¿Qué son los sistemas de almacenamiento (SHD) y para qué sirven? ¿Cuál es la diferencia entre iSCSI y FiberChannel? ¿Por qué esta frase solo en los últimos años se hizo conocida por un amplio círculo de especialistas en TI y por qué los problemas de los sistemas de almacenamiento de datos son mentes cada vez más preocupantes?
Creo que muchas personas notaron las tendencias de desarrollo en el mundo de la informática que nos rodea: la transición de un modelo de desarrollo extenso a uno intensivo. El aumento de los procesadores de megahercios ya no da un resultado visible, y el desarrollo de unidades no se mantiene al día con la cantidad de información. Si en el caso de los procesadores todo está más o menos claro: es suficiente ensamblar sistemas multiprocesador y / o usar varios núcleos en un procesador, en caso de problemas de almacenamiento y procesamiento de información, no es tan fácil deshacerse de los problemas. La panacea actual para la epidemia de información es el almacenamiento. El nombre significa Red de área de almacenamiento o Sistema de almacenamiento. En cualquier caso, es especial. 
Principales problemas resueltos por el almacenamiento
Entonces, ¿qué tareas está diseñado para resolver el sistema de almacenamiento? Considere los problemas típicos asociados con el creciente volumen de información en cualquier organización. Supongamos que se trata de al menos unas pocas docenas de computadoras y varias oficinas separadas geográficamente.
1. Descentralización de la información. - si antes todos los datos podían almacenarse literalmente en un disco duro, ahora cualquier sistema funcional requiere un almacenamiento separado, por ejemplo, servidores correo electronico, DBMS, dominio, etc. La situación es complicada en el caso de oficinas distribuidas (sucursales).
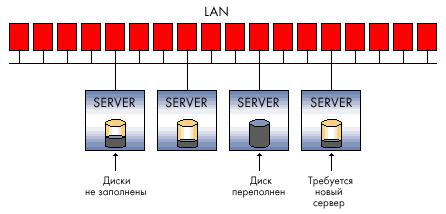
2. Crecimiento de información similar a una avalancha - A menudo, la cantidad de discos duros que puede instalar en un servidor en particular no puede cubrir la capacidad que necesita el sistema. Como resultado:
La incapacidad de proteger completamente los datos almacenados es, de hecho, porque es bastante difícil incluso hacer una copia de seguridad de los datos que no solo están en diferentes servidores, sino que también están dispersos geográficamente.
Velocidad de procesamiento de información insuficiente: los canales de comunicación entre sitios remotos aún dejan mucho que desear, pero incluso con un canal suficientemente "grueso" no siempre es posible utilizar completamente las redes existentes, por ejemplo, IP, para el trabajo.
La complejidad de la copia de seguridad: si los datos se leen y escriben en pequeños bloques, entonces puede ser poco realista hacer un archivo completo de la información desde un servidor remoto a través de los canales existentes; es necesario transferir la cantidad total de datos. El archivo local a menudo no es práctico por razones financieras: necesita sistemas de respaldo (unidades de cinta, por ejemplo), software especial (que puede costar mucho dinero) y personal capacitado y calificado.
3. Es difícil o imposible predecir el volumen requerido espacio en disco al implementar un sistema informático. Como resultado:
Existen problemas de expansión de las capacidades de disco: es bastante difícil obtener capacidades de terabytes en el servidor, especialmente si el sistema ya se está ejecutando en discos de pequeña capacidad existentes; como mínimo, se requiere un apagado del sistema e inversiones financieras ineficientes.
Utilización ineficiente de los recursos: a veces no puede adivinar en qué servidor crecerán los datos más rápido. Una cantidad críticamente pequeña de espacio en disco puede estar libre en el servidor de correo electrónico, mientras que otra unidad usará solo el 20% del volumen de un subsistema de disco costoso (por ejemplo, SCSI).
4. Baja confidencialidad de los datos distribuidos. - es imposible controlar y restringir el acceso de acuerdo con la política de seguridad de la empresa. Esto se aplica tanto al acceso a los datos en los canales existentes para esta (red de área local) como al acceso físico a los medios; por ejemplo, el robo de discos duros y su destrucción no están excluidos (para complicar el negocio de la organización). Las acciones no calificadas de los usuarios y el personal de mantenimiento pueden ser aún más perjudiciales. Cuando la empresa en cada oficina se ve obligada a resolver pequeños problemas de seguridad local, esto no da el resultado deseado.
5. La complejidad de gestionar flujos de información distribuida - cualquier acción que tenga como objetivo cambiar los datos en cada rama que contiene parte de los datos distribuidos crea ciertos problemas, que van desde la complejidad de sincronizar varias bases de datos, versiones de archivos de desarrolladores hasta la duplicación innecesaria de información.
6. Bajo efecto económico de la introducción de soluciones "clásicas" - con el crecimiento de la red de información, grandes cantidades de datos y una estructura de la empresa cada vez más distribuida, las inversiones financieras no son tan efectivas y a menudo no pueden resolver los problemas que surgen.
7. Los altos costos de los recursos utilizados para mantener la eficiencia de todo el sistema de información empresarial, desde la necesidad de mantener un gran personal de personal calificado hasta numerosas soluciones costosas de hardware que están diseñadas para resolver el problema de los volúmenes y las velocidades de acceso a la información, junto con un almacenamiento confiable y protección contra fallas.
A la luz de los problemas anteriores, que tarde o temprano superan total o parcialmente a cualquier empresa en desarrollo dinámico, intentaremos describir los sistemas de almacenamiento, como deberían ser. Considere esquemas de conexión típicos y tipos de sistemas de almacenamiento.
Megabytes / transacciones?
Si antes había discos duros dentro de la computadora (servidor), ahora se están llenando y no son muy confiables allí. La solución más simple (desarrollada hace mucho tiempo y utilizada en todas partes) es la tecnología RAID.
images \\ RAID \\ 01.jpg
Al organizar RAID en cualquier sistema de almacenamiento, además de proteger la información, obtenemos varias ventajas innegables, una de las cuales es la velocidad de acceso a la información.
Desde el punto de vista del usuario o software, la velocidad está determinada no solo por la capacidad del sistema (MB / s), sino también por el número de transacciones, es decir, el número de operaciones de E / S por unidad de tiempo (IOPS). Lógicamente, la mayor cantidad de discos y las técnicas de mejora del rendimiento que proporciona el controlador RAID (por ejemplo, el almacenamiento en caché) contribuyen a IOPS.
Si el rendimiento general es más importante para ver la transmisión de video u organizar un servidor de archivos, para el DBMS y cualquier aplicación OLTP (procesamiento de transacciones en línea), es el número de transacciones que el sistema es capaz de procesar lo que es crítico. Y con esta opción, los discos duros modernos no son tan optimistas como con volúmenes crecientes y, en parte, velocidades. Todos estos problemas están diseñados para resolver el sistema de almacenamiento en sí.
Niveles de protección
Debe comprender que la base de todos los sistemas de almacenamiento es la práctica de proteger la información basada en la tecnología RAID; sin esto, cualquier sistema de almacenamiento técnicamente avanzado será inútil, porque los discos duros en este sistema son el componente más poco confiable. Organizar discos en RAID es el "enlace inferior", el primer escalón de protección de la información y una mayor velocidad de procesamiento.
Sin embargo, además de los esquemas RAID, existe una protección de datos de nivel inferior implementada "sobre" las tecnologías y soluciones integradas en el disco duro por su fabricante. Por ejemplo, uno de los principales fabricantes de almacenamiento, EMC, tiene una metodología para el análisis adicional de integridad de datos a nivel del sector de unidades.
Habiendo tratado con RAID, pasemos a la estructura de los propios sistemas de almacenamiento. En primer lugar, los sistemas de almacenamiento se dividen según el tipo de interfaz de conexión de host (servidor) utilizada. Las interfaces de conexión externas son principalmente SCSI o FibreChannel, así como el estándar iSCSI bastante joven. Además, no descarte las pequeñas tiendas inteligentes que incluso se pueden conectar a través de USB o FireWire. No consideraremos interfaces más raras (a veces simplemente no exitosas de una forma u otra), como IBM SSA o interfaces desarrolladas para mainframes, por ejemplo, FICON / ESCON. Almacenamiento NAS independiente, conectado a la red Ethernet. La palabra "interfaz" básicamente significa un conector externo, pero no olvide que el conector no determina el protocolo de comunicación de los dos dispositivos. Nos detendremos en estas características un poco más abajo.
images \\ RAID \\ 02.gif
Significa interfaz de sistema de computadora pequeña (lea "tell"), una interfaz paralela semidúplex. En los sistemas de almacenamiento modernos, con mayor frecuencia se representa mediante un conector SCSI:
images \\ RAID \\ 03.gif
images \\ RAID \\ 04.gif
Y un grupo de protocolos SCSI, y más específicamente: Interfaz paralela SCSI-3. La diferencia entre SCSI y el IDE familiar es que hay más dispositivos por canal, longitudes de cable más largas, velocidades de transferencia de datos más rápidas, así como características "exclusivas" como señalización diferencial de alto voltaje, búsqueda de comandos y algunas otras. No abordaremos este problema.
Si hablamos de los principales fabricantes de componentes SCSI, como adaptadores SCSI, controladores RAID con interfaz SCSI, cualquier especialista recordará inmediatamente dos nombres: Adaptec y LSI Logic. Creo que esto es suficiente, no ha habido revoluciones en este mercado durante mucho tiempo y probablemente no se espera.
Interfaz de fibra-canal
Interfaz serie full duplex. Muy a menudo, en los equipos modernos está representado por conectores ópticos externos como LC o SC (LC - de tamaño más pequeño):
images \\ RAID \\ 05.jpg
images \\ RAID \\ 06.jpg
... y protocolos FibreChannel (FCP). Existen varios esquemas de conmutación de dispositivos FibreChannel:
Punto a punto - conexión directa punto a punto de dispositivos entre sí:
images \\ RAID \\ 07.gif
Punto de cruce cambiado - conectar dispositivos al conmutador FibreChannel (similar a la implementación de la red Ethernet en los conmutadores):
images \\ RAID \\ 08.gif
Bucle arbitrado - FC-AL, bucle con acceso de arbitraje: todos los dispositivos están conectados entre sí en un anillo, el circuito recuerda un poco al Token Ring. También se puede usar un conmutador, luego la topología física se implementará de acuerdo con el esquema "estrella", y el lógico, de acuerdo con el esquema de "bucle" (o "anillo"):
images \\ RAID \\ 09.gif
La conexión de acuerdo con el esquema FibreChannel Switched es el esquema más común, en términos de FibreChannel dicha conexión se llama Fabric - en ruso hay un papel de calco - "fábrica". Cabe señalar que los interruptores FibreChannel son dispositivos bastante avanzados, en términos de complejidad de llenado, están cerca de los interruptores IP de nivel 3. Si los interruptores están interconectados, operan en una sola fábrica, con un conjunto de configuraciones que son válidas para toda la fábrica a la vez. Cambiar algunas opciones en uno de los conmutadores puede conducir a un cambio de fábrica completa, sin mencionar la configuración de autorización de acceso, por ejemplo. Por otro lado, hay esquemas SAN que involucran varias fábricas dentro de una sola SAN. Por lo tanto, una fábrica solo puede llamarse un grupo de conmutadores interconectados: dos o más dispositivos no conectados introducidos en la SAN para aumentar la tolerancia a fallas de dos o más fábricas diferentes.
Los componentes que permiten combinar hosts y sistemas de almacenamiento en una sola red se conocen comúnmente como "conectividad". La conectividad es, por supuesto, cables de conexión dúplex (generalmente con una interfaz LC), conmutadores (conmutadores) y adaptadores FibreChannel (HBA, adaptadores de base de host), es decir, esas tarjetas de expansión que, cuando se instalan en los hosts, le permiten conectar el host a la red SAN. Los HBA generalmente se implementan como tarjetas PCI-X o PCI-Express.
images \\ RAID \\ 10.jpg
No confunda fibra y fibra: el medio de propagación de la señal puede ser diferente. FiberChannel puede funcionar en "cobre". Por ejemplo, todos los discos duros FibreChannel tienen contactos metálicos, y la conmutación habitual de dispositivos a través de "cobre" no es infrecuente, simplemente cambian gradualmente a canales ópticos como la tecnología más prometedora y el reemplazo funcional de "cobre".
Interfaz ISCSI
Usualmente representado por un conector externo RJ-45 para conectarse a una red Ethernet y el protocolo en sí iSCSI (Interfaz de sistema de computadora pequeña de Internet). Según la definición de SNIA: "iSCSI es un protocolo que se basa en TCP / IP y está diseñado para establecer la interoperabilidad y administrar sistemas de almacenamiento, servidores y clientes". Detengámonos en esta interfaz con más detalle, aunque solo sea porque cada usuario puede usar iSCSI incluso en una red "doméstica" normal.
Debe saber que iSCSI define al menos el protocolo de transporte para SCSI, que se ejecuta sobre TCP, y la tecnología para encapsular comandos SCSI en una red basada en IP. En pocas palabras, iSCSI es un protocolo que permite el acceso en bloque a los datos mediante comandos SCSI enviados a través de una red con una pila TCP / IP. iSCSI apareció como un reemplazo para FibreChannel y en los sistemas de almacenamiento modernos tiene varias ventajas sobre él: la capacidad de combinar dispositivos a largas distancias (utilizando redes IP existentes), la capacidad de proporcionar un nivel específico de QoS (Calidad de servicio, calidad de servicio), conectividad de menor costo. Sin embargo, el principal problema de usar iSCSI como reemplazo de FibreChannel son los largos retrasos que se producen en la red debido a las peculiaridades de la implementación de la pila TCP / IP, que niega una de las ventajas importantes de usar sistemas de almacenamiento: velocidad de acceso a la información y baja latencia. Este es un serio inconveniente.
Una pequeña observación sobre los hosts: pueden usar tanto tarjetas de red normales (luego el procesamiento de la pila iSCSI y la encapsulación de comandos se realizarán mediante software) como tarjetas especializadas que soportan tecnologías similares a TOE (TCP / IP Offload Engines). Esta tecnología proporciona procesamiento de hardware de la parte correspondiente de la pila de protocolos iSCSI. Método de software más barato, pero carga más el procesador central del servidor y, en teoría, puede generar más demoras que un procesador de hardware. Con la velocidad actual de las redes Ethernet a 1 Gbit / s, se puede suponer que iSCSI funcionará exactamente el doble de lento que el FibreChannel a una velocidad de 2 Gbit, pero en el uso real la diferencia será aún más notable.
Además de los ya discutidos, mencionamos brevemente un par de protocolos que son más raros y están diseñados para proporcionar servicios adicionales a las redes de área de almacenamiento (SAN) existentes:
FCIP (Fibre Channel sobre IP) - Un protocolo de túnel basado en TCP / IP y diseñado para conectar SAN dispersas geográficamente a través de un entorno IP estándar. Por ejemplo, puede combinar dos SAN en una a través de Internet. Esto se logra mediante el uso de una puerta de enlace FCIP que es transparente para todos los dispositivos en la SAN.
iFCP (Protocolo de canal de fibra de Internet) - Un protocolo que le permite combinar dispositivos con interfaces FC a través de redes IP. Una diferencia importante de FCIP es que es posible unir dispositivos FC a través de una red IP, lo que permite que un par diferente de conexiones tenga un nivel diferente de QoS, lo cual no es posible cuando se hace un túnel a través de FCIP.
Examinamos brevemente las interfaces físicas, protocolos y tipos de conmutación para sistemas de almacenamiento, sin detenernos en la lista de todos posibles opciones. Ahora intentemos imaginar qué parámetros caracterizan los sistemas de almacenamiento de datos.
Principales parámetros de hardware de almacenamiento
Algunos de ellos se enumeraron anteriormente: estos son el tipo de interfaces y tipos de conexión externa accionamientos internos (discos duros) El siguiente parámetro, que tiene sentido considerar después de los dos anteriores al elegir un sistema de almacenamiento en disco, es su confiabilidad. La fiabilidad puede evaluarse no por el tiempo de funcionamiento banal entre la falla de cualquier componente individual (el hecho de que este tiempo es aproximadamente igual para todos los fabricantes), sino por la arquitectura interna. Un sistema de almacenamiento "normal" a menudo "externamente" es un estante de disco (para montar en un gabinete de 19 pulgadas) con discos duros, interfaces externas para conectar hosts, varias fuentes de alimentación. En el interior, generalmente se instala todo lo que proporciona el sistema de almacenamiento: unidades de procesador, controladores de disco, puertos de entrada / salida, memoria caché, etc. Por lo general, el bastidor se controla desde línea de comando o mediante la interfaz web, la configuración inicial a menudo requiere una conexión en serie. El usuario puede "dividir" los discos del sistema en grupos y combinarlos en RAID (de varios niveles), el espacio en disco resultante se divide en una o más unidades lógicas (LUN), a las que los hosts (servidores) tienen acceso y "los ven" como discos duros locales. El administrador del sistema configura la cantidad de grupos RAID, LUN, la lógica de la memoria caché, la disponibilidad de LUN para servidores específicos y todo lo demás. Por lo general, los sistemas de almacenamiento están diseñados para conectarse a ellos, no uno, sino varios (hasta cientos, en teoría) servidores; por lo tanto, dicho sistema debe tener un alto rendimiento, un sistema de control y monitoreo flexible y herramientas de protección de datos bien pensadas. La protección de datos se proporciona de muchas maneras, la más fácil de las que ya conoce: la combinación de unidades en RAID. Sin embargo, los datos también deben ser accesibles constantemente; después de todo, detener un sistema de almacenamiento de datos central para la empresa puede causar pérdidas significativas. Mientras más sistemas almacenen datos en el sistema de almacenamiento, se debe proporcionar un acceso más confiable al sistema, porque en caso de accidente, el sistema de almacenamiento deja de funcionar inmediatamente en todos los servidores que almacenan datos allí. La alta disponibilidad del bastidor está garantizada por la duplicación interna completa de todos los componentes del sistema: rutas de acceso al bastidor (puertos FibreChannel), módulos de procesador, memoria caché, fuentes de alimentación, etc. Trataremos de explicar el principio de 100% de redundancia (duplicación) con la siguiente figura:
images \\ RAID \\ 11.gif
1. El controlador (módulo procesador) del sistema de almacenamiento, que incluye:
* procesador central (o procesadores): generalmente se ejecuta un software especial en el sistema, que desempeña el papel de " sistema operativo»;
* interfaces para cambiar con discos duros: en nuestro caso, se trata de placas que proporcionan conexión de discos FibreChannel de acuerdo con el esquema de bucle de acceso de arbitraje (FC-AL);
* memoria caché;
* Controladores de puerto externo FibreChannel
2. La interfaz externa de FC; Como vemos, hay 2 de ellos para cada módulo de procesador;
3. Discos duros - la capacidad se amplía con estantes de disco adicionales;
4. La memoria caché en dicho esquema generalmente se refleja para no perder los datos almacenados allí cuando falla algún módulo.
Con respecto al hardware, los bastidores de disco pueden tener diferentes interfaces para conectar hosts, diferentes interfaces de discos duros, diferentes esquemas de conexión para estantes adicionales, que sirven para aumentar el número de discos en el sistema, así como otros "parámetros de hierro" puramente.
Software SHD
Naturalmente, la potencia del hardware de los sistemas de almacenamiento debe gestionarse de alguna manera, y los sistemas de almacenamiento en sí mismos simplemente están obligados a proporcionar un nivel de servicio y funcionalidad que no está disponible en los esquemas convencionales de servidor-cliente. Si observa la figura "Diagrama estructural de un sistema de almacenamiento de datos", queda claro que cuando el servidor está conectado directamente al bastidor de dos maneras, deben estar conectados a los puertos FC de varios módulos de procesador para que el servidor continúe funcionando si todo el módulo del procesador falla de inmediato. Naturalmente, para usar múltiples rutas, el hardware y el software deben proporcionar soporte para esta funcionalidad en todos los niveles involucrados en la transferencia de datos. Por supuesto, la copia de seguridad completa sin herramientas de monitoreo y advertencia no tiene sentido; por lo tanto, todos los sistemas de almacenamiento serios tienen tales capacidades. Por ejemplo, la notificación de cualquier evento crítico puede ocurrir por varios medios: una alerta por correo electrónico, una llamada de módem automática al centro de soporte técnico, un mensaje a un buscapersonas (ahora más relevante que SMS), mecanismos SNMP y más.
Bueno, y como ya mencionamos, hay controles poderosos para toda esta magnificencia. Por lo general, esta es una interfaz basada en web, una consola, la capacidad de escribir scripts e integrar el control en paquetes de software externos. Solo mencionaremos brevemente los mecanismos que garantizan un alto rendimiento de los sistemas de almacenamiento: arquitectura sin bloqueo con varios buses internos y una gran cantidad de discos duros, potentes procesadores centrales, un sistema de control especializado (SO), una gran cantidad de memoria caché y muchas interfaces de E / S externas.
Los servicios proporcionados por los sistemas de almacenamiento generalmente están determinados por el software que se ejecuta en el bastidor del disco. Casi siempre, estos son paquetes de software complejos comprados bajo licencias separadas que no están incluidos en el costo del almacenamiento en sí. Mencionaremos de inmediato el software familiar para múltiples rutas: simplemente funciona en hosts, no en el rack en sí.
La siguiente solución más popular es el software para crear copias instantáneas y completas de datos. Diferentes fabricantes tienen diferentes nombres para sus productos de software y mecanismos para crear estas copias. Para resumir, podemos manipular las palabras instantánea y clonar. Se crea un clon utilizando el bastidor de disco dentro del bastidor en sí; esta es una copia interna completa de los datos. El alcance de la aplicación es bastante amplio: desde la copia de seguridad (copia de seguridad) hasta la creación de una "versión de prueba" de los datos de origen, por ejemplo, para actualizaciones arriesgadas en las que no hay confianza y que no es seguro usar en los datos actuales. Cualquiera que haya seguido de cerca todos los encantos de almacenamiento que analizamos aquí preguntará: ¿por qué necesita una copia de seguridad de datos dentro del bastidor si tiene una confiabilidad tan alta? La respuesta a esta pregunta en la superficie es que nadie es inmune a los errores humanos. Los datos se almacenan de manera confiable, pero si el operador mismo hizo algo mal, por ejemplo, eliminó la tabla deseada en la base de datos, ningún truco de hardware podría salvarlo. La clonación de datos generalmente se realiza a nivel de LUN. El mecanismo de instantánea proporciona una funcionalidad más interesante. Hasta cierto punto, obtenemos todos los encantos de una copia interna completa de los datos (clon), sin ocupar el 100% de la cantidad de datos copiados dentro del bastidor, porque ese volumen no siempre está disponible para nosotros. De hecho, una instantánea es una instantánea instantánea de datos que no requiere tiempo ni recursos de almacenamiento del procesador.
Por supuesto, uno no puede dejar de mencionar el software de replicación de datos, que a menudo se llama duplicación. Este es un mecanismo para la replicación síncrona o asíncrona (duplicación) de información de un sistema de almacenamiento a uno o más sistemas de almacenamiento remoto. La replicación es posible a través de varios canales; por ejemplo, los racks con interfaces FibreChannel se pueden replicar a otro sistema de almacenamiento de forma asincrónica, a través de Internet y a largas distancias. Esta solución proporciona almacenamiento confiable de información y protección contra desastres.
Además de todo lo anterior, hay una gran cantidad de otros mecanismos de software para la manipulación de datos ...
DAS y NAS y SAN
Después de familiarizarse con los propios sistemas de almacenamiento de datos, los principios de su construcción, las capacidades que proporcionan y los protocolos de funcionamiento, es hora de intentar combinar los conocimientos adquiridos en un esquema de trabajo. Tratemos de considerar los tipos de sistemas de almacenamiento y la topología de su conexión a una única infraestructura de trabajo.
Dispositivos DAS (almacenamiento adjunto directo) - sistemas de almacenamiento que se conectan directamente al servidor. Esto incluye los sistemas SCSI más simples conectados al controlador SCSI / RAID del servidor y los dispositivos FibreChannel conectados directamente al servidor, aunque están diseñados para SAN. En este caso, la topología DAS es una SAN (red de área de almacenamiento) degenerada:
images \\ RAID \\ 12.gif
En este esquema, uno de los servidores tiene acceso a los datos almacenados en el sistema de almacenamiento. Los clientes acceden a los datos accediendo a este servidor a través de la red. Es decir, el servidor tiene acceso bloqueado a los datos en el sistema de almacenamiento, y los clientes ya usan el acceso a archivos; este concepto es muy importante para comprender. Las desventajas de dicha topología son obvias:
* Baja confiabilidad: en caso de problemas de red o fallas del servidor, los datos se vuelven inaccesibles para todos a la vez.
* Alta latencia debido al procesamiento de todas las solicitudes por un servidor y el transporte utilizado (con mayor frecuencia - IP).
* Alta carga de red, que a menudo define límites de escalabilidad al agregar clientes.
* Mala capacidad de administración: toda la capacidad está disponible para un servidor, lo que reduce la flexibilidad de la distribución de datos.
* Baja utilización de recursos: es difícil predecir los volúmenes de datos requeridos, algunos dispositivos DAS en una organización pueden tener un exceso de capacidad (discos), otros pueden no tener suficiente; la redistribución a menudo es imposible o lleva mucho tiempo.
Dispositivos NAS (almacenamiento conectado a la red) - dispositivos de almacenamiento conectados directamente a la red. A diferencia de otros sistemas, NAS proporciona acceso a archivos a datos y nada más. Los dispositivos NAS son una combinación del sistema de almacenamiento y el servidor al que está conectado. En su forma más simple, un servidor de red regular que proporciona recursos de archivos es un dispositivo NAS:
images \\ RAID \\ 13.gif
Todas las desventajas de tal esquema son similares a la topología DAS, con algunas excepciones. De los inconvenientes que se han agregado, observamos el aumento, y a menudo significativamente, el costo; sin embargo, el costo es proporcional a la funcionalidad, y aquí a menudo "hay algo por lo que pagar". Los dispositivos NAS pueden ser las "cajas" más simples con un puerto ethernet y dos discos duros en RAID1, lo que permite el acceso a los archivos utilizando solo un protocolo CIFS (Common Internet File System) a grandes sistemas en los que se pueden instalar cientos de discos duros y acceso a archivos proporcionado por una docena de servidores especializados dentro del sistema NAS. El número de puertos Ethernet externos puede alcanzar muchas decenas, y la capacidad de los datos almacenados puede ser de varios cientos de terabytes (por ejemplo, EMC Celerra CNS). La confiabilidad y el rendimiento de dichos modelos pueden omitir muchos dispositivos de rango medio SAN. Curiosamente, los dispositivos NAS pueden ser parte de una red SAN y no tienen sus propias unidades, sino que solo proporcionan acceso a los datos que residen en los dispositivos de almacenamiento en bloque. En este caso, el NAS asume la función de un poderoso servidor especializado, y la SAN asume el dispositivo de almacenamiento, es decir, obtenemos la topología DAS, compuesta de componentes NAS y SAN.
Los dispositivos NAS son muy buenos en un entorno heterogéneo donde necesita un acceso rápido a los archivos de datos para muchos clientes al mismo tiempo. También proporciona excelente confiabilidad de almacenamiento y flexibilidad de administración del sistema junto con facilidad de mantenimiento. No nos detendremos en la confiabilidad: este aspecto del almacenamiento se discutió anteriormente. En cuanto a un entorno heterogéneo, el acceso a los archivos dentro de un único sistema NAS se puede obtener a través de TCP / IP, CIFS, NFS, FTP, TFTP y otros, incluida la capacidad de trabajar como un objetivo NAS iSCSI, que garantiza el funcionamiento con diferentes sistemas operativos, instalado en hosts. En cuanto a la facilidad de mantenimiento y la flexibilidad de administración, estas capacidades son proporcionadas por un sistema operativo especializado, que es difícil de deshabilitar y no necesita mantenimiento, así como la simplicidad de la diferenciación de los derechos de acceso a los archivos. Por ejemplo, es posible trabajar en un entorno de Active Directory de Windows con soporte para la funcionalidad requerida: puede ser LDAP, autenticación Kerberos, DNS dinámico, ACL, cuotas (cuotas), objetos de política de grupo e historial de SID. Dado que se proporciona acceso a los archivos, y sus nombres pueden contener caracteres de varios idiomas, muchos NAS ofrecen soporte para codificaciones Unicode UTF-8. La elección del NAS debe abordarse incluso con más cuidado que los dispositivos DAS, ya que dicho equipo puede no admitir los servicios que necesita, por ejemplo, Sistemas de cifrado de archivos (EFS) de Microsoft e IPSec. Por cierto, puede ver que los NAS son mucho menos comunes que los dispositivos SAN, pero el porcentaje de tales sistemas sigue creciendo constantemente, aunque lentamente, principalmente debido al desplazamiento del DAS.
Dispositivos para conectarse SAN (red de área de almacenamiento) - dispositivos para conectarse a una red de almacenamiento de datos. Una red de área de almacenamiento (SAN) no debe confundirse con una red de área local; estas son redes diferentes. La mayoría de las veces, la SAN se basa en la pila de protocolos FibreChannel y, en el caso más simple, consiste en sistemas de almacenamiento, conmutadores y servidores conectados por canales ópticos de comunicación. En la figura vemos una infraestructura altamente confiable en la que los servidores se incluyen simultáneamente en red local (izquierda) y a la red de almacenamiento (derecha):
images \\ RAID \\ 14.gif
Después de una discusión bastante detallada de los dispositivos y sus principios de operación, será bastante fácil para nosotros comprender la topología SAN. En la figura vemos un único sistema de almacenamiento para toda la infraestructura, al que están conectados dos servidores. Los servidores tienen rutas de acceso redundantes: cada uno tiene dos HBA (o un puerto dual, lo que reduce la tolerancia a fallas). El dispositivo de almacenamiento tiene 4 puertos por los cuales está conectado a 2 conmutadores. Suponiendo que hay dos módulos de procesador redundantes en el interior, es fácil adivinar que el mejor esquema de conexión es cuando cada conmutador está conectado al primer y al segundo módulo de procesador. Dicho esquema proporciona acceso a cualquier dato ubicado en el sistema de almacenamiento en caso de falla de cualquier módulo de procesador, conmutador o ruta de acceso. Ya hemos estudiado la confiabilidad de los sistemas de almacenamiento, dos conmutadores y dos fábricas aumentan aún más la disponibilidad de la topología, por lo que si una de las unidades de conmutación falla repentinamente debido a una falla o un error del administrador, la segunda funcionará normalmente, porque estos dos dispositivos no están interconectados.
La conexión del servidor que se muestra se denomina conexión de alta disponibilidad, aunque se puede instalar una cantidad aún mayor de HBA en el servidor si es necesario. Físicamente, cada servidor tiene solo dos conexiones en la SAN, pero lógicamente, se puede acceder al sistema de almacenamiento a través de cuatro rutas: cada HBA proporciona acceso a dos puntos de conexión en el sistema de almacenamiento, por separado para cada módulo de procesador (esta característica proporciona una doble conexión del conmutador al sistema de almacenamiento). En este diagrama, el dispositivo más poco confiable es el servidor. Dos conmutadores proporcionan una confiabilidad del orden del 99,99%, pero el servidor puede fallar por varias razones. Si se requiere una operación altamente confiable de todo el sistema, los servidores se combinan en un clúster, el diagrama anterior no requiere ninguna adición de hardware para organizar dicho trabajo, y se considera la organización de referencia de la SAN. El caso más simple son los servidores conectados de una sola manera a través de un conmutador al sistema de almacenamiento. Sin embargo, el sistema de almacenamiento con dos módulos de procesador debe estar conectado al conmutador con al menos un canal por módulo; los puertos restantes se pueden usar para la conexión directa de servidores al sistema de almacenamiento, lo que a veces es necesario. Y no olvide que la SAN se puede construir no solo sobre la base de FibreChannel, sino también sobre la base del protocolo iSCSI; al mismo tiempo, puede usar solo dispositivos Ethernet estándar para la conmutación, lo que reduce el costo del sistema, pero tiene una cantidad de desventajas adicionales (especificadas en la sección que trata sobre iSCSI ) También es interesante la capacidad de cargar servidores desde el sistema de almacenamiento; ni siquiera es necesario tener discos duros internos en el servidor. Por lo tanto, la tarea de almacenar cualquier dato finalmente se elimina de los servidores. En teoría, un servidor especializado se puede convertir en una trituradora de números ordinaria sin unidades, cuyos bloques definidores son procesadores centrales, memoria e interfaces para interactuar con el mundo exterior, por ejemplo, puertos Ethernet y FibreChannel. Algún tipo de dispositivos similares son los servidores blade modernos.
Me gustaría señalar que los dispositivos que se pueden conectar a la SAN no se limitan solo a los sistemas de almacenamiento en disco: pueden ser bibliotecas de discos, bibliotecas de cintas (unidades de cinta), dispositivos para almacenar datos en discos ópticos (CD / DVD, etc.) y muchos otros.
De los inconvenientes de SAN, observamos solo el alto costo de sus componentes, pero las ventajas son innegables:
* Alta confiabilidad de acceso a datos ubicados en sistemas de almacenamiento externo. Independencia de la topología SAN de los sistemas y servidores de almacenamiento usados.
* Almacenamiento centralizado de datos (confiabilidad, seguridad).
* Gestión centralizada conveniente de conmutación y datos.
* Transfiera tráfico de E / S intensivo a una red separada, descargando LAN.
* Alta velocidad y baja latencia.
* Escalabilidad y flexibilidad estructura lógica San
* Geográficamente, los tamaños de SAN, a diferencia del DAS clásico, son prácticamente ilimitados.
* Capacidad para distribuir rápidamente recursos entre servidores.
* Capacidad para construir soluciones de clúster tolerantes a fallas sin costo adicional basado en la SAN existente.
* Esquema de copia de seguridad simple: todos los datos están en un solo lugar.
* La presencia de características y servicios adicionales (instantáneas, replicación remota).
* SAN de alta seguridad.
En conclusión
Creo que hemos cubierto adecuadamente la gama principal de problemas relacionados con los sistemas de almacenamiento modernos. Esperemos que tales dispositivos se desarrollen funcionalmente aún más rápidamente, y la cantidad de mecanismos de administración de datos solo crecerá.
En conclusión, podemos decir que las soluciones NAS y SAN actualmente están experimentando un verdadero auge. El número de fabricantes y la variedad de soluciones está aumentando, y la educación técnica de los consumidores está creciendo. Podemos suponer con seguridad que en el futuro cercano en casi todos los entornos informáticos, aparecerá uno u otro sistema de almacenamiento.
Cualquier dato aparece ante nosotros en forma de información. El significado del trabajo de cualquier dispositivo informático es el procesamiento de información. En recientemente sus volúmenes de crecimiento a veces asustan, por lo tanto, los sistemas de almacenamiento y el software especializado serán sin duda los productos más demandados del mercado de TI en los próximos años.
¿Cómo clasificar la arquitectura de los sistemas de almacenamiento? Me parece que la relevancia de este tema solo crecerá en el futuro. ¿Cómo entender toda esta variedad de ofertas disponibles en el mercado? Quiero advertirte de inmediato que esta publicación no está destinada a los perezosos o aquellos que no quieren leer mucho.
Es posible clasificar los sistemas de almacenamiento con bastante éxito, de forma similar a cómo los biólogos construyen lazos familiares entre especies de organismos vivos. Si lo desea, puede llamarlo el "árbol de la vida" del mundo de las tecnologías de almacenamiento de información.
La construcción de tales árboles ayuda a comprender mejor el mundo circundante. En particular, puede crear un diagrama del origen y desarrollo de cualquier tipo de sistema de almacenamiento, y comprender rápidamente lo que está en la base de cualquier nueva tecnología que aparezca en el mercado. Esto le permite determinar inmediatamente las fortalezas y debilidades de una solución.
Los repositorios que le permiten trabajar con información de cualquier tipo, se pueden dividir arquitectónicamente en 4 grupos principales. Lo principal es no obsesionarse con algunas cosas que son confusas. Muchos tienden a clasificar las plataformas en función de criterios "físicos" como la interconexión ("¡Todos tienen un bus interno entre nodos!"), O un protocolo ("¡Esto es un bloque, o NAS, o sistema multiprotocolo!"), o dividido en hardware y software ("¡Esto es solo software en el servidor!").
Es enfoque completamente equivocado a la clasificación El único criterio verdadero es la arquitectura de software utilizada en una solución particular, ya que todas las características básicas del sistema dependen de ello. Los componentes restantes del sistema de almacenamiento dependen de la arquitectura de software elegida por los desarrolladores. Y desde este punto de vista, los sistemas de "hardware" y "software" solo pueden ser variaciones de una u otra arquitectura.
Pero no me malinterpreten, no quiero decir que la diferencia entre ellos es pequeña. Simplemente no es fundamental.
Y quiero aclarar algo más antes de ponerme manos a la obra. Es común que nuestra naturaleza haga las preguntas "¿Y cuál de estas es la mejor / correcta?". Solo hay una respuesta a esto: "Existen mejores soluciones para situaciones específicas o tipos de carga de trabajo, pero no existe una solución ideal universal". Exactamente las características de la carga dictan la elección de la arquitectura.Y nada más.
Por cierto, recientemente participé en una conversación divertida sobre el tema de los centros de datos que funcionan exclusivamente en unidades flash. Estoy impresionado con la pasión en cualquier manifestación, y está claro que el flash está más allá de la competencia en situaciones donde el rendimiento y la latencia juegan un papel decisivo (entre muchos otros factores). Pero debo admitir que mis interlocutores estaban equivocados. Tenemos un cliente, muchas personas usan sus servicios todos los días sin siquiera darse cuenta. ¿Puede cambiar a flash por completo? No

Este es un gran cliente. Y aquí hay otro, ENORME, 10 veces más. Y de nuevo, no puedo aceptar que este cliente pueda cambiar exclusivamente a flash:
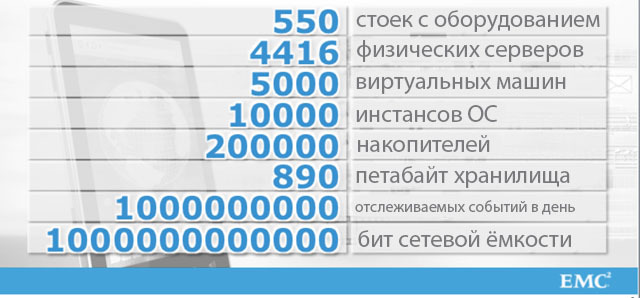
Por lo general, como contraargumento, dicen que al final el flash alcanzará un nivel de desarrollo tal que eclipsará accionamientos magnéticos. Con la advertencia de que el flash se utilizará junto con la deduplicación. Pero no en todos los casos es recomendable aplicar la deduplicación, así como la compresión.
Bueno, por un lado, la memoria flash se volverá más barata, hasta cierto límite. Me pareció que esto sucedería un poco más rápido, pero los SSD con una capacidad de 1 TB por $ 550 ya están disponibles, este es un gran progreso. Por supuesto, los desarrolladores de discos duros tradicionales tampoco están inactivos. En la región 2017-2018, la competencia debería intensificarse, ya que se introducirán nuevas tecnologías (muy probablemente, cambio de fase y nanotubos de carbono). Pero no es en absoluto una confrontación entre unidades flash y discos duros, o incluso soluciones de software y hardware, lo principal es arquitectura.
Es tan importante que es casi imposible cambiar la arquitectura de almacenamiento sin rehacer casi todo. Eso es, de hecho, sin crear un nuevo sistema. Por lo tanto, los almacenamientos generalmente se crean, desarrollan y mueren dentro del marco de una única arquitectura inicialmente seleccionada.
Cuatro tipos de almacenamiento
Tipo 1. Arquitectura agrupada. No están diseñados para compartiendo nodos de memoria, de hecho, todos los datos están en un nodo. Una de las características de la arquitectura es que a veces los dispositivos "se cruzan" (traspasan), incluso si son "accesibles desde varios nodos". Otra característica es que puede seleccionar una máquina, indicarle algunas unidades y decir "esta máquina tiene acceso a los datos en estos medios". El azul en la figura indica el sistema de CPU / memoria / entrada-salida, y en verde, el medio en el que se almacenan los datos (unidades flash o magnéticas).
Este tipo de arquitectura se caracteriza por un acceso directo y muy rápido a los datos. Habrá ligeros retrasos entre las máquinas porque la duplicación de E / S y el almacenamiento en caché se utilizan para proporcionar una alta disponibilidad. Pero en general, se proporciona un acceso relativamente directo a lo largo de la rama de código. Los almacenamientos de software son bastante simples y tienen una baja latencia, por lo que a menudo tienen una funcionalidad rica, los servicios de datos se agregan fácilmente. No es sorprendente que la mayoría de las startups comiencen con dichos repositorios.
Tenga en cuenta que una de las variedades de este tipo de arquitectura es el equipo PCIe para servidores que no son HA (tarjetas de expansión Fusion-IO, XtremeCache). Si le agregamos software para almacenamiento distribuido, coherencia y un modelo de alta disponibilidad, entonces dicho almacenamiento de software corresponderá a uno de los cuatro tipos de arquitecturas descritas en esta publicación.
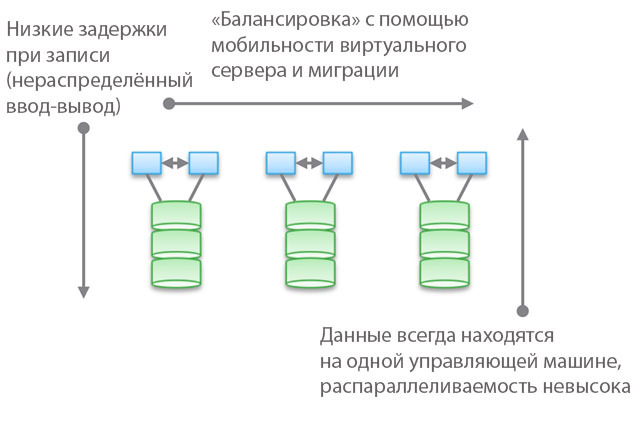
El uso de "modelos federados" ayuda a mejorar la escalabilidad horizontal de este tipo de arquitectura desde el punto de vista de la administración. Estos modelos pueden usar diferentes enfoques para aumentar la movilidad de datos para reequilibrar entre las máquinas host y el almacenamiento. Por ejemplo, dentro de VNX, esto significa "movilidad VDM". Pero creo que llamarlo "arquitectura escalable horizontalmente" será una exageración. Y, en mi experiencia, la mayoría de los clientes comparten esta opinión. La razón de esto es la ubicación de los datos en una máquina de control, a veces, "en un gabinete de hardware" (detrás de un gabinete). Se pueden mover, pero siempre estarán en un solo lugar. Por un lado, esto reduce el número de ciclos y el retraso en la grabación. Por otro lado, todos sus datos son servidos por una sola máquina de control (es posible el acceso indirecto desde otra máquina). A diferencia del segundo y tercer tipo de arquitecturas, que discutiremos a continuación, el equilibrio y el ajuste juegan un papel importante aquí.
Hablando objetivamente, este nivel federal abstracto implica un ligero aumento en la latencia porque utiliza la redirección de software. Esto es similar a complicar el código y aumentar la latencia en los tipos de arquitecturas 2 y 3, y elimina en parte las ventajas del primer tipo. Como ejemplo concreto, UCS Invicta, una especie de "enrutadores de almacenamiento de silicio". En el caso de NetApp FAS 8.x, que opera en modo de clúster, el código es bastante complicado por la introducción de un modelo federado.
Productos que utilizan arquitecturas de clúster: VNX o NetApp FAS, Pure, Tintri, Nimble, Nexenta y (creo) UCS Invicta / UCS. Algunas son soluciones de "hardware", otras son "puramente software" y otras son "software en forma de complejos de hardware". Todos ellos son MUY diferentes en términos de procesamiento de datos (en Pure y UCS Invicta / Whiptail, solo se utilizan unidades flash). Pero arquitectónicamente, todos los productos enumerados están relacionados. Por ejemplo, configura servicios de procesamiento de datos exclusivamente para copias de seguridad, la pila de software se convierte en Data Domain, su NAS funciona como la mejor herramienta de copia de seguridad del mundo, y esta también es la arquitectura de "primer tipo".
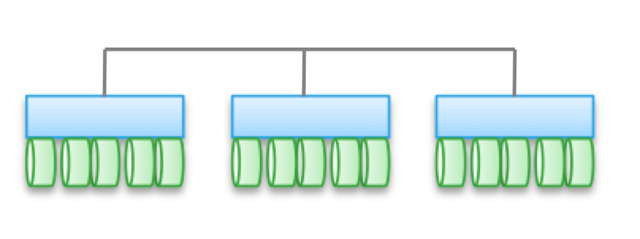
Tipo 2. Arquitecturas débilmente interconectadas, escaladas horizontalmente. Los nodos no comparten memoria, pero los datos en sí son para varios nodos. Esta arquitectura implica el uso de mas relaciones internacionales para el registro de datos, lo que aumenta el número de ciclos. Aunque las operaciones de escritura están distribuidas, siempre son coherentes.
Tenga en cuenta que estas arquitecturas no proporcionan alta disponibilidad para el nodo debido a las operaciones de copia y distribución de datos. Por la misma razón, siempre hay más operaciones de E / S en comparación con arquitecturas de clúster simples. Por lo tanto, el rendimiento es ligeramente inferior, a pesar del pequeño nivel de retraso de grabación (NVRAM, SSD, etc.).
En algunas variedades de arquitecturas, los nodos a menudo se ensamblan en subgrupos, mientras que el resto se usa para administrar subgrupos (nodos de metadatos). Pero aquí se manifiestan los efectos descritos anteriormente para los "modelos federados".

Tales arquitecturas son bastante fáciles de escalar. Dado que los datos se almacenan en varios lugares y pueden ser procesados \u200b\u200bpor múltiples nodos, estas arquitecturas pueden ser excelentes para tareas cuando se requiere lectura distribuida. Además, combinan bien con el software de servidor / almacenamiento. Pero es mejor usar arquitecturas similares bajo cargas transaccionales: debido a su naturaleza distribuida, no puede usar un servidor HA, y la conjugación débil le permite evitar Ethernet.
Este tipo de arquitectura se utiliza en productos como EMC ScaleIO e Isilon, VSAN, Nutanix y Simplivity. Como en el caso del Tipo 1, todas estas soluciones son completamente diferentes entre sí.
La conectividad débil significa que a menudo estas arquitecturas pueden aumentar significativamente el número de nodos. Pero, permítame recordarle que NO comparten memoria, el código de cada nodo funciona independientemente de los demás. Pero el diablo, como dicen, en detalle:
- Cuantas más operaciones de grabación se distribuyan, mayor será la latencia y menor la eficiencia de la PIO. Por ejemplo, en Isilon, el nivel de distribución es muy alto para los archivos, y aunque con cada actualización se reducen los retrasos, aún así nunca demostrará el rendimiento más alto. Pero Isilon es extremadamente fuerte en términos de paralelización.
- Si reduce el grado de distribución (aunque con una gran cantidad de nodos), los retrasos pueden disminuir, pero al mismo tiempo reducirá su capacidad de paralelizar la lectura de datos. Por ejemplo, VSAN utiliza el modelo de "máquina virtual como un objeto", que le permite ejecutar múltiples copias. Parece que una máquina virtual debería ser accesible a un host específico. Pero, de hecho, en VSAN "se desplaza" hacia el nodo que almacena sus datos. Si usa esta solución, puede ver por sí mismo cómo el aumento del número de copias de un objeto afecta la latencia y las operaciones de E / S en todo el sistema. Sugerencia: más copias \u003d mayor carga en el sistema en su conjunto, y la dependencia es no lineal, como es de esperar. Pero para VSAN, esto no es un problema debido a las ventajas de la máquina virtual como modelo de objetos.
- Es posible lograr una baja latencia en condiciones de gran escalamiento y paralelización durante la lectura, pero solo si los datos y la escritura están separados con precisión. un gran número copias Este enfoque se usa en ScaleIO. Cada volumen se divide en una gran cantidad de fragmentos (1 MB por defecto), que se distribuyen en todos los nodos involucrados. El resultado es una velocidad de lectura y redistribución extremadamente alta junto con una poderosa paralelización. El retraso de escritura puede ser inferior a 1 ms cuando se utiliza la infraestructura de red adecuada y SSD / PCIe Flash en los nodos del clúster. Sin embargo, cada operación de escritura se realiza en dos nodos. Por supuesto, a diferencia de VSAN, aquí la máquina virtual no se considera como un objeto. Pero si se considera, la escalabilidad sería peor.
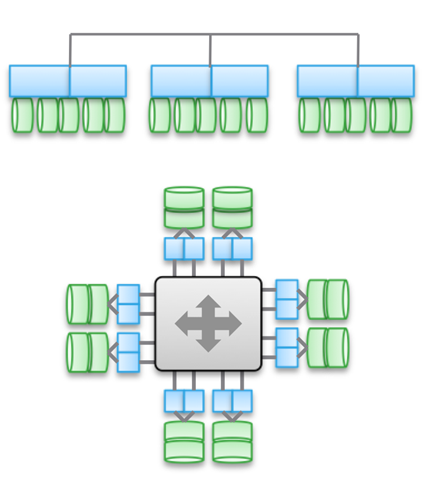
Tipo 3. Arquitecturas fuertemente interconectadas, escaladas horizontalmente. Utiliza el uso compartido de memoria (para el almacenamiento en caché y algunos tipos de metadatos). Los datos se distribuyen entre varios nodos. Este tipo de arquitectura implica el uso de una gran cantidad de conexiones de entrenudos para todo tipo de operaciones.
Compartir memoria es la piedra angular de estas arquitecturas. Históricamente, a través de todas las máquinas de control se pueden llevar a cabo operaciones de E / S simétricas (ver ilustración). Esto le permite reequilibrar la carga en caso de mal funcionamiento. Esta idea fue la base de productos como Symmetrix, IBM DS, HDS USP y VSP. Proporcionan acceso compartido a la memoria caché, por lo que el procedimiento de E / S se puede controlar desde cualquier máquina.
El diagrama superior de la ilustración refleja la arquitectura EMC XtremIO. A primera vista, es similar al Tipo 2, pero no lo es. En este caso, el modelo de metadatos distribuidos compartidos implica el uso de IB y acceso directo a memoria remota, de modo que todos los nodos tengan acceso a los metadatos. Además, cada nodo es un par HA. Como puede ver, Isilon y XtremIO son muy diferentes arquitectónicamente, aunque esto no es tan obvio. Sí, ambos tienen arquitecturas a escala horizontal, y ambos usan IB para la interconexión. Pero en Isilon, a diferencia de XtremIO, esto se hace para minimizar la latencia al intercambiar datos entre nodos. Además, en Isilon, puede usar Ethernet para comunicarse entre nodos (de hecho, así es como funciona una máquina virtual en él), pero esto aumenta la latencia durante las operaciones de E / S. En cuanto a XtremIO, el acceso directo a la memoria remota es de gran importancia para su rendimiento.
Por cierto, no se deje engañar por la presencia de dos diagramas en la ilustración; de hecho, son los mismos arquitectónicamente. En ambos casos, se utilizan pares de controladores HA, memoria compartida y interconexiones de muy baja latencia. Por cierto, VMAX usa un bus de interconexión patentado, pero en el futuro será posible usar IB.
Las arquitecturas altamente acopladas se caracterizan por la alta complejidad del código del programa. Esta es una de las razones de su baja prevalencia. La complejidad excesiva del software también afecta la cantidad de servicios de procesamiento de datos que se agregan, ya que esta es una tarea informática más difícil.
Las ventajas de este tipo de arquitectura incluyen tolerancia a fallas (E / S simétricas en todas las máquinas de control), así como, en el caso de XtremIO, grandes oportunidades en el campo de AFA. Dado que nuevamente estamos hablando de XtremIO, vale la pena mencionar que su arquitectura implica la distribución de todos los servicios de procesamiento de datos. También es la única solución AFA en el mercado con una arquitectura a escala horizontal, aunque todavía no se han implementado nodos dinámicos de adición / desactivación. Entre otras cosas, XtremIO utiliza deduplicación "natural", es decir, está constantemente activo y "libre" en términos de rendimiento. Es cierto que todo esto aumenta la complejidad del mantenimiento del sistema.
Es importante comprender la diferencia fundamental entre el Tipo 2 y el Tipo 3. Cuanto más interconectada esté la arquitectura, mejor y más predecible será garantizar una baja latencia. Por otro lado, dentro del marco de dicha arquitectura, es más difícil agregar nodos y escalar el sistema. Después de todo, cuando usa el acceso compartido a la memoria, es un sistema distribuido único y altamente conjugado. La complejidad de las decisiones está creciendo y, con ello, la probabilidad de errores. Por lo tanto, VMAX puede tener hasta 16 autos de control en 8 motores, y XtemIO - hasta 8 autos en 4 X-Brick (pronto aumentará a 16 autos en 8 bloques). Cuadruplicar o incluso duplicar estas arquitecturas es un desafío de ingeniería increíblemente difícil. A modo de comparación, VSAN se puede escalar a "tamaño de clúster vSphere" (ahora 32 nodos), Isilon puede contener más de 100 nodos y ScaleIO le permite crear un sistema de más de 1000 nodos. Además, todo esto es la arquitectura del segundo tipo.
Nuevamente, quiero enfatizar que la arquitectura es independiente de la implementación. Los productos anteriores usan Ethernet e IB. Algunos son soluciones puramente de software, otros son complejos de software y hardware, pero al mismo tiempo están unidos por esquemas arquitectónicos.
A pesar de la variedad de interconexiones, el uso de grabación distribuida juega un papel importante en todos los ejemplos dados. Esto le permite lograr transaccionalidad y atomicidad, pero al mismo tiempo es necesario un monitoreo cuidadoso de la integridad de los datos. También es necesario resolver el problema del crecimiento del "área de falla". Estos dos puntos limitan el máximo grado posible de escala de los tipos de arquitecturas descritos.
Una pequeña comprobación de cuán cuidadosamente lees todo lo anterior: ¿A qué tipo de Cisco UCS Invicta - 1 o 3 pertenece? Físicamente, se parece al Tipo 3, pero este es un conjunto de servidores USC C-Series conectados a través de Ethernet, que ejecutan la pila de software Invicta (anteriormente Whiptail). Sugerencia: mire la arquitectura, no la implementación específica 🙂
En el caso de UCS Invicta, los datos se almacenan en cada nodo (servidor UCS con unidades flash basadas en MLC). Un único nodo que no sea HA, que es un servidor separado, puede transmitir directamente un número de unidad lógica (LUN). Si decide agregar más nodos, es posible que el sistema escale mal, como ScaleIO o VSAN. Todo esto nos lleva al Tipo 2.
Sin embargo, un aumento en el número de nodos, aparentemente, se realiza a través de la configuración y la migración al "Invicta Scaling Appliance". Con esta configuración, tiene varios "Enrutadores de almacenamiento de silicio" (SSR) y un almacenamiento de direcciones de varios nodos de hardware. Se accede a los datos a través de un solo nodo SSR, pero esto se puede hacer a través de otro nodo que funciona como un par HA. Los datos en sí siempre están en el único nodo UCS de la serie C. Entonces, ¿qué tipo de arquitectura es esta? No importa cómo se vea físicamente la solución, es Tipo 1. El SSR es un clúster (quizás más de 2). En la configuración de Scaling Appliance, cada servidor UCS con unidades MLC realiza una función similar a VNX o NetApp FAS: almacenamiento en disco. Aunque no está conectado a través de SAS, la arquitectura es similar.
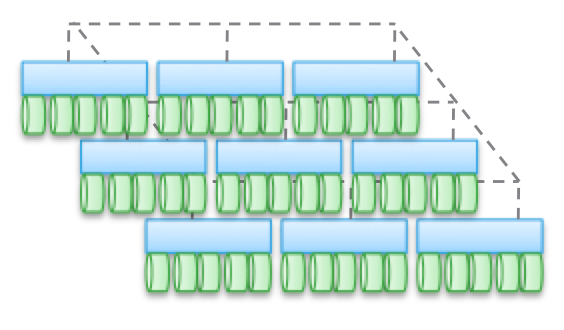
Tipo 4. Arquitecturas distribuidas sin compartir ningún recurso. A pesar del hecho de que los datos se distribuyen entre diferentes nodos, esto se hace sin ninguna transaccionalidad. Por lo general, los datos se almacenan en un solo nodo y viven allí, y de vez en cuando se hacen copias en otros nodos, en aras de la seguridad. Pero estas copias no son transaccionales. Esta es la diferencia clave entre este tipo de arquitectura y los tipos 2 y 3.
La comunicación entre nodos que no son HA es a través de Ethernet, ya que es barata y universal. La distribución por nodos es obligatoria y de vez en cuando. La "exactitud" de los datos no siempre se respeta, pero la pila de software se verifica con bastante frecuencia para garantizar la exactitud de los datos utilizados. Para algunos tipos de carga (por ejemplo, HDFS), los datos se distribuyen para estar en la memoria al mismo tiempo que el proceso para el que se requiere. Esta propiedad nos permite considerar este tipo de arquitectura como la más escalable entre las cuatro.
Pero esto está lejos de ser la única ventaja. Dichas arquitecturas son extremadamente simples; son muy fáciles de administrar. De ninguna manera dependen del equipo y pueden implementarse en el hardware más barato. Estas son casi siempre soluciones de software exclusivamente. Este tipo de arquitectura es tan fácil de manejar con petabytes de datos como terabytes con otros datos. Aquí se utilizan objetos y sistemas de archivos que no son POSIX, y ambos a menudo se encuentran en la parte superior del sistema de archivos local de cada nodo ordinario.
Estas arquitecturas se pueden combinar con bloques y modelos transaccionales de presentación de datos basados \u200b\u200ben NAS, pero esto limita enormemente sus capacidades. No es necesario crear una pila transaccional colocando el Tipo 1, 2 o 3 encima del Tipo 4.
Lo mejor de todo, estas arquitecturas se "revelan" en aquellas tareas para las cuales algunas restricciones no son peculiares.
Arriba, di un ejemplo con un cliente muy grande con 200,000 unidades. Servicios como Dropbox, Syncplicity, iCloud, Facebook, eBay, YouTube y casi todos los proyectos Web 2.0 se basan en repositorios creados con el cuarto tipo de arquitectura. Toda la información procesada en los clústeres de Hadoop también está contenida en repositorios de Tipo 4. En general, en el segmento corporativo, estas no son arquitecturas muy comunes, pero rápidamente ganan popularidad.
El Tipo 4 subyace a productos como AWS S3 (por cierto, nadie fuera de AWS sabe cómo funciona EBS, pero estoy dispuesto a argumentar que es Tipo 3), Haystack (utilizado en Facebook), Atmos, ViPR, Ceph, Swift ( utilizado en Openstack), HDFS, Centera. Muchos de los productos enumerados pueden adoptar una forma diferente, el tipo de implementación específica se determina utilizando su API. Por ejemplo, la pila de objetos ViPR se puede implementar a través de las API de objetos S3, Swift, Atmos e incluso HDFS. Y en el futuro, Centera también estará en esta lista. Para algunos, esto será obvio, pero Atmos y Centera se utilizarán durante mucho tiempo, sin embargo, en forma de API y no de productos específicos. Las implementaciones pueden cambiar, pero las API siguen siendo inquebrantables, lo cual es muy bueno para los clientes.
Quiero llamar su atención una vez más sobre el hecho de que la "encarnación física" puede ser confusa, y clasificará erróneamente las arquitecturas Tipo 4 como Tipo 2, ya que a menudo se ven iguales. A nivel físico, una solución puede parecerse a ScaleIO, VSAN o Nutanix, aunque estos serán solo servidores Ethernet. Y la presencia o ausencia de transaccionalidad ayudará a clasificar una solución particular correctamente.
Y ahora te ofrezco una segunda prueba de verificación. Veamos la arquitectura UCS Invicta. Físicamente, este producto se parece al Tipo 4 (servidores conectados a través de Ethernet), pero es imposible escalarlo arquitectónicamente a las cargas correspondientes, ya que en realidad es el Tipo 1. Además, Invicta, como Pure, se desarrolló para AFA.
Por favor, acepte mi sincero agradecimiento por su tiempo y atención, si ha leído hasta este lugar. Vuelvo a leer lo anterior, es sorprendente que logré casarme y tener hijos 🙂
¿Por qué escribí todo esto?
En el mundo del almacenamiento de TI, ocupan un lugar muy importante, una especie de "reino de los hongos". La variedad de productos que se ofrecen es muy grande, y esto solo beneficia a todo el negocio. Pero debe ser capaz de comprender todo esto, no se permita nublar su mente con eslóganes de marketing y matices de posicionamiento. Para el beneficio de los clientes y de la industria misma, es necesario simplificar el proceso de creación de almacenamiento. Por lo tanto, estamos trabajando duro para hacer que el controlador ViPR sea una plataforma abierta y gratuita.
Pero el repositorio en sí mismo no es emocionante. A que me refiero Imagine una especie de pirámide abstracta, sobre la cual hay un "usuario". A continuación se muestran las "aplicaciones" diseñadas para servir al "usuario". Aún más baja es la "infraestructura" (incluida SDDC) que sirve a las "aplicaciones" y, en consecuencia, al "usuario". Y en el fondo de la "infraestructura" se encuentra el repositorio.
Es decir, puede imaginar la jerarquía de esta forma: Usuario-\u003e Aplicación / SaaS-\u003e PaaS-\u003e IaaS-\u003e Infraestructura. Entonces: al final, cualquier aplicación, cualquier pila de PaaS debe calcular o procesar algún tipo de información. Y estos cuatro tipos de arquitecturas están diseñados para trabajar con diferentes tipos de información, diferentes tipos de carga. En la jerarquía de importancia, la información sigue inmediatamente al usuario. El propósito de la existencia de la aplicación es permitir al usuario interactuar con la información que necesita. Es por eso que la arquitectura de almacenamiento es tan importante en nuestro mundo.
Esta entrada fue publicada en Uncategorized por el autor. Marcarlo como favoritoY otras cosas, el medio de transmisión de datos y los servidores conectados a él. Por lo general, es utilizado por compañías lo suficientemente grandes con una infraestructura de TI bien desarrollada para el almacenamiento confiable de datos y el acceso de alta velocidad a ellos.
Simplificado, el almacenamiento es un sistema que le permite distribuir servidores confiables unidades rápidas capacitancia variable con diferentes dispositivos almacenamiento de datos
Un poco de teoría
El servidor se puede conectar al almacén de datos de varias maneras.
El primero y más simple es DAS, almacenamiento conectado directo (conexión directa), colocamos unidades en el servidor o una matriz en el adaptador del servidor, y obtenemos muchos gigabytes de espacio en disco con relativamente acceso rápido, y cuando se utiliza una matriz RAID: fiabilidad suficiente, aunque las lanzas sobre el tema de la fiabilidad se han estado rompiendo durante mucho tiempo.
Sin embargo, este uso del espacio en disco no es óptimo: en un servidor se agota el espacio, en el otro todavía hay mucho. La solución a este problema es NAS, almacenamiento conectado a la red (almacenamiento conectado a la red). Sin embargo, con todas las ventajas de esta solución (flexibilidad y administración centralizada), existe un inconveniente significativo: la velocidad de acceso, una red de 10 gigabits aún no se ha implementado en todas las organizaciones. Y llegamos a la red de almacenamiento.
La principal diferencia entre SAN y NAS (además del orden de las letras en abreviaturas) es cómo se ven los recursos conectados en el servidor. Si los recursos NAS están conectados a los protocolos NFS o SMB, en la SAN obtenemos una conexión al disco, con la que podemos trabajar al nivel de las operaciones de bloque de E / S, que es mucho más rápido conexión de red (además de un controlador de matriz con un gran caché agrega velocidad en muchas operaciones).
Usando SAN, combinamos las ventajas de DAS - velocidad y simplicidad, y NAS - flexibilidad y capacidad de control. Además, tenemos la capacidad de escalar los sistemas de almacenamiento hasta que haya suficiente dinero, al mismo tiempo que matamos a varias aves más de un tiro, que no son visibles de inmediato:
* eliminar restricciones en el rango de conexión de dispositivos SCSI, que generalmente se limitan a un cable de 12 metros,
* reducir el tiempo de respaldo,
* podemos arrancar desde SAN,
* en caso de rechazo del NAS, descargamos una red,
* obtenemos una alta velocidad de entrada-salida debido a la optimización en el lado del sistema de almacenamiento,
* tenemos la oportunidad de conectar varios servidores a un recurso, esto nos da las siguientes dos aves de un tiro:
- Utilizamos plenamente las capacidades de VMWare, por ejemplo VMotion (migración de máquinas virtuales entre máquinas físicas) y otras similares,
- podemos construir clústeres tolerantes a fallas y organizar redes distribuidas geográficamente.
Que da
Además de aprovechar el presupuesto para optimizar el sistema de almacenamiento, obtenemos, además de lo que escribí anteriormente:
* aumento de la productividad, equilibrio de carga y alta disponibilidad de sistemas de almacenamiento debido a varias formas de acceder a los arreglos;
* ahorro en discos al optimizar la ubicación de la información;
* recuperación acelerada de fallas: puede crear recursos temporales, implementar una copia de seguridad en ellos y conectar servidores a ellos, y restaurar la información usted mismo sin prisa, o transferir recursos a otros servidores y lidiar con calma con hierro muerto;
* Tiempo de copia de seguridad reducido: gracias a la alta velocidad de transferencia, puede realizar copias de seguridad en la biblioteca de cintas más rápido, o incluso tomar una instantánea (instantánea) del sistema de archivos y archivarla de manera segura;
* espacio en disco bajo demanda, cuando lo necesitamos, siempre puede agregar un par de estantes al sistema de almacenamiento de datos.
* reducir el costo de almacenar un megabyte de información; por supuesto, hay un cierto umbral a partir del cual estos sistemas son rentables.
* Un lugar confiable para almacenar datos críticos de misión y negocios (sin los cuales la organización no puede existir y funcionar normalmente).
* Quiero mencionar VMWare por separado: todos los chips, como la migración de máquinas virtuales de un servidor a otro y otras ventajas, solo están disponibles en la SAN.
¿En que consiste?
Como escribí anteriormente, el almacenamiento consiste en dispositivos de almacenamiento, medios de transmisión y servidores conectados. Consideremos en orden:
Sistemas de almacenamiento de datos generalmente consiste en discos duros y controladores, en un sistema que se respeta a sí mismo, generalmente solo 2 - 2 controladores, 2 rutas a cada unidad, 2 interfaces, 2 fuentes de alimentación, 2 administradores. De los fabricantes de sistemas más respetados, vale la pena mencionar a HP, IBM, EMC e Hitachi. Aquí cito a un representante de EMC en el seminario: “HP fabrica excelentes impresoras. ¡Deja que ella los haga! Sospecho que HP también es muy aficionado a EMC. Sin embargo, la competencia entre fabricantes es grave, como en otros lugares. Las consecuencias de la competencia a veces son precios razonables por megabyte del sistema de almacenamiento y problemas con la compatibilidad y el soporte de los estándares de la competencia, especialmente para equipos viejos.
Medio de transferencia de datos.
Por lo general, las SAN se basan en la óptica, que actualmente ofrece una velocidad de 4, a veces 8 gigabits por canal. Al construir, antes se usaban centros especializados, ahora hay más conmutadores, principalmente de Qlogic, Brocade, McData y Cisco (nunca he visto los dos últimos en los sitios). Los cables se usan tradicionalmente para redes ópticas: monomodo y multimodo, monomodo más largo.
En el interior, se utiliza FCP: Protocolo de canal de fibra, un protocolo de transporte. Por lo general, el SCSI clásico se ejecuta dentro de él y FCP proporciona direccionamiento y entrega. Hay una opción con una conexión a través de una red regular e iSCSI, pero generalmente usa (y carga mucho) una red local, en lugar de una dedicada para la transferencia de datos, y requiere adaptadores con soporte iSCSI, bueno, la velocidad es más lenta que en la óptica.
También hay una topología de palabras inteligente, que se encuentra en todos los libros de texto en SAN. Hay varias topologías, la opción más simple es punto a punto, conectamos 2 sistemas. Esto no es DAS, pero un caballo esférico al vacío es la versión más simple de SAN. Luego viene el lazo controlado (FC-AL), funciona según el principio de "transmisión": el transmisor de cada dispositivo está conectado al receptor del siguiente, los dispositivos están cerrados en un anillo. Las cadenas largas tienden a inicializarse durante mucho tiempo.
Bueno, la opción final: una estructura conmutada (Fabric), se crea utilizando interruptores. La estructura de las conexiones se construye dependiendo del número de puertos conectados, como en la construcción de una red local. El principio básico de la construcción es que todos los caminos y conexiones están duplicados. Esto significa que hay al menos 2 rutas diferentes a cada dispositivo en la red. Aquí también se usa la palabra topología, en el sentido de organizar un diagrama de conexión del dispositivo y conectar interruptores. En este caso, por regla general, los conmutadores se configuran para que los servidores no vean nada más que los recursos destinados a ellos. Esto se logra mediante la creación de redes virtuales y se llama zonificación, la analogía más cercana es VLAN. A cada dispositivo en la red se le asigna una dirección MAC analógica en la red Ethernet, se llama WWN - World Wide Name. Se asigna a cada interfaz y cada recurso (LUN) de los sistemas de almacenamiento. Las matrices y los conmutadores pueden distinguir entre el acceso WWN para los servidores.
Servidor Conéctese al almacenamiento a través de HBA - Adaptadores de bus host. Por analogía con las tarjetas de red, hay adaptadores de uno, dos y cuatro puertos. Los mejores "criadores de perros" recomiendan instalar 2 adaptadores por servidor, esto permite tanto el equilibrio de carga como la confiabilidad.
Y luego los recursos se recortan en los sistemas de almacenamiento, son los discos (LUN) para cada servidor y se deja un lugar en la reserva, todo se enciende, los instaladores del sistema prescriben la topología, detectan fallas en la configuración de los interruptores y el acceso, todo comienza y todos viven felices para siempre *.
Específicamente, no toco diferentes tipos de puertos en la red óptica, quien lo necesite, ya lo sabe o lee, quién no lo necesita, solo martillea su cabeza. Pero, como de costumbre, si el tipo de puerto está configurado incorrectamente, nada funcionará.
Por experiencia.
Por lo general, al crear una SAN, solicite matrices con varios tipos de discos: FC para aplicaciones de alta velocidad y SATA o SAS para aplicaciones no muy rápidas. Por lo tanto, se obtienen 2 grupos de discos con un costo de megabytes diferente: caro y rápido, y lento y tristemente barato. Por lo general, todas las bases de datos y otras aplicaciones con E / S activas y rápidas se bloquean en la rápida, mientras que los recursos de archivos y todo lo demás se cuelgan en la lenta.
Si una SAN se crea desde cero, tiene sentido construirla sobre la base de las soluciones de un fabricante. El hecho es que, a pesar del cumplimiento declarado de las normas, existen rastrillos submarinos del problema de compatibilidad del equipo, y no el hecho de que parte del equipo funcionará entre sí sin bailar con una pandereta y consultar con los fabricantes. Por lo general, para abordar estos problemas, es más fácil llamar a un integrador y darle dinero que comunicarse con los fabricantes cambiando flechas entre sí.
Si la SAN se crea sobre la base de la infraestructura existente, todo puede ser complicado, especialmente si hay matrices SCSI antiguas y un zoológico de equipos antiguos de diferentes fabricantes. En este caso, tiene sentido pedir ayuda a la terrible bestia de un integrador que resolverá los problemas de compatibilidad y hará una tercera villa en las Islas Canarias.
A menudo, al crear sistemas de almacenamiento, las empresas no solicitan asistencia del fabricante para el sistema. Esto generalmente se justifica si la empresa cuenta con un personal de administradores competentes competentes (que ya me han llamado hervidor de agua 100 veces) y una buena cantidad de capital, lo que permite comprar piezas de repuesto en las cantidades requeridas. Sin embargo, los integradores atraen a los administradores competentes (yo mismo lo vi), pero no asignan dinero para la compra, y después de los fracasos, un circo comienza con gritos de "¡despediré a todos!" en lugar de llamar al soporte y la llegada de un ingeniero con una pieza de repuesto.
El soporte generalmente se reduce a reemplazar discos y controladores muertos, y a agregar repisas de discos y nuevos servidores al sistema. Suceden muchos problemas después de una prevención repentina del sistema por parte de especialistas locales, especialmente después de un apagado completo y desmontaje-montaje del sistema (y esto sucede).
Sobre VMWare Hasta donde yo sé (los especialistas en virtualización me corrigen), solo VMWare e Hyper-V tienen una funcionalidad que le permite transferir máquinas virtuales entre servidores físicos sobre la marcha. Y para su implementación, se requiere que todos los servidores entre los que se mueve la máquina virtual estén conectados al mismo disco.
Sobre los racimos. Al igual que en el caso de VMWare, los sistemas que conozco para construir clústeres de conmutación por error (Sun Cluster, Veritas Cluster Server) requieren almacenamiento conectado a todos los sistemas.
Mientras escribían un artículo, me preguntaron, ¿en qué RAID suelen combinar las unidades?
En mi práctica, generalmente hicieron RAID 1 + 0 en cada estante de disco con discos FC, dejando 1 disco de repuesto (repuesto dinámico) y cortaron LUN de esta pieza para tareas, o hicieron RAID5 desde discos lentos, dejando nuevamente 1 disco para el reemplazo Pero aquí la pregunta es compleja, y generalmente la forma de organizar discos en una matriz se selecciona para cada situación y se justifica. El mismo EMC, por ejemplo, va aún más lejos, y tienen ajuste adicional matriz para aplicaciones que funcionan con él (por ejemplo, bajo OLTP, OLAP). No profundicé tanto con los otros proveedores, pero supongo que todos tienen un ajuste fino.
* antes de la primera falla importante, después de lo cual el soporte generalmente se compra al fabricante o proveedor del sistema.
DAS, SAN, NAS: abreviaturas mágicas, sin las cuales ni un solo artículo ni ningún estudio analítico de sistemas de almacenamiento pueden hacer. Sirven como la designación de los principales tipos de conexión entre los sistemas de almacenamiento y los sistemas informáticos.
Das (almacenamiento de conexión directa) - dispositivo memoria externadirectamente conectado a la computadora principal y utilizado solo por él. El ejemplo más simple de DAS es el incorporado disco duro. Para conectar el host con memoria externa en una configuración DAS típica, se utiliza SCSI, cuyos comandos le permiten seleccionar un bloque de datos específico en un disco específico o montar un cartucho específico en una biblioteca de cintas.
Las configuraciones DAS son aceptables para los requisitos de almacenamiento, capacidad y confiabilidad. DAS no proporciona la capacidad de compartir la capacidad de almacenamiento entre diferentes hosts, y menos aún la capacidad de compartir datos. Instalar dichos dispositivos de almacenamiento es una opción más barata que las configuraciones de red; sin embargo, dadas las grandes organizaciones, este tipo de infraestructura de almacenamiento no puede considerarse óptima. Muchas conexiones DAS significan islas de memoria externa que están dispersas y dispersas por toda la compañía, cuyo exceso no puede ser utilizado por otras computadoras host, lo que conduce a un desperdicio ineficiente de capacidad de almacenamiento en general.
Además, con una organización de almacenamiento de este tipo, no hay forma de crear un único punto de administración de la memoria externa, lo que inevitablemente complica los procesos de copia de seguridad / recuperación de datos y crea un grave problema de protección de la información. Como resultado, el costo total de propiedad de dicho sistema de almacenamiento puede ser significativamente más alto que el más complejo a primera vista y la configuración de red inicialmente más costosa.
San
Hoy, hablando de un sistema de almacenamiento de nivel empresarial, nos referimos al almacenamiento en red. Mejor conocido por el público en general es la red de almacenamiento - SAN (red de área de almacenamiento). SAN es una red dedicada de dispositivos de almacenamiento que permite que varios servidores utilicen el recurso total de memoria externa sin la carga en la red local.

SAN es independiente del medio de transmisión, pero en este momento el estándar real es la tecnología Fibre Channel (FC), que proporciona una velocidad de transferencia de datos de 1-2 Gb / s. A diferencia de los medios de transmisión tradicionales basados \u200b\u200ben SCSI, que proporcionan una conectividad de no más de 25 metros, Fibre Channel le permite trabajar a una distancia de hasta 100 km. Los medios de red Fibre Channel pueden ser cobre o fibra.
El disco se puede conectar a la red de almacenamiento matrices RAID, matrices de discos simples, (las llamadas Just a Bunch of Disks - JBOD), bibliotecas de cintas o magnetoópticas para realizar copias de seguridad y archivar datos. Los componentes principales para organizar una red SAN, además de los dispositivos de almacenamiento en sí, son adaptadores para conectar servidores a una red Fibre Channel (adaptador de bus host - NVA), dispositivos de red para soportar una u otra topología de red FC y herramientas de software especializadas para administrar una red de almacenamiento. Estos sistemas de software se puede realizar tanto en un servidor de propósito general como en los dispositivos de almacenamiento, aunque a veces algunas de las funciones se transfieren a un servidor delgado especializado para administrar la red de almacenamiento (dispositivo SAN).
El objetivo del software SAN es principalmente administrar de forma centralizada la red de almacenamiento, incluida la configuración, el monitoreo, el control y el análisis de los componentes de la red. Una de las más importantes es la función de control de acceso a las matrices de discos, si se almacenan servidores heterogéneos en la SAN. Las redes de almacenamiento permiten que varios servidores accedan a múltiples subsistemas de disco a la vez, asignando cada host a discos específicos en una matriz de discos específica. Para diferentes sistemas operativos, es necesario estratificar la matriz de discos en "unidades lógicas" (unidades lógicas - LUN), que utilizarán sin conflictos. La asignación de áreas lógicas puede ser necesaria para organizar el acceso a los mismos datos para un determinado grupo de servidores, por ejemplo, servidores del mismo grupo de trabajo. Los módulos de software especiales son responsables de soportar todas estas operaciones.
El atractivo de las redes de almacenamiento se explica por las ventajas que pueden brindar a las organizaciones que exigen la eficiencia de trabajar con grandes volúmenes de datos. Una red de almacenamiento dedicada descarga la red principal (local o global) de servidores informáticos y estaciones de trabajo del cliente, liberándola de los flujos de entrada / salida de datos.

Este factor, así como el medio de transmisión de alta velocidad utilizado para SAN, proporciona una mayor productividad de los procesos de intercambio de datos con sistemas de almacenamiento externo. SAN significa la consolidación de los sistemas de almacenamiento, la creación de un único grupo de recursos en diferentes medios que serán compartidos por toda la potencia informática y, como resultado, la capacidad de memoria externa requerida se puede proporcionar con menos subsistemas. En SAN, la copia de seguridad de los datos de los subsistemas de disco en cintas se realiza fuera de la red local y, por lo tanto, se vuelve más eficiente: una biblioteca de cintas se puede utilizar para hacer una copia de seguridad de los datos de varios subsistemas de disco. Además, con el soporte del software correspondiente, es posible implementar una copia de seguridad directa en la SAN sin la participación del servidor, descargando así el procesador. La capacidad de desplegar servidores y memoria a largas distancias satisface las necesidades de mejorar la confiabilidad de los almacenes de datos empresariales. El almacenamiento de datos consolidado en la SAN se escala mejor porque le permite aumentar la capacidad de almacenamiento independientemente de los servidores y sin interrumpir su trabajo. Finalmente, la SAN permite la administración centralizada de un único grupo de memoria externa, lo que simplifica la administración.
Por supuesto, las redes de almacenamiento son una solución costosa y difícil, y a pesar del hecho de que todos los proveedores líderes de la actualidad producen dispositivos SAN basados \u200b\u200ben Fibre Channel, su compatibilidad no está garantizada, y la elección del equipo adecuado plantea un problema para los usuarios. Se requerirán costos adicionales para configurar una red dedicada y un software de administración de compras, y el costo inicial de la SAN será más alto que la organización del almacenamiento usando DAS, pero el costo total de propiedad debería ser menor.
NAS
A diferencia de SAN, NAS (almacenamiento conectado a la red) no es una red, sino un dispositivo de almacenamiento en red, más precisamente, un servidor de archivos dedicado con un subsistema de disco conectado a él. En ocasiones, se puede incluir una biblioteca óptica o de cinta en la configuración del NAS. El dispositivo NAS (dispositivo NAS) está conectado directamente a la red y brinda a los hosts acceso a los archivos en su subsistema de memoria externa integrado. La aparición de servidores de archivos dedicados está asociada con el desarrollo del sistema de archivos de red NFS por parte de Sun Microsystems a principios de los años 90, lo que permitió a las computadoras cliente en la red local usar archivos en un servidor remoto. Luego, a Microsoft se le ocurrió un sistema similar para el entorno de Windows: el Sistema de archivos de Internet común. Las configuraciones NAS son compatibles con estos dos sistemas, así como con otros protocolos basados \u200b\u200ben IP, lo que permite compartir archivos para las aplicaciones del cliente.

El dispositivo NAS se asemeja a la configuración DAS, pero difiere fundamentalmente de él en que proporciona acceso a nivel de archivo, no a bloques de datos, y permite que todas las aplicaciones en la red compartan archivos en sus discos. NAS especifica un archivo en el sistema de archivos, el desplazamiento en este archivo (que se representa como una secuencia de bytes) y el número de bytes para leer o escribir. Una solicitud a un dispositivo NAS no determina el volumen o sector en el disco donde se encuentra el archivo. La tarea del sistema operativo de un dispositivo NAS es traducir una llamada a un archivo específico en una solicitud a nivel de bloque de datos. El acceso a archivos y la capacidad de compartir información son convenientes para aplicaciones que deberían servir a muchos usuarios al mismo tiempo, pero no requieren la descarga de grandes cantidades de datos para cada solicitud. Por lo tanto, se está convirtiendo en una práctica común usar NAS para aplicaciones de Internet, servicios web o CAD, en el que cientos de especialistas trabajan en un proyecto.
La opción NAS es fácil de instalar y administrar. A diferencia de una red de almacenamiento, la instalación de un dispositivo NAS no requiere una planificación especial y costos para software de administración adicional: solo conecte el servidor de archivos a la red local. El NAS libera a los servidores de la red de las tareas de administración de almacenamiento, pero no descarga el tráfico de la red, ya que los datos se intercambian entre los servidores de uso general y el NAS en la misma red local. Se pueden configurar uno o más en el NAS sistemas de archivos, cada uno de los cuales tiene asignado un conjunto específico de volúmenes en el disco. A todos los usuarios del mismo sistema de archivos se les asigna algo de espacio en disco a pedido. Por lo tanto, el NAS proporciona una organización y un uso más eficiente de los recursos de memoria en comparación con el DAS, ya que el subsistema de almacenamiento conectado directamente solo sirve a un recurso informático, y puede suceder que un servidor en la red local tenga demasiada memoria externa, mientras que otro se está quedando sin espacio en disco. Pero es imposible crear un único grupo de recursos de almacenamiento a partir de varios dispositivos NAS y, por lo tanto, un aumento en el número de nodos NAS en la red complicará la tarea de administración.
NAS + SAN \u003d?
¿Qué tipo de infraestructura de almacenamiento elegir: NAS o SAN? La respuesta depende de las capacidades y necesidades de la organización, sin embargo, es básicamente incorrecto compararlas o incluso contrastarlas, ya que estas dos configuraciones resuelven problemas diferentes. El acceso a archivos y el intercambio de información para aplicaciones en plataformas de servidor heterogéneas en la red local es el NAS. Acceso en bloque de alto rendimiento a bases de datos, consolidación de almacenamiento, que garantiza su fiabilidad y eficiencia: estas son SAN. En la vida, sin embargo, todo es más complicado. NAS y SAN a menudo ya coexisten o deben implementarse simultáneamente en la infraestructura de TI distribuida de la empresa. Esto inevitablemente crea problemas de gestión y utilización del almacenamiento.
Hoy en día, los fabricantes buscan formas de integrar ambas tecnologías en una única infraestructura de almacenamiento de red que consolide los datos, centralice las copias de seguridad, simplifique la administración general, la escalabilidad y la protección de datos. La convergencia de NAS y SAN es una de las tendencias más importantes de los últimos tiempos.
La red de almacenamiento le permite crear un grupo único de recursos de memoria y asignar a nivel físico la cuota necesaria de espacio en disco para cada uno de los hosts conectados a la SAN. El servidor NAS proporciona el intercambio de datos en el sistema de archivos mediante aplicaciones en diferentes plataformas operativas, resolviendo los problemas de interpretación de la estructura del sistema de archivos, sincronizando y controlando el acceso a los mismos datos. Por lo tanto, si queremos agregar a la red de almacenamiento la capacidad de separar no solo los discos físicos, sino también la estructura lógica de los sistemas de archivos, necesitamos un servidor de administración intermedio para implementar todas las funciones de los protocolos de red para procesar las solicitudes a nivel de archivo. De ahí el enfoque general para combinar SAN y NAS utilizando un dispositivo NAS sin un subsistema de disco integrado, pero con la capacidad de conectar componentes de red de almacenamiento. Dichos dispositivos, que son llamados puertas de enlace NAS por algunos fabricantes y por otras unidades principales NAS, se convierten en una especie de búfer entre la red local y la SAN, proporcionando acceso a los datos en la SAN a nivel de archivo y compartiendo información en la red de almacenamiento.
Resumen
La creación de sistemas de red unificados que combinen las capacidades de SAN y NAS es solo uno de los pasos hacia la integración global de los sistemas de almacenamiento empresarial. Las matrices de discos conectadas directamente a servidores individuales ya no satisfacen las necesidades de grandes organizaciones con complejas infraestructuras distribuidas de TI. Hoy en día, las redes de almacenamiento simplemente basadas en tecnología Fibre Channel de alto rendimiento pero especializada se consideran no solo un gran avance, sino también una fuente de dolor de cabeza debido a la complejidad de la instalación, los problemas con el soporte de hardware y software de diferentes proveedores. Sin embargo, el hecho de que los recursos de almacenamiento deben estar unificados y conectados en red ya no está en duda. Se buscan formas para una consolidación óptima. De ahí la activación de fabricantes de soluciones que soportan varias opciones para transferir redes de almacenamiento al protocolo IP]. De ahí el gran interés en diversas implementaciones del concepto de virtualización de almacenamiento. Los jugadores líderes en el mercado del almacenamiento no solo combinan todos sus productos bajo un encabezado común (TotalStorage para IBM o SureStore para HP), sino que formulan sus propias estrategias para crear infraestructuras de almacenamiento de red consolidadas y proteger los datos corporativos. El papel clave en estas estrategias será desempeñado por la idea de virtualización, respaldada principalmente a nivel de soluciones de software potentes para la gestión centralizada del almacenamiento distribuido. En iniciativas como StorageTank de IBM, Gestión de área de almacenamiento federado de HP, E-Infrostructure de EMC, el software juega un papel crucial.
Si los servidores son dispositivos universales que funcionan en la mayoría de los casos
- una función del servidor de aplicaciones (cuando se ejecuta en el servidor programas especiales, y hay cálculos intensivos)
- ya sea una función de servidor de archivos (es decir, un lugar determinado para el almacenamiento centralizado de archivos de datos)
luego SHD (Data Storage Systems): dispositivos especialmente diseñados para realizar funciones de servidor como el almacenamiento de datos.
La necesidad de almacenamiento
generalmente surge en empresas suficientemente maduras, es decir aquellos que piensan en cómo
- almacenar y administrar información, el activo más valioso de la compañía
- Garantizar la continuidad del negocio y la protección contra la pérdida de datos.
- aumentar la adaptabilidad de la infraestructura de TI
Almacenamiento y virtualización
La competencia obliga a las PYME a trabajar de manera más eficiente, sin tiempo de inactividad y con alta eficiencia. El cambio de modelos de producción, planes tarifarios, tipos de servicios está sucediendo cada vez más a menudo. Todo el negocio de las empresas modernas está "vinculado" a tecnología de la información. Las necesidades comerciales cambian rápidamente y afectan instantáneamente a TI: los requisitos de confiabilidad y adaptabilidad de la infraestructura de TI están creciendo. La virtualización proporciona estas capacidades, pero requiere sistemas de almacenamiento de bajo costo y fáciles de mantener.
Clasificación de almacenamiento por tipo de conexión
Das. Las primeras matrices de discos conectadas a los servidores a través de SCSI. Al mismo tiempo, un servidor podría funcionar con una sola matriz de discos. Esta es una conexión de almacenamiento directo (DAS - Almacenamiento conectado directo).
NAS. Para una organización más flexible de la estructura del centro de datos, para que cada usuario pueda usar cualquier sistema de almacenamiento, es necesario conectar el sistema de almacenamiento a la red local. Esto es NAS - Almacenamiento conectado a la red). Pero el intercambio de datos entre el servidor y el sistema de almacenamiento es muchas veces más intenso que entre el cliente y el servidor, por lo tanto, en esta versión hubo dificultades objetivas asociadas con el ancho de banda de la red Ethernet. Y desde el punto de vista de la seguridad, no es del todo correcto mostrar los sistemas de almacenamiento en una red común.
San. Pero puede crear su propia red separada de alta velocidad entre servidores y almacenamiento. Dicha red se llamaba SAN (Red de área de almacenamiento). El rendimiento está garantizado por el hecho de que el medio de transmisión física allí es óptico. Los adaptadores especiales (HBA) y los conmutadores ópticos FC proporcionan transmisión de datos a velocidades de 4 y 8 Gbit / s. La fiabilidad de dicha red se mejoró mediante la redundancia (duplicación) de canales (adaptadores, conmutadores). La principal desventaja es el alto precio.
iSCSI. Con la llegada de las tecnologías Ethernet de bajo costo de 1 Gbit / sy 10 Gbit / s, la óptica con una velocidad de transmisión de 4 Gbit / s ya no parece tan atractiva, especialmente teniendo en cuenta el precio. Por lo tanto, el protocolo iSCSI (Internet Small Computer System Interface) se usa cada vez más como un entorno SAN. Una SAN iSCSI se puede construir sobre cualquier base física lo suficientemente rápida que admita el protocolo IP.
Clasificación de sistemas de almacenamiento por aplicación:
| la clase | la descripcion |
| personal |
La mayoría de las veces son discos duros normales de 3.5 "o 2.5" o 1.8 ", colocados en un estuche especial y equipados con USB y / o FireWire 1394 y / o Ethernet, y / o interfaces eSATA. |
pequeño grupo de trabajo  |
Por lo general, este es un dispositivo estacionario o portátil en el que puede instalar varios discos duros SATA (con mayor frecuencia de 2 a 5), \u200b\u200bcon o sin intercambio en caliente, que tengan una interfaz Ethernet. Los discos se pueden organizar en matrices RAID de varios niveles para lograr una alta confiabilidad de almacenamiento y velocidad de acceso. El sistema de almacenamiento tiene un sistema operativo especializado, generalmente basado en Linux, y le permite diferenciar el nivel de acceso por nombre de usuario y contraseña, organizar cuotas de espacio en disco, etc. |
|
grupo de trabajo |
El dispositivo generalmente está montado en un rack de 19 "(montaje en rack) en el que puede instalar unidades HotSwap intercambiables en caliente SATA o SAS de 12-24. Tiene una interfaz externa Ethernet o iSCSI. Las unidades están organizadas en matrices RAID para lograr un alto fiabilidad del almacenamiento y velocidad de acceso. El almacenamiento viene con un software especializado que le permite diferenciar los niveles de acceso, organizar cuotas para el espacio en disco, organizar BackUp ( copia de seguridad información), etc. Dichos sistemas de almacenamiento son adecuados para empresas medianas y grandes, y se utilizan junto con uno o más servidores. |
empresa   |
Un dispositivo estacionario o un dispositivo montado en un bastidor de 19 "(montaje en bastidor) en el que puede instalar hasta cientos de discos duros. Además de la clase anterior, los sistemas de almacenamiento pueden tener la capacidad de construir, actualizar y reemplazar componentes sin detener el sistema de monitoreo. El software puede admitir instantáneas y otras funciones avanzadas. Estos sistemas de almacenamiento son adecuados para grandes empresas y brindan mayor confiabilidad, velocidad y protección de datos críticos. |
|
empresa de alta gama |
Además de la clase anterior, el almacenamiento puede admitir miles de discos duros. |


La historia del problema.
Los primeros servidores combinaron todas las funciones (como las computadoras) en un paquete: tanto la informática (servidor de aplicaciones) como el almacenamiento de datos (servidor de archivos). Pero a medida que la demanda de aplicaciones en potencia informática aumenta, por un lado, y la cantidad de datos procesados, por otro lado, se ha vuelto simplemente inconveniente colocar todo en un paquete. Resultó ser más eficiente sacar matrices de discos en casos separados. Pero aquí surgió la cuestión de conectar la matriz de discos al servidor. Las primeras matrices de discos conectadas a los servidores a través de SCSI. Pero en este caso, un servidor podría funcionar con una sola matriz de discos. La gente quería una organización más flexible de la estructura del centro de datos, para que cualquier servidor pudiera usar cualquier sistema de almacenamiento. Conectar todos los dispositivos directamente a la red local y organizar el intercambio de datos a través de Ethernet es, por supuesto, una solución simple y universal. Pero el intercambio de datos entre servidores y almacenamiento es muchas veces más intenso que entre clientes y servidores, por lo que en esta versión (NAS - ver más abajo) hubo dificultades objetivas asociadas con el ancho de banda de la red Ethernet. Hubo una idea para crear una red de alta velocidad separada entre los servidores y el almacenamiento. Dicha red se llamaba SAN (ver más abajo). Es similar a Ethernet, solo el medio de transmisión física allí es óptico. También hay adaptadores (HBA) que se instalan en servidores y conmutadores (ópticos). Estándares para la velocidad de transmisión de datos para la óptica: 4 Gbit / s. Con el advenimiento de las tecnologías Ethernet de 1 Gbit / sy 10 Gbit / s, así como del protocolo iSCSI, Ethernet se usa cada vez más como un entorno SAN.