipment compatibility problem, and not the fact that part of the equipment will work with each other without dancing with a tambourine and consulting with manufacturers. Usually, to tackle such problems, it is easier to call an integrator and give him money than to communicate with manufacturers switching arrows.
If the SAN is created on the basis of the existing infrastructure, everything can be complicated, especially if there are old SCSI arrays and an old technology zoo from different manufacturers. In this case, it makes sense to call for help from the terrible beast of an integrator who will unravel compatibility problems and make a third villa in the Canary Islands.
Often when creating storage systems, firms do not order manufacturer support for the system. This is usually justified if the company has a staff of competent competent admins (who have already called me a teapot 100 times) and a fair amount of capital, which makes it possible to purchase spare parts in the required quantities. However, competent administrators are usually lured by integrators (I saw it myself), but they don’t allocate money for the purchase, and after failures, a circus begins with the cries of “Let me fire everyone!” Instead of calling the support and the engineer arriving with a spare part.
Support usually comes down to replacing dead disks and controllers, and to adding disk shelves and new servers to the system. A lot of trouble happens after a sudden prevention of the system by local specialists, especially after a complete shutdown and disassembly-assembly of the system (and this happens).
About VMWare. As far as I know (virtualization specialists correct me), only VMWare and Hyper-V have functionality that allows you to transfer virtual machines between physical servers on the fly. And for its implementation, it is required that all servers between which the virtual machine moves are connected to the same disk.
About clusters. Similar to the case with VMWare, the systems I know of building failover clusters (Sun Cluster, Veritas Cluster Server) that I know require storage connected to all systems.
While writing an article - they asked me - in which RAIDs do drives usually combine?
In my practice, they usually made either RAID 1 + 0 on each disk shelf with FC disks, leaving 1 spare disk (Hot Spare) and cut LUNs from this piece for tasks, or did RAID5 from slow disks, again leaving 1 disk to replace. But here the question is complex, and usually the way to organize disks in an array is selected for each situation and justified. The same EMC for example goes even further, and they have additional setting array for applications working with it (for example, under OLTP, OLAP). I didn’t dig so deeply with the other vendors, but I guess everyone has a fine-tuning.
* before the first major failure, after which support is usually bought from the manufacturer or supplier of the system.
DAS, SAN, NAS - magic abbreviations, without which not a single article or a single analytical study of storage systems can do. They serve as the designation of the main types of connection between storage systems and computing systems.
Das (direct-attached storage) - device external memorydirectly connected to the main computer and used only by it. The simplest example of DAS is the built-in hDD. To connect the host with external memory in a typical DAS configuration, SCSI is used, the commands of which allow you to select a specific data block on a specified disk or mount a specific cartridge in a tape library.
DAS configurations are acceptable for storage, capacity, and reliability requirements. DAS does not provide the ability to share storage capacity between different hosts, and even less the ability to share data. Installing such storage devices is a cheaper option compared to network configurations, however, given the large organizations, this type of storage infrastructure cannot be considered optimal. Many DAS connections mean islands of external memory that are scattered and scattered throughout the company, the excess of which cannot be used by other host computers, which leads to an inefficient waste of storage capacity in general.
In addition, with such a storage organization, there is no way to create a single point of management of external memory, which inevitably complicates the processes of data backup / recovery and creates a serious problem of information protection. As a result, the total cost of ownership of such a storage system can be significantly higher than the more complex at first glance and initially more expensive network configuration.
San
Today, speaking of an enterprise-level storage system, we mean network storage. Better known to the general public is the storage network - SAN (storage area network). SAN is a dedicated network of storage devices that allows multiple servers to use the total resource of external memory without the load on the local network.

SAN is independent of the transmission medium, but at the moment the actual standard is Fiber Channel (FC) technology, which provides a data transfer rate of 1-2 Gb / s. Unlike traditional SCSI-based transmission media, providing connectivity of no more than 25 meters, Fiber Channel allows you to work at distances up to 100 km. Fiber Channel network media can be either copper or fiber.
Disk can connect to the storage network rAID arrays, simple disk arrays, (the so-called Just a Bunch of Disks - JBOD), tape or magneto-optical libraries for data backup and archiving. The main components for organizing a SAN network in addition to the storage devices themselves are adapters for connecting servers to a Fiber Channel network (host bus adapter - NVA), network devices to support one or another FC network topology, and specialized software tools for managing a storage network. These software systems can be performed both on a general-purpose server and on the storage devices themselves, although sometimes some of the functions are transferred to a specialized thin server for managing the storage network (SAN appliance).
The goal of SAN software is primarily to centrally manage the storage network, including configuring, monitoring, controlling and analyzing network components. One of the most important is the function of access control to disk arrays, if heterogeneous servers are stored in the SAN. Storage networks allow multiple servers to simultaneously access multiple disk subsystems, mapping each host to specific disks on a specific disk array. For different operating systems, it is necessary to stratify the disk array into “logical units” (logical units - LUNs), which they will use without conflicts. The allocation of logical areas may be needed to organize access to the same data for a certain pool of servers, for example, servers of the same workgroup. Special software modules are responsible for supporting all these operations.
The attractiveness of storage networks is explained by the advantages that they can give organizations demanding the efficiency of working with large volumes of data. A dedicated storage network offloads the main (local or global) network of computing servers and client workstations, freeing it from data input / output streams.

This factor, as well as the high-speed transmission medium used for SAN, provide increased productivity of data exchange processes with external storage systems. SAN means consolidation of storage systems, creation of a single pool of resources on different media, which will be shared by all computing power, and as a result, the required external memory capacity can be provided with fewer subsystems. In SAN, data is backed up from disk subsystems to tapes outside the local network and therefore becomes more efficient - one tape library can be used to back up data from several disk subsystems. In addition, with the support of the corresponding software, it is possible to implement direct backup in the SAN without the participation of the server, thereby unloading the processor. The ability to deploy servers and memory over long distances meets the needs of improving the reliability of enterprise data warehouses. Consolidated data storage in the SAN scales better because it allows you to increase storage capacity independently of servers and without interrupting their work. Finally, the SAN enables centralized management of a single pool of external memory, which simplifies administration.
Of course, storage networks are an expensive and difficult solution, and despite the fact that all leading suppliers today produce Fiber Channel-based SAN devices, their compatibility is not guaranteed, and choosing the right equipment poses a problem for users. Additional costs will be required for the organization of a dedicated network and the purchase of management software, and the initial cost of the SAN will be higher than the organization of storage using DAS, but the total cost of ownership should be lower.
NAS
Unlike SAN, NAS (network attached storage) is not a network, but a network storage device, more precisely, a dedicated file server with a disk subsystem connected to it. Sometimes an optical or tape library may be included in the NAS configuration. The NAS device (NAS appliance) is directly connected to the network and gives hosts access to files on its integrated external memory subsystem. The emergence of dedicated file servers is associated with the development of the NFS network file system by Sun Microsystems in the early 90s, which allowed client computers on the local network to use files on a remote server. Then Microsoft came up with a similar system for the Windows environment - the Common Internet File System. NAS configurations support both of these systems, as well as other IP-based protocols, providing file sharing for client applications.

The NAS device resembles the DAS configuration, but differs fundamentally from it in that it provides access at the file level, not data blocks, and allows all applications on the network to share files on their disks. NAS specifies a file in the file system, the offset in this file (which is represented as a sequence of bytes) and the number of bytes to read or write. A request to a NAS device does not determine the volume or sector on the disk where the file is located. The task of the operating system of a NAS device is to translate a call to a specific file into a request at the data block level. File access and the ability to share information are convenient for applications that should serve many users at the same time, but do not require downloading very large amounts of data for each request. Therefore, it is becoming common practice to use NAS for Internet applications, Web services or CAD, in which hundreds of specialists work on one project.
The NAS option is easy to install and manage. Unlike the storage network, the installation of a NAS device does not require special planning and the cost of additional management software - just connect the file server to the local network. The NAS frees servers on the network from storage management tasks, but does not offload network traffic, since data is exchanged between general-purpose servers and the NAS on the same local network. One or more can be configured on the NAS file systems, each of which is assigned a specific set of volumes on disk. All users of the same file system are allocated some disk space on demand. Thus, the NAS provides more efficient organization and use of memory resources compared to DAS, since the directly connected storage subsystem serves only one computing resource, and it may happen that one server on the local network has too much external memory, while another is running out of disk space. But you cannot create a single pool of storage resources from several NAS devices, and therefore an increase in the number of NAS nodes in the network will complicate the management task.
NAS + SAN \u003d?
Which form of storage infrastructure to choose: NAS or SAN? The answer depends on the capabilities and needs of the organization, however, it is basically incorrect to compare or even contrast them, since these two configurations solve different problems. File access and information sharing for applications on heterogeneous server platforms on the local network is the NAS. High-performance block access to databases, storage consolidation, guaranteeing its reliability and efficiency - these are SANs. In life, however, everything is more complicated. NAS and SAN often already coexist or must be simultaneously implemented in the distributed IT infrastructure of the company. This inevitably creates management and storage utilization problems.
Today, manufacturers are looking for ways to integrate both technologies into a single network storage infrastructure that will consolidate data, centralize backups, simplify general administration, scalability and data protection. The convergence of NAS and SAN is one of the most important trends of recent times.
The storage network allows you to create a single pool of memory resources and allocate at the physical level the necessary quota of disk space for each of the hosts connected to the SAN. The NAS server provides data sharing in the file system by applications on different operating platforms, solving the problems of interpreting the file system structure, synchronizing and controlling access to the same data. Therefore, if we want to add to the storage network the ability to separate not only physical disks, but also the logical structure of file systems, we need an intermediate management server to implement all the functions of network protocols for processing requests at the file level. Hence the general approach to combining SAN and NAS using a NAS device without an integrated disk subsystem, but with the ability to connect storage network components. Such devices, which are called NAS gateways by some manufacturers and by other NAS head units, become a buffer between the local network and the SAN, providing access to data in the SAN at the file level and sharing information on the storage network.
Summary
Building unified network systems that combine the capabilities of SAN and NAS is just one of the steps towards the global integration of enterprise storage systems. Disk arrays connected directly to individual servers no longer satisfy the needs of large organizations with complex distributed IT infrastructures. Today, just storage networks based on high-performance, but specialized Fiber Channel technology are considered not only a breakthrough, but also a source of headache due to the complexity of installation, problems with hardware and software support from different vendors. However, the fact that storage resources must be unified and networked is no longer in doubt. Ways are being sought for optimal consolidation. Hence the activation of manufacturers of solutions that support various options for transferring storage networks to the IP protocol]. Hence the great interest in various implementations of the concept of storage virtualization. Leading players in the storage market not only combine all their products under a common heading (TotalStorage for IBM or SureStore for HP), but formulate their own strategies for creating consolidated, network storage infrastructures and protect corporate data. The key role in these strategies will be played by the idea of \u200b\u200bvirtualization, supported mainly at the level of powerful software solutions for centralized management of distributed storage. In such initiatives as IBM's StorageTank, HP's Federated Storage Area Management, EMC's E-Infrostructure, software plays a crucial role.
If Servers are universal devices that perform in most cases
- either an application server function (when executed on the server special programs, and there are intensive calculations)
- either a file server function (i.e. a certain place for centralized storage of data files)
then SHD (Data Storage Systems) - devices specially designed to perform such server functions as data storage.
The need to purchase storage
usually arises in sufficiently mature enterprises, i.e. those who think about how
- store and manage information, the company's most valuable asset
- ensure business continuity and protection against data loss
- increase adaptability of IT infrastructure
Storage and virtualization
Competition forces SMEs to work more efficiently, without downtime and with high efficiency. Change of production models, tariff plans, types of services is happening more and more often. The whole business of modern companies is “tied” to information technology. Business needs change quickly, and instantly affect IT - requirements for reliability and adaptability of IT infrastructure are growing. Virtualization provides these capabilities, but it requires low-cost, easy-to-maintain storage systems.
Storage classification by connection type
Das. The first disk arrays connected to the servers via SCSI. At the same time, one server could work with only one disk array. This is a direct storage connection (DAS - Direct Attached Storage).
NAS. For a more flexible organization of the structure of the data center - so that every user can use any storage system - it is necessary to connect the storage system to the local network. This is NAS - Network Attached Storage). But the data exchange between the server and the storage system is many times more intense than between the client and the server, so in this version there were objective difficulties associated with the bandwidth of the Ethernet network. And from a security point of view, it’s not entirely correct to show storage systems in a shared network.
San. But you can create your own, separate, high-speed network between servers and storage. Such a network was called SAN (Storage Area Network). Performance is ensured by the fact that the physical transmission medium there is optics. Special adapters (HBA) and optical FC switches provide data transmission at speeds of 4 and 8Gbit / s. The reliability of such a network was enhanced by redundancy (duplication) of channels (adapters, switches). The main disadvantage is the high price.
iSCSI. With the advent of low-cost Ethernet technologies 1Gbit / s and 10Gbit / s, optics with a transmission speed of 4Gbit / s does not look so attractive, especially considering the price. Therefore, iSCSI (Internet Small Computer System Interface) protocol is increasingly being used as a SAN environment. An iSCSI SAN can be built on any fast enough physical basis that supports IP.
Classification of Storage Systems by Application:
| the class | description |
| personal |
Most often they are a regular 3.5 "or 2.5" or 1.8 "hard drive, placed in a special case and equipped with USB and / or FireWire 1394 and / or Ethernet, and / or eSATA interfaces. |
small workgroup  |
Usually this is a stationary or portable device, in which you can install several (most often from 2 to 5) SATA hard drives, with or without hot-swappability, having an Ethernet interface. Disks can be organized into RAID arrays of various levels to achieve high reliability of storage and access speed. The storage system has a specialized OS, usually based on Linux, and allows you to differentiate the level of access by user name and password, organize quotas for disk space, etc. |
|
workgroup |
The device is usually mounted in a 19 "rack (rack-mount) in which you can install 12-24 SATA or SAS hot-swappable HotSwap drives. It has an external Ethernet and / or iSCSI interface. The drives are organized in RAID arrays to achieve high reliability of storage and access speed. Storage comes with specialized software that allows you to differentiate access levels, organize quotas for disk space, organize BackUp ( backup information), etc. Such storage systems are suitable for medium and large enterprises, and are used in conjunction with one or more servers. |
enterprise   |
A stationary device or device mounted in a 19 "rack (rack-mount) in which you can install up to hundreds of hard drives. In addition to the previous class, storage systems may have the ability to build, upgrade, and replace components without stopping the monitoring system. Software can support snapshots and other advanced features. These storage systems are suitable for large enterprises and provide increased reliability, speed and protection of critical data. |
|
high-end enterprise |
In addition to the previous class, storage can support thousands of hard drives. |


The history of the issue.
The first servers combined all functions (like computers) in one package - both computing (application server) and data storage (file server). But as the demand for applications in computing power grows on the one hand, and as the amount of processed data grows on the other hand, it has become simply inconvenient to place everything in one package. It turned out to be more effective to take out disk arrays in separate cases. But here the question arose of connecting the disk array to the server. The first disk arrays connected to the servers via SCSI. But in this case, one server could work with only one disk array. The people wanted a more flexible organization of the structure of the data center - so that any server could use any storage system. Connecting all devices directly to the local network and organizing data exchange via Ethernet is, of course, a simple and universal solution. But the data exchange between servers and storage is many times more intense than between clients and servers, therefore, in this version (NAS - see below) there were objective difficulties associated with the bandwidth of the Ethernet network. There was an idea to create your own separate high-speed network between servers and storage. Such a network was called a SAN (see below). It is similar to Ethernet, only the physical transmission medium there is optics. There are also adapters (HBAs) that are installed in servers and switches (optical). Standards for data transmission speed for optics - 4Gbit / s. With the advent of Ethernet technologies 1Gbit / s and 10Gbit / s, as well as iSCSI protocol, Ethernet is increasingly being used as a SAN environment.