Publication Date
Hello, today we will learn to search for files. Consider a search by name and by file content.
We will search for help using the program total commander. Run the program. In the "Tools" menu, select "Search Files" or press the key combination Alt + F7. The following window will appear.
1. Search by file name.
To find a file by its name, enter the name of the file you are looking for in the "Search for files" field. In the "Search location" field, enter the place where the search will be performed. In order not to enter the path manually, you can click on the "\u003e\u003e" button and select a directory from the list.
In the "Search for file" field, you can enter:
- The whole file name, for example, "test.txt"
- Part of the name "test"
- Search mask. For example, "test. *" Will search for a file with the name test and with any extension. "* .jpeg" - search for all files with the JPEG extension.
It is worth noting that the search implemented in the operating room windows system very similar to the one presented above.
2. Search for files by content
If you need to find a file with specific content, you must also, as in the previous case, select a search location. Next, put a checkmark "With text", and in the opposite field you need to enter the text of interest. If required, make additional settings.
If your search criteria is configured, it’s time to click the “Start Search” button. The program will start working.
The results of the program will be displayed in the same window, it will simply be increased in size. By double-clicking on the file, you can go to the directory where it is located.
In the example shown in the picture, a file is searched, the text of which contains the word "Fegorsk". Search total commander will be on drive "C".
Note: A content search can be extremely helpful. I will give an example. I work as a programmer and do not need to find any file. Text that contains, for example, the word "function". To do this, I open the search window, select the folder in which I want to find something, put a daw "with text" and enter the text of interest. As a result, I get a list of files where my function is used. And I did not need to open each file individually. It is also very important that the search can be performed not only in text files.
Hello dear readers of the blog site. Quite often there is a need to find something inside the many available to you text files. It can be style files with the CSS extension, or it can be files of the engine you use with the extensions PHP, Html, etc.
Remember, when I wrote about, I said that the most difficult thing is to find the place where you need to change something in the set of files of the theme or site engine.
Of course, you can try to find the right piece of code or text using the built-in search capabilities. In fact, this is one of the most used programs on my computer. But there is a more convenient way and the popular one provides it to us (see).
How to find something inside multiple files in Total Commander?
This is not at all difficult to do. If everyone needed files, the contents of which you want to search, you already have on your computer, then just open the folder with them in any of the tabs Total Commander.
If these files are located on the server of your site, then just download them using, and then open this folder in Total.
So, we opened the folder in the left or right tab, and then click on the binocular button on the file manager toolbar, or type Alt + F7 on the keyboard. Or you can select the "Tools" item from the top menu of Total - "Search for files". In either case, a search box will open.
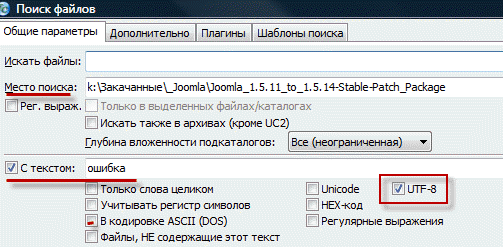
Just in case, check the path that will be displayed in the "Location" line shown in the screenshot. Do not enter anything in the “Search” field, but check the box “With text” and enter immediately after it that code fragment, word or set of characters that you want to find inside those files that are inside the folder specified in the "Location" field.
If the words you are looking for will be written in Russian, be sure to check the box located just below Utf 8otherwise nothing will be found.
If interested, you can read about other encodings of the Russian language in the article at the link provided.
All files in which a given word or character set will be found will be displayed as a list below. You can proceed to view them.
Good luck to you! See you soon on the blog pages site
Submit
To class
Linkanut
Stumble
Related collections:
Djvu - what is this format, how to open it, and what programs for reading files in deja vu to use on a computer or android
Google Drive - Than a Cloud Google drive differs from others cloud storage files
 Yandex Disk - storing files on Yandex, how to download them using the program on a computer, Android, iPad or website
Yandex Disk - storing files on Yandex, how to download them using the program on a computer, Android, iPad or website
 Sales funnel or how to do business now - what is CPM, CPC, CPL, CPS, CTR and direct marketing
Sales funnel or how to do business now - what is CPM, CPC, CPL, CPS, CTR and direct marketing
 Search the site and online store from Yandex
Search the site and online store from Yandex
 Search and basket in VirtueMart using modules and plugins for the online store on Joomla
Search and basket in VirtueMart using modules and plugins for the online store on Joomla
DocFetcher is an open source application that allows you to search the contents of files on your computer. - It's like Google, but only for local files. The application runs on Windows, Linux and OS X. Distributed under the Eclipse Public License.
How to use?
The screenshot below displays the main user interface programs. Requests are entered in the text box (1). Search results are displayed in the results pane (2). In the preview field (3), you can see the textual content of the file highlighted in the results pane. All matches are highlighted in yellow.
You can filter the results by specifying the minimum or maximum file size (4), file type (5) or its location (6). The buttons marked with a number (7) are used to call up the user manual, settings and minimize the program to tray.
For DocFetcher to work, it is necessary to index the folders in which you want to search. What is indexing and how it works is described in more detail below. In short, the index will allow DocFetcher to quickly (literally in a few moments) determine which files contain a certain set of words. Accordingly, the search speed increases. This screenshot shows the DocFetcher dialog for creating new indexes.
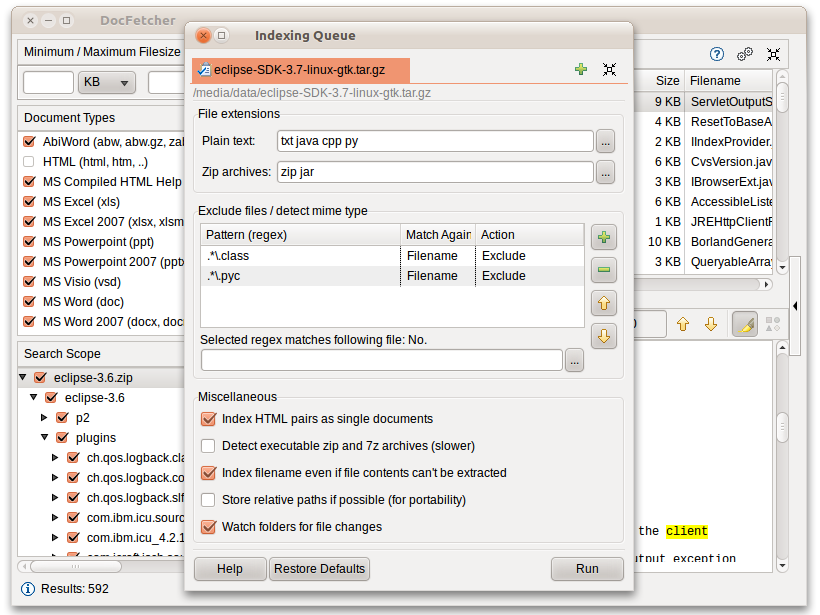
Clicking on the “Run” button at the bottom of this dialog box starts indexing. The indexing process may take some time, depending on the number and size of files to index. As a rule, about two hundred files are indexed per minute.
There is no need to index the same folder again each time. Update index of a folder after changing its contents is much faster. This process usually takes a few seconds.
Program features
- Portable version: Portable version of DocFetcher runs on Windows, Linux and OS X. The following describes why this is necessary.
- 64-bit support: Both 32-bit and 64-bit operating systems are supported.
- Unicode Support: DocFetcher supports Unicode for all major file formats, including Microsoft Office, OpenOffice.org, PDF, HTML, RTF, and TXT.
- Support for archived files: DocFetcher supports the following archive formats: zip, 7z, rar, and the entire tar. * Archive family. The list of file extensions for zip archives can be changed, which allows you to add support for other zip-based formats. In addition, DocFetcher can easily cope with an unlimited number of attached archives.
- Search in source files: File extensions in which DocFetcher recognizes plain text can be changed, this will allow you to use DocFetcher to search in any source code and other text formats. (This function in combination with the function of changing extensions for zip archives gives good results, for example, for example, you can search in the Java source code inside jar files)
- Outlook PST Files: DocFetcher allows you to search for Outlook emails, which are usually stored in PST files.
- Defining HTML Pairs DocFetcher by default defines pairs of HTML files (for example, a file called “foo.html” and a folder called “foo_files”) and treats them as one document. At first glance, this function may seem useless, but in fact it greatly improves performance when searching HTML files, since all the confusion from HTML folders does not fall into the search results.
- Regular Expression Index File Exclusions: You can use regular expressions to exclude certain files from the index. For example, to exclude microsoft files Excel, you can use this regex:. * \\. Xls
- Defining MIME Types: You can use regular expressions to enable the "definition of MIME types" for certain files, which will mean that DocFetcher will try to determine the file type not only by the name of this file, but also by its contents.
- Powerful query syntax: In addition to standard expressions such as “OR,” “AND,” and “NOT,” DocFetcher also supports wildcards, phrase searches, inaccurate searches (“find words similar to this”), neighborhood searches (“these two words should be at a distance of no more than 10 words from each other "), increase (" increase the rating of documents containing ... ")
Supported Document Formats
- Microsoft Office (doc, xls, ppt)
- Microsoft Office 2007 and later (docx, xlsx, pptx, docm, xlsm, pptm)
- Microsoft Outlook (pst)
- OpenOffice.org (odt, ods, odg, odp, ott, ots, otg, otp)
- Portable Document Format (pdf)
- EPUB (epub)
- HTML (html, xhtml, ...)
- Plain text (customizable)
- Rich Text Format (rtf)
- AbiWord (abw, abw.gz, zabw)
- Microsoft Compiled HTML Help (chm)
- MP3 Metadata (mp3)
- FLAC Metadata (flac)
- JPEG Exif Metadata (jpg, jpeg)
- Microsoft Visio (vsd)
- Scalable Vector Graphics (svg)
This is what sets DocFetcher apart from other search applications on the local computer:
Lack of garbage: The DocFetcher interface is completely clean. No ads and pop-ups with an offer to register. Nothing unnecessary is installed in your browser, registry, or anywhere else.
Privacy DocFetcher does not collect your personal information. None and never. Doubters can verify this by looking.
Free forever: Since DocFetcher has open source, you should not be afraid that the program will someday become outdated and stop developing. And speaking of technical support, have you heard that Google Desktop, one of the main commercial competitors of DocFetcher, ceased to be developed in 2011? Here.
Cross-platform: Unlike many competitors, DocFetcher works not only on Windows, but also on Linux, and OS X. Thus, if you suddenly decide to switch from Windows to Linux or OS X, DocFetcher will be waiting for you there.
*Portability: One of the main advantages of DocFetcher is its portability. In short, you can create a full-fledged searchable document storage on a USB stick. More details in the next section.
Indexing Only Required Documents: Among the commercial competitors of DocFetcher, there is a tendency to scan everything hard drive - Perhaps this is done for reasons that users are "dumb" and will not be able to use the program correctly. Or perhaps programs collect sensitive data in this way. Practice shows that most users not want to index the whole hDD. Not only because of a waste of time and disk space, but also because it clogs up search results unnecessary files. DocFetcher, on the other hand, only indexes the folders you point to. And you have many options for filtering.
Portable document stores
One of the outstanding features of DocFetcher is its availability in the form of portable versionwhich allows you to create portable document storage - fully accessible for index and search. You can take with you.
Java: Performance and Portability: Probably, not everyone likes the fact that DocFetcher is written on the Java platform, which has a reputation for being "slow." About ten years ago, Java performance really left much to be desired, but now everything is fine, you can read about it on Wikipedia. Be that as it may, Java allows the same DocFetcher package to be run on Windows, Linux and OS X - At the same time, many other programs require different packages for each platform. As a result, you can, for example, put your portable document store on a USB drive, and then access it from any of the above operating systems, making sure that Java is installed on the system.
How indexing works
This section gives a basic idea of \u200b\u200bwhat indexing is and how it works.
A simple approach to finding files: The simplest approach to file search is to simply search through each file in a folder. This is a great search solution only by file name, because the analysis of names is fast enough. But if you need to search by content files, then busting will not work here - extracting text is a more time-consuming task.
Index Based Search: That is why DocFetcher, when performing a content search, uses an approach called “indexing”. It is believed that most of the files (approximately 95%) that the user searches for are not changed (at least rarely). Instead of opening each file after each new search query, it would be much more efficient to do this only once. This creates something like a dictionary called index. It allows you to quickly find documents by the words contained in them.
Comparison with the phone book: Just think about how much more convenient it is to look for someone's phone number in the phone book (this is a kind of index), rather than ringing each a possible phone number to find out if the person on the other end of the wire is who you are looking for. - Calling someone and extracting text from a file is a time-consuming operation. In addition, people do not change their phone numbers. In the same way, many files on a computer remain unchanged for a long time.
Index Updates: Of course, the index displays the files in their state at the time of indexing. And it could have changed. That is, if the index is not relevant, the search results will be outdated. Obsolete in the same way phone book. But it's not a problem. As we already know, most files are rarely updated. In addition, DocFetcher can automatically update indexes: (1) At startup, it identifies modified files and, accordingly, updates their indexes. (2) When it is not running, a small background process will detect the changes in the files and make a list of those that require updating the index. DocFetcher will update these indexes the next time it starts. You can not worry about this background process: it really does not overload the processor and memory, since it does nothing but detect changes in folders, leaving more costly updating the DocFetcher index.