În acest tutorial, vom acoperi elementele de bază ale lucrului cu evenimente, atribute și getElementById în JavaScript.
În lecțiile anterioare, am studiat caracteristicile de bază ale limbajului JavaScript. Începând cu această lecție, vom face ceea ce este destinat JavaScript - vom schimba elementele paginii HTML și vom răspunde la acțiunile utilizatorului. Scripturile noastre vor deveni mai spectaculoase și mai utile.
Să începem prin a ne învăța codul să răspundă la acțiunile utilizatorului site-ului. De exemplu, utilizatorul face clic undeva cu mouse-ul, iar codul nostru ca răspuns va trebui să proceseze acest clic și să afișeze câteva informații pe ecran.
Acțiunile utilizatorului pe care le putem urmări prin JavaScript se numesc evenimente. Evenimentele pot fi: strigăt mouse-ul pe un element de pagină, îndrumare mouse-ul pe elementul paginii sau invers - îngrijire cursorul mouse-ului de pe element și așa mai departe. În plus, există evenimente care nu depind de acțiunile utilizatorului, de exemplu, un eveniment când o pagină HTML este încărcată în browser.
Există mai multe moduri de a lucra cu evenimente în JavaScript. Vom începe cu cele mai simple dintre ele.
Elementele de bază ale evenimentelorCea mai ușoară modalitate de a seta răspunsul unui element la un anumit eveniment este să îl specificați folosind un atribut pe o anumită etichetă. De exemplu, evenimentul "clic de mouse" se potrivește cu atributul onclick, eveniment "hover mouse-ul" este atributul onmouseover și evenimentul „element care părăsește cursorul”- atributul onmouseout.
Valoarea atributului evenimentului este codul JavaScript. În exemplul următor făcând clic pe butonul funcția de alertă va fi executată:
Si acum prin clic funcția func va fi executată pe elementul:
func() (alerta("!"); )
Puteți îndeplini nu o funcție, ci mai multe:
funcția func1() ( alert("1"); ) funcția func2() ( alert("2"); )
Rețineți că, dacă aveți nevoie de ghilimele duble în interiorul unui atribut (de exemplu, pentru un șir) și ghilimelele exterioare ale atributului sunt, de asemenea, duble - onclick="alerta ("!")"- acest cod nu va funcționa.
Puteți face față acestui lucru în mai multe moduri: puteți schimba ghilimelele exterioare în simple onclick="alerta ("!")", puteți scăpa și de ghilimele interioare cu o bară oblică inversă onclick="alert(\"!\")" sau pur și simplu transferați codul JavaScript din atribut în funcție și lăsați doar numele funcției în atribut onclick="func()".
Același lucru se va întâmpla dacă setați ghilimelele exterioare ale atributului la single și, de asemenea, folosiți ghilimele simple pentru șir: onclick="alerta ("!")"- si aici totul se rezolva in moduri similare.
Tabel de atribute pentru evenimente Lucrul cu getElementByIdAcum vom învăța cum să primim elemente ale paginii HTML și să efectuăm diverse manipulări cu acestea (vom putea schimba, de exemplu, textul și culoarea acestora și multe alte lucruri utile).
Să presupunem că avem o etichetă pe pagină cu atributul id setat pentru a testa . Să scriem un link către această etichetă în variabila elem. Pentru a face acest lucru, trebuie să folosim metoda getElementById, care primește elementul după id-ul său.
Această înregistrare se va face la un clic pe butonul căruia i-am dat atributul onclick. Când se face clic pe acest buton, funcția func va funcționa, care va găsi un element pe pagina HTML cu un id egal cu testarea și scrierea link la acesta la variabila element:
Acum, în variabila elem avem o referință la elementul cu atributul id setat la test. Variabila elem în sine este obiect.
Acest obiect și eticheta paginii HTML sunt conectate între ele - putem schimba orice proprietăți ale obiectului elem și, în același timp, vom vedea modificările pe pagina HTML care se vor întâmpla cu elementul primit.
Să vedem cum se întâmplă acest lucru în practică.
Elementele de bază ale lucrului cu atribute HTML prin JavaScriptAcum vom citi și vom schimba atributele etichetei. Să avem din nou o intrare cu un id egal cu test și un buton care, atunci când este apăsat, va lansa funcția func:
În interiorul funcției func vom primi intrarea noastră prin id-ul săuși scrieți o referință la acesta în variabila elem:
funcția func() ( var elem = document.getElementById("test"); )
Să afișăm acum conținutul atributelor intrărilor noastre. Pentru a accesa, de exemplu, atributul value, ați scrie următoarele: elem.value , unde elem este variabila pe care am stabilit referința la elementul nostru cu getElementById , iar value este atributul etichetei care ne interesează.
Putem afișa conținutul atributului prin alertă în acest fel - alert(elem.value) - sau îl putem scrie într-o variabilă. Să o facem:
funcția func() (var elem = document.getElementById("test"); alert(elem.value); //afișează "!")
Putem citi valorile altor atribute în același mod, de exemplu - elem.id - luăm în considerare valoarea atributului id, iar în acest fel - elem.type - valoarea atributului tip. Vezi exemplu:
funcția func() ( var elem = document.getElementById("test"); alert(elem.value); //printează "!" alert(elem.id); //printează alertă "test" (elem.type); // scoate „text” )
Nu numai că puteți citi valorile atributelor, ci și le puteți modifica. Pentru a modifica, de exemplu, valoarea atributului value, trebuie doar să-l atribui constructului elem.value:
funcția func() ( var elem = document.getElementById("test"); elem.value = "www"; //присвоим новое значение атрибуту value } !}
Codul HTML va arăta astfel (valoarea atributului valoare va deveni www):
Ei bine, acum cel mai dificil lucru este că nu puteți introduce variabila elem, ci construiți un lanț de puncte în acest fel:
funcția func() ( alert(document.getElementById("test").value); //afișează "!")
În același mod (într-un lanț) puteți suprascrie și atribute:
funcția func() ( document.getElementById("test").value = "www"; }!}
Cu toate acestea, în majoritatea cazurilor, introducerea unei variabile este mai convenabilă. Comparați cele două exemple - acum am introdus variabila elem și pot citi orice număr de atribute, în timp ce getElementById este numit doar o dată:
funcția func() ( var elem = document.getElementById("test"); elem.value = "www"; elem.type = "submit"; }!}
Și acum nu introduc o nouă variabilă, așa că trebuie să apelez getElementById de două ori:
funcția func() ( document.getElementById("test").value = "www"; document.getElementById("test").type = "submit"; }!}
După părerea mea, acest cod a devenit mai complicat, deși este nevoie de o linie mai puțin. În plus, dacă vreau să schimb valoarea id din test în, de exemplu, www, trebuie să fac asta în multe locuri, ceea ce nu este foarte convenabil.
către browser. Căutarea elementelor pe pagină, ceea ce face metoda getElementById, este o operație destul de lentă ( și, în general, orice lucru cu elemente de pagină este o operațiune lentă- tine minte asta).În cazul nostru, dacă folosim getElementById de fiecare dată, atunci browserul va procesa pagina HTML de fiecare dată și va căuta de mai multe ori elementul cu id-ul dat (nu contează că id-ul este același - browserul va face totul acțiunile de mai multe ori), efectuând operațiuni inutile care pot încetini funcționarea browserului.
Dacă folosim variabila elem, nu are loc nicio căutare în pagină (elementul a fost deja găsit și referința la acesta se află în variabila elem).
Excepții: clasă și pentru atributeAți învățat deja cum să lucrați cu atribute prin JavaScript și acum este timpul să vă spun că nu este atât de simplu - atunci când lucrați cu atribute, există o excepție - acesta este atributul de clasă.
Acest cuvânt este special în JavaScript și, prin urmare, nu putem să scriem clasa elem pentru a citi valoarea atributului de clasă. În schimb, ar trebui să scrii elem.className.
Următorul exemplu afișează valoarea atributului de clasă:
funcția func() (var elem = document.getElementById("test"); alert(elem.className); )
Apropo, există și alte atribute care sunt numite diferit de proprietate. De exemplu, atributul for() are o proprietate corespunzătoare numită htmlFor .
Lucrând cu astaAcum vom lucra cu un obiect special this , care indică elementul curent (elementul în care a avut loc evenimentul). Mai mult, indică ca și cum acest element a fost deja primit de metoda getElementById.
Să vedem cum să lucrăm cu aceasta și care este confortul acestei abordări.
Să avem sarcina de a face clic pe intrare pentru a afișa conținutul valorii sale pe ecran.
Deocamdată, știi doar cum să faci așa ceva:
funcția func() (var elem = document.getElementById("test"); alert(elem.value); )
În principiu, această soluție este bună, dar acum imaginați-vă că avem multe intrări și făcând clic pe fiecare trebuie să-i afișăm valoarea.
În acest caz, vom obține ceva de genul acesta:
funcția func1() ( var elem = document.getElementById("test1"); alert(elem.value); ) funcția func2() ( var elem = document.getElementById("test2"); alert(elem.value); ) funcția func3() ( var elem = document.getElementById("test3"); alert(elem.value); )
Acum dezavantajul abordării noastre este clar vizibil - pentru fiecare intrare trebuie să ne creăm propria funcție de procesare a clicurilor, iar aceste funcții fac aproape același lucru.
Dacă avem 10 intrări, atunci va trebui să facem 10 funcții, ceea ce nu este convenabil.
Să ne simplificăm sarcina: vom trece id-ul elementului curent ca parametru funcției. Și în loc de un număr mare de funcții, totul va fi redus la o singură funcție:
funcția func(id) (var elem = document.getElementById(id); alert(elem.value); )
Cu toate acestea, această soluție are încă un dezavantaj - fiecare element va trebui să introducă un ID diferit, ceea ce este, de asemenea, oarecum incomod.
Deci, să luăm în sfârșit în considerare soluția problemei prin aceasta.
Să facem astfel încât fiecare intrare să-și afișeze conținutul la clic. Pentru a face acest lucru, treceți acest obiect ca parametru de funcție, astfel: func(this) .
Acest lucru este transmis ca parametru funcției și ajunge în variabila elem. Acest element se comportă ca și cum ar fi primit astfel: var elem = document.getElementById(...), dar nu trebuie să îl primiți în acest fel, totul este deja gata și îl puteți folosi. De exemplu, elem.value indică valoarea intrării noastre și așa mai departe.
Deci, iată cea mai simplă soluție la problema noastră:
funcția func(elem) ( alert(elem.value); )
Bazele CSSÎn JavaScript, lucrul cu proprietățile CSS se face prin schimbarea valorii atributului de stil pe un element. De exemplu, pentru a schimba culoarea, trebuie să construiți următorul lanț - elem.stil.culoare- și atribuiți-i valoarea de culoare dorită:
funcția func() ( var elem = document.getElementById ("test"); elem.style.color = "roșu"; )
De asemenea, este posibil să nu introduceți variabila elem, ci să construiți lanț foarte lung.
La deschiderea oricărui document HTML, browserul analizează mai întâi conținutul acestuia și, pe baza acestei analize, creează un model de obiect al documentului HTML, sau mai pe scurt DOM.
DOM-ul este format din obiecte imbricate ierarhic numite noduri. Fiecare nod din structură reprezintă un element HTML situat pe pagină.
Folosind DOM-ul puteți interacționa ( citiți, modificați, ștergeți) cu conținutul documentelor HTML din scripturi.
Mai jos este codul HTML al documentului și DOM-ul care ar fi creat de browser pe baza acestui cod:
HTML DOM HTML DOM.
Salutare tuturor.
Toate dreptunghiurile afișate în imagine sunt obiecte (sau noduri). Nodurile de diferite tipuri sunt marcate cu culori diferite în imagine.
Nodul Document este marcat cu roșu. Orice apel către DOM trebuie să înceapă cu un apel către acest nod.
Nodurile elementului sunt marcate cu verde. Pentru fiecare element HTML din pagină, browserul creează un nod de element corespunzător.
Conținutul elementelor este stocat în noduri de text. Nodurile de text sunt marcate cu albastru în diagrama noastră.
Este creat un nod de atribut pentru fiecare atribut de element HTML. Nodul de atribut este marcat cu roz în diagramă.
Rețineți că nu uitați că textul este întotdeauna stocat în noduri de text și nu este o proprietate a elementului. Acestea. pentru a accesa conținutul unui element HTML, trebuie să accesați proprietatea nodului text al acestuia.
Relațiile dintre noduriNodurile dintr-o structură de obiecte sunt legate între ele. Există mai mulți termeni speciali pentru a descrie relația dintre noduri:
nodul părinte ( nodul părinte) - nodul părinte în raport cu obiectul în cauză este nodul în care este imbricat obiectul în cauză. În diagrama noastră, cu privire la nodurile și
este părinte. Pentru un nod, nodul părinte este .
Noduri copil ( nod copil) - un nod descendent în raport cu obiectul considerat este un nod care este imbricat în obiectul considerat. În schema noastră, în raport cu nodul și
Ei sunt descendenți. Pentru un nod, copilul este .
Noduri frați ( nodul fratelui) - noduri care sunt la același nivel de imbricare în raport cu nodul lor părinte. În diagrama noastră, nodurile frați sunt și ,
Nodul cel mai de sus din DOM se numește rădăcină. În diagrama noastră, rădăcina este (deoarece obiectul document nu face parte din DOM).
În această lecție, ne vom uita la ce este DOM-ul, de ce este necesar și cum este construit.
Ce este DOM?Browserul, atunci când solicită o pagină și primește codul HTML sursă ca răspuns de la server, trebuie mai întâi să o analizeze. În procesul de parsare și parsare a codului HTML, browserul construiește un arbore DOM pe baza acestuia.
După efectuarea acestei acțiuni și a altora, browserul continuă să redeze pagina. În acest proces, el folosește, desigur, deja arborele DOM pe care l-a creat, nu HTML-ul original.
DOM este modelul de obiect de document pe care browserul îl creează în memoria computerului pe baza codului HTML pe care îl primește de la server.
Pentru a spune simplu, codul HTML este textul unei pagini, iar DOM este un set de obiecte asociate create de browser la analizarea textului acesteia.
În Chrome, codul sursă al paginii pe care o primește browserul poate fi vizualizat în fila „Sursă” din panoul „Instrumente pentru dezvoltatori web”.

În Chrome, nu există niciun instrument care să poată fi utilizat pentru a vizualiza arborele DOM pe care l-a creat. Dar există o reprezentare a acestui arbore DOM sub formă de cod HTML, este disponibil în fila „Elemente”. Această reprezentare DOM este, desigur, mult mai convenabilă pentru a lucra cu un dezvoltator web. Prin urmare, nu există niciun instrument care ar reprezenta DOM-ul sub forma unei structuri arborescente.

Obiectele din acest model sunt formate din aproape tot ceea ce este în HTML (etichete, conținut text, comentarii etc.), inclusiv documentul în sine. Relațiile dintre aceste obiecte din model se formează pe baza modului în care elementele HTML sunt situate unul față de celălalt în cod.
În acest caz, DOM-ul documentului după formarea acestuia poate fi modificat. Când DOM-ul se schimbă, browserul redesenează imaginea paginii aproape instantaneu. Drept urmare, redarea noastră a paginii este întotdeauna conformă cu DOM .
Pentru a citi și modifica DOM-ul în mod programatic, browser-ul ne pune la dispoziție un API DOM sau, cu alte cuvinte, o interfață de programare. În termeni simpli, API-ul DOM este o colecție de un număr mare de obiecte diferite, proprietățile și metodele lor pe care le putem folosi pentru a citi și modifica DOM.
Pentru a lucra cu DOM în cele mai multe cazuri, este folosit JavaScript, deoarece. până în prezent, este singurul limbaj de programare în care scripturile pot fi executate într-un browser.
De ce avem nevoie de un API DOM? Avem nevoie de el pentru a putea folosi JavaScript pentru a schimba pagina din mers, de exemplu. fă-l dinamic și interactiv.
API-ul DOM ne pune la dispoziție (dezvoltatorilor) un număr mare de metode prin care putem schimba totul din pagină, precum și interacționa cu utilizatorul. Acestea. această interfață de programare ne permite să creăm interfețe complexe, formulare, să procesăm acțiunile utilizatorului, să adăugăm și să eliminăm diverse elemente de pe pagină, să le modificăm conținutul, proprietățile (atributele) și multe altele.
Acum, pe web, practic nu există site-uri în scripturile cărora nu ar exista nicio lucrare cu DOM.
Care este codul HTML pentru o pagină?Înainte de a trece la studiul modelului obiect document, trebuie mai întâi să vă amintiți care este codul sursă al unei pagini web (document HTML).
Codul sursă al unei pagini web este format din etichete, atribute, comentarii și text. Etichetele sunt sintaxa de bază a HTML. Majoritatea sunt în perechi. În acest caz, unul dintre ele este cel de deschidere, iar celălalt este cel de închidere. O astfel de pereche de etichete formează un element HTML. Elementele HTML pot avea parametri suplimentari - atribute.
Într-un document pentru a crea un anumit marcaj, unele elemente sunt în interiorul altora. Ca rezultat, un document HTML poate fi gândit ca un set de elemente HTML imbricate.
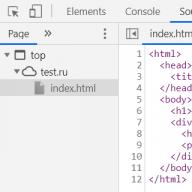
Ca exemplu, luați în considerare următorul cod HTML:
Titlul paginii Titlul articolului Secțiunea articolului
Conținutul articolului
În acest cod, elementul rădăcină este html . Capul și elementele corpului sunt imbricate în el. Elementul head conține titlul , în timp ce elementul body conține h1 și div . Elementul div la rândul său conține h2 și p .
Acum să ne uităm la modul în care browserul construiește un arbore DOM pe baza codului HTML.
Cum este construit arborele DOM al documentului?După cum este descris mai sus, browserul construiește un arbore bazat pe elemente HTML și alte entități din codul sursă al paginii. Atunci când se efectuează acest proces, se ia în considerare imbricarea elementelor unul în celălalt.
Drept urmare, browserul folosește arborele DOM rezultat nu numai în activitatea sa, ci ne oferă și un API pentru lucrul convenabil cu acesta prin JavaScript.
La construirea DOM-ului, browserul creează obiecte (noduri ale arborelui DOM) din elemente HTML, text, comentarii și alte entități ale acestui limbaj.
În cele mai multe cazuri, dezvoltatorii web sunt interesați doar de obiecte (noduri) formate din elemente HTML.
În același timp, browserul nu creează doar obiecte din elemente HTML, ci și le conectează între ele prin anumite conexiuni, în funcție de modul în care fiecare dintre ele se raportează la celălalt în cod.
Elementele care se află direct într-un element sunt copii ale acestuia. Și este un părinte pentru fiecare dintre ei. În plus, toate aceste elemente în relație între ele sunt frați (frați).
Mai mult, în HTML, orice element are întotdeauna un părinte (elementul HTML în care se află direct). În HTML, un element nu poate avea mai mulți părinți. Singura excepție este elementul html. Nu are părinte.
Pentru a obține arborele DOM pe măsură ce browserul îl construiește, trebuie doar să „aranjați” toate elementele în funcție de relația lor între ele.
Crearea arborelui DOM se face de sus în jos.
Rădăcina arborelui DOM este întotdeauna documentul însuși (nodul documentului). În plus, arborele este construit în funcție de structura codului HTML.
De exemplu, codul HTML la care ne-am uitat mai sus ar avea următorul arbore DOM:

În partea de sus a acestui arbore se află nodul document. Acest nod este asociat cu html, este copilul său. Nodul html este format din elementul html(...). Nodurile cap (...) și body (...) au o relație de părinte cu html. În relație unul cu celălalt, sunt frați, pentru că ai un singur parinte. Nodul principal este legat de titlu (lt;titlu>...) și este copilul său. Nodurile h1 și div sunt legate de body , pentru ei este părintele. Nodul div este legat de h2(...) și p(), ele sunt copiii acestuia.
Arborele începe, după cum sa menționat mai sus, de la documentul obiect (nod). La rândul său, are un nod copil format din elementul html (...). Elementele cap(...) și corp(...) sunt în html și, prin urmare, sunt copiii săi. În continuare, nodul principal este părintele titlului (lt;titlu>...). Elementele h1 și div sunt imbricate în interiorul corpului, ceea ce înseamnă că sunt copiii acestuia. Div-ul conține direct elementele h2(...) și p(). Aceasta înseamnă că nodul div pentru fiecare dintre ele este părintele.
Acesta este modul în care arborele DOM este pur și simplu construit în browser pe baza codului HTML.
De ce trebuie să știți cum este construit un arbore DOM? În primul rând, este o înțelegere a mediului în care doriți să schimbați ceva. În al doilea rând, majoritatea acțiunilor când se lucrează cu DOM se rezumă la găsirea (selectarea) elementelor necesare. Fără a ști cum este aranjat arborele DOM și conexiunile dintre noduri, va fi destul de dificil să găsești un element specific în el.
ExercițiuPe baza arborelui DOM prezentat în figură, creați codul HTML.

Document Object Model, sau „DOM”, este o interfață de programare pentru accesarea elementelor paginilor web. Practic, este o pagină API care vă permite să citiți și să manipulați conținutul, structura și stilurile paginii. Să vedem cum funcționează și cum funcționează.
Cum este construită o pagină web?Procesul de conversie a unui document HTML sursă într-o pagină redabilă, stilizată și interactivă se numește „Calea de redare critică”. Deși acest proces poate fi împărțit în mai mulți pași, așa cum am descris în Înțelegerea căii critice de redare, acești pași pot fi grupați aproximativ în doi pași. În primul, browserul analizează documentul pentru a determina ce va fi afișat în cele din urmă pe pagină, iar în al doilea, browserul face randarea.
Rezultatul primei etape este ceea ce se numește „arborele de randare”. Arborele de randare este o reprezentare a elementelor HTML care vor fi redate pe pagină și a stilurilor asociate acestora. Pentru a construi acest arbore, browserul are nevoie de două lucruri:
DOM este o reprezentare obiect a documentului HTML original. Are unele diferențe, așa cum vom vedea mai jos, dar în esență este o încercare de a transforma structura și conținutul unui document HTML într-un model obiect care poate fi folosit de diverse programe.
Structura obiectelor DOM este reprezentată de ceea ce se numește „arborele de noduri”. Este numit astfel pentru că poate fi gândit ca un copac cu un singur părinte care se ramifică în mai multe ramuri copil, fiecare dintre ele putând avea frunze. În acest caz, „elementul” părinte este elementul rădăcină, „ramurile” secundare sunt elemente imbricate, iar „frunzele” sunt conținutul din elemente.
Să luăm ca exemplu acest document HTML:
Prima mea pagină web Salut, lume!
Ce mai faci?
Acest document poate fi reprezentat ca următorul arbore de noduri:
- html
- cap
- titlu
- Prima mea pagină web
- titlu
- corp
- h1
- Salut Lume!
- p
- Ce mai faci?
- h1
- cap
În exemplul de mai sus, se pare că DOM-ul este o mapare 1:1 a documentului HTML original. Totuși, așa cum am spus, există diferențe. Pentru a înțelege pe deplin ce este DOM, trebuie să ne uităm la ce nu este.
DOM nu este o copie a codului HTML originalDeși DOM-ul este creat dintr-un document HTML, nu este întotdeauna exact același. Există două cazuri în care DOM-ul poate diferi de HTML-ul original.
1. Când HTML conține erori de marcareDOM-ul este o interfață pentru accesarea elementelor reale (adică, deja redate) ale unui document HTML. În procesul de creare a DOM, browserul însuși poate remedia unele erori în codul HTML.
Luați în considerare acest document HTML ca exemplu:
Salut Lume!
Documentului lipsesc și elemente, ceea ce este o cerință pentru HTML. Dar dacă ne uităm la arborele DOM rezultat, putem vedea că acest lucru a fost remediat:
- html
- cap
- corp
- Salut Lume!
Pe lângă faptul că este interfața pentru vizualizarea conținutului unui document HTML, DOM-ul în sine poate fi modificat.
Putem, de exemplu, să creăm noduri suplimentare pentru DOM folosind Javascript.
Var newParagraph = document.createElement("p"); var paragraphContent = document.createTextNode("Sunt nou!"); newParagraph.appendChild(paragraphContent); document.body.appendChild(newParagraph);
Acest cod va schimba DOM, dar modificările nu vor fi reflectate în documentul HTML.
DOM-ul nu este ceea ce vedeți în browser (adică arborele de randare)În fereastra de vizualizare a browserului, vedeți arborele de randare, care, așa cum am spus, este o combinație de DOM și CSSOM. Ceea ce face DOM diferit de un arbore de randare este faptul că acesta din urmă constă doar din ceea ce va fi redat în cele din urmă pe ecran.
Deoarece arborele de randare este preocupat doar de ceea ce este afișat, exclude elementele care sunt ascunse vizual. De exemplu, elemente care au stiluri cu afișare: none .
Salut Lume!
DOM va include elementul
- html
- cap
- corp
- h1
- Salut Lume!
- p
- Ce mai faci?
- h1
Cu toate acestea, arborele de randare și, prin urmare, ceea ce este vizibil în fereastra de vizualizare, nu va fi inclus în acest element.
- html
- corp
- h1
- Salut Lume!
- h1
- corp
Această diferență este puțin mai mică, deoarece DevTools Element Inspector oferă cea mai apropiată aproximare a DOM-ului pe care îl avem într-un browser. Cu toate acestea, inspectorul DevTools conține informații suplimentare care nu se află în DOM.
Cel mai bun exemplu în acest sens sunt pseudo-elementele CSS. Pseudo-elementele create folosind selectoarele ::before și ::after fac parte din CSSOM și din arborele de randare, dar nu fac parte din punct de vedere tehnic din DOM. Acest lucru se datorează faptului că DOM-ul este generat numai din documentul HTML original, fără a include stilurile aplicate elementului.
Chiar dacă pseudo-elementele nu fac parte din DOM, ele se află în inspectorul nostru de elemente devtools.
 rezumat
rezumat DOM este o interfață pentru un document HTML. Este folosit de browsere ca prim pas în a determina ce să randeze în fereastra de vizualizare și de codul Javascript pentru a schimba conținutul, structura sau stilul unei pagini.
Lucrul cu modelul DOM
Fiecare obiect Window are o proprietate document care se referă la un obiect Document. Acest obiect Document nu este un obiect independent. Este obiectul central al unui API bogat cunoscut sub numele de Document Object Model (DOM), care definește modul în care este accesat conținutul unui document.
Prezentare generală a DOMDocument Object Model (DOM) este o interfață fundamentală de programare a aplicațiilor care oferă capacitatea de a lucra cu conținutul documentelor HTML și XML. Interfața de programare a aplicațiilor (API) DOM nu este deosebit de complexă, dar există multe caracteristici arhitecturale de care ar trebui să fii conștient.
În primul rând, trebuie înțeles că elementele imbricate ale documentelor HTML sau XML sunt reprezentate ca un arbore de obiecte DOM. Vizualizarea arborescentă a unui document HTML conține noduri reprezentând elemente sau etichete precum și
Și noduri reprezentând linii de text. Un document HTML poate conține și noduri reprezentând comentarii HTML. Luați în considerare următorul document HTML simplu:
Exemplu de document Acesta este un document HTML
Exemplu simplu text.
Reprezentarea DOM a acestui document este prezentată în următoarea diagramă:
Pentru cei care nu sunt încă familiarizați cu structurile arborescente în programarea computerelor, este util să știe că terminologia pentru a le descrie a fost împrumutată din arborii genealogic. Este apelat nodul imediat deasupra nodului dat părintească cu privire la acest nod. Nodurile care sunt la un nivel sub alt nod sunt filiale cu privire la acest nod. Sunt numite noduri care sunt la același nivel și au același părinte surori. Nodurile situate orice număr de niveluri sub alt nod sunt copiii acestuia. Părinte, bunicul și orice alte noduri de deasupra acestui nod sunt strămoșii săi.
Fiecare dreptunghi din această diagramă este un nod de document, care este reprezentat de un obiect Node. Rețineți că figura prezintă trei tipuri diferite de noduri. Rădăcina arborelui este nodul Document, care reprezintă întregul document. Nodurile care reprezintă elemente HTML sunt noduri de tip Element, iar nodurile care reprezintă text sunt noduri de tip Text. Document, Element și Text sunt subclase ale clasei Node. Document și Element sunt cele mai importante două clase din DOM.
Tipul de nod și subtipurile sale formează ierarhia tipurilor prezentată în diagrama de mai jos. Rețineți diferențele formale dintre tipurile generice Document și Element și tipurile HTMLDocument și HTMLElement. Tipul Document reprezintă un document HTML și XML, iar clasa Element reprezintă un element al documentului respectiv. Subclasele HTMLDocument și HTMLElement reprezintă în mod specific un document HTML și elementele acestuia:

De remarcat în această diagramă este și numărul mare de subtipuri ale clasei HTMLElement care reprezintă tipuri specifice de elemente HTML. Fiecare dintre acestea definește proprietăți JavaScript care reflectă atributele HTML ale unui anumit element sau grup de elemente. Unele dintre aceste clase specifice definesc proprietăți sau metode suplimentare care nu reflectă sintaxa limbajului de marcare HTML.
Selectarea elementelor documentuluiLucrarea majorității programelor client JavaScript este oarecum legată de manipularea elementelor documentului. În timpul execuției, aceste programe pot folosi variabila globală document, care se referă la obiectul Document. Totuși, pentru a efectua orice manipulare asupra elementelor documentului, programul trebuie să obțină cumva, sau să selecteze, obiectele Element care se referă la acele elemente ale documentului. DOM definește mai multe moduri de selectare a elementelor. Puteți selecta un element sau elemente ale unui document:
prin valoarea atributului id;
prin valoarea atributului nume;
după numele etichetei;
după numele clasei sau claselor CSS;
pentru a se potrivi cu un anumit selector CSS.
Toate aceste tehnici de selecție a elementelor sunt descrise în următoarele subsecțiuni.
Selectarea elementelor după valoarea atributului idToate elementele HTML au atribute id. Valoarea acestui atribut trebuie să fie unică în document - niciun element din același document nu trebuie să aibă aceeași valoare a atributului id. Puteți selecta un element după valoarea sa unică a atributului id folosind metoda getElementById() a obiectului Document:
Var section1 = document.getElementById("section1");
Acesta este cel mai simplu și mai comun mod de a selecta elemente. Dacă scriptul trebuie să poată manipula un anumit set de elemente ale documentului, atribuiți valori atributelor id ale acelor elemente și utilizați capacitatea de a le căuta după acele valori.
În versiunile de Internet Explorer anterioare IE8, metoda getElementById() caută valorile atributelor id fără a ține seama de majuscule și minuscule și returnează, de asemenea, elemente care se potrivesc cu valoarea atributului nume.
Selectarea elementelor după valoarea atributului numeAtributul nume HTML a fost inițial destinat pentru denumirea elementelor de formular, iar valoarea acestui atribut a fost folosită atunci când datele formularului au fost trimise la server. La fel ca atributul id, atributul name atribuie un nume unui element. Cu toate acestea, spre deosebire de id, valoarea atributului name nu trebuie să fie unică: mai multe elemente pot avea același nume simultan, ceea ce este destul de comun atunci când este utilizat în butoanele radio și formularele de casete de selectare. De asemenea, spre deosebire de id, atributul name este permis numai pe anumite elemente HTML, inclusiv formulare, elemente de formular și elemente și .
Puteți selecta elemente HTML pe baza valorilor atributelor lor de nume folosind metoda getElementsByName() a obiectului Document:
Var radiobuttons = document.getElementsByName("culoare_favorită");
Metoda getElementsByName() nu este definită de clasa Document, ci de clasa HTMLDocument, deci este disponibilă numai în documentele HTML și nu este disponibilă în documentele XML. Returnează un obiect NodeList care se comportă ca o matrice numai în citire de obiecte Element.
În IE, metoda getElementsByName() returnează, de asemenea, elemente ale căror valori ale atributului id se potrivesc cu valoarea specificată. Pentru a asigura compatibilitatea între browsere, trebuie avut grijă în alegerea valorilor atributelor și să nu folosiți aceleași șiruri pentru valorile atributelor nume și id.
Selectarea elementelor după tipMetoda getElementsByTagName() a obiectului Document vă permite să selectați toate elementele HTML sau XML de tipul specificat (sau după numele etichetei). De exemplu, pentru a obține un obiect asemănător matricei numai pentru citire care conține obiectele Element ale tuturor elementelor din document, puteți face următoarele:
var spans = document.getElementsByTagName("span");
La fel ca metoda getElementsByName(), getElementsByTagName() returnează un obiect NodeList. Elementele documentului sunt incluse în tabloul NodeList în aceeași ordine în care apar în document, adică. primul element
Într-un document, puteți alege:
Var firstParagraph = document.getElementsByTagName("p");
Numele etichetelor HTML nu țin cont de majuscule și minuscule, iar când getElementsByTagName() este aplicat unui document HTML, se compară cu numele etichetei fără a ține seama de majuscule și minuscule. Variabila spans creată mai sus, de exemplu, va include și toate elementele care sunt scrise ca .
Puteți obține un NodeList care conține toate elementele dintr-un document prin trecerea wildcardului „*” la metoda getElementsByTagName().
În plus, clasa Element definește și metoda getElementsByTagName(). Acționează exact ca versiunea metodei din clasa Document, dar selectează doar elementele care sunt copii ale elementului pe care este apelată metoda. Adică, găsiți toate elementele din interiorul primului element
Este posibil astfel:
Var firstParagraph = document.getElementsByTagName("p"); var firstParagraphSpans = firstParagraph.getElementsByTagName("span");
Din motive istorice, clasa HTMLDocument definește proprietăți speciale pentru accesarea anumitor tipuri de noduri. Proprietăți imagini, formeȘi link-uri, de exemplu, se referă la obiecte care se comportă ca matrice numai pentru citire care conțin elemente , Și (dar numai acele etichete , care au un atribut href). Aceste proprietăți se referă la obiecte HTMLCollection, care seamănă mult cu obiectele NodeList, dar pot fi indexate în plus după valorile atributelor id și name.
Obiectul HTMLDocument definește, de asemenea, proprietățile sinonime de încorporare și pluginuri, care sunt colecții de elemente HTMLCollection. Proprietatea ancore nu este standard, dar poate fi folosită pentru a accesa elemente A care are un atribut nume, dar nu un atribut href. Proprietatea scripts este definită de standardul HTML5 și este o colecție de elemente HTMLCollection.
În plus, obiectul HTMLDocument definește două proprietăți, fiecare dintre acestea nu se referă la o colecție, ci la un singur element. Proprietatea document.body reprezintă un element de document HTML, iar proprietatea document.head reprezintă . Aceste proprietăți sunt întotdeauna definite în document: chiar dacă nu există elemente și în documentul original, browserul le va crea implicit. Proprietatea documentElement a obiectului Document se referă la elementul rădăcină al documentului. În documentele HTML, acesta reprezintă întotdeauna .
Selectarea elementelor după clasa CSSValoarea atributului clasei HTML este o listă de zero sau mai mulți identificatori separați prin spații. Face posibilă definirea unor seturi de elemente de document înrudite: orice elemente care au același identificator în atributul de clasă fac parte din același set. Clasa de cuvinte este rezervată în JavaScript, astfel încât JavaScript la nivel de client utilizează proprietatea className pentru a stoca valoarea atributului de clasă HTML.
De obicei, atributul de clasă este utilizat împreună cu foile de stil în cascadă CSS pentru a aplica un stil de afișare comun tuturor membrilor unui set. Totuși, în plus, standardul HTML5 definește metoda getElementsByClassName(), care vă permite să selectați seturi de elemente de document pe baza identificatorilor din atributele clasei lor.
La fel ca metoda getElementsByTagName(), metoda getElementsByClassName() poate fi apelată atât pe documente HTML, cât și pe elemente HTML și returnează un obiect NodeList „în direct” care conține toți descendenții documentelor sau elementelor care corespund criteriilor de căutare.
Metoda getElementsByClassName() acceptă un singur argument șir, dar șirul în sine poate conține mai mulți identificatori separați prin spații. Toate elementele ale căror atribute de clasă conțin toți identificatorii specificați vor fi considerate potrivite. Ordinea identificatorilor nu contează. Rețineți că atât în atributul de clasă, cât și în argumentul metodei getElementsByClassName(), identificatorii de clasă sunt separați prin spații, nu prin virgule.
Următoarele sunt câteva exemple de utilizare a metodei getElementsByClassName():
// Găsiți toate elementele cu clasa "warning" var warnings = document.getElementsByClassName("warning"); // Găsiți toți descendenții elementului cu id "log" // cu clasele "error" și "fatal" var log = document.getElementById("log"); var fatal = log.getElementsByClassName(„eroare fatală”);
Selectarea elementelor folosind selectoare CSSFoile de stil în cascadă CSS au constructe sintactice foarte puternice cunoscute sub numele de selectoare care vă permit să descrieți elemente sau seturi de elemente dintr-un document. Alături de standardizarea selectoarelor CSS3, un alt standard W3C cunoscut sub numele de Selectors API definește metode JavaScript pentru obținerea elementelor care se potrivesc cu un anumit selector.
Cheia acestui API este metoda querySelectorAll() a obiectului Document. Este nevoie de un singur argument șir cu un selector CSS și returnează un obiect NodeList reprezentând toate elementele din document care se potrivesc cu selectorul.
În plus față de metoda querySelectorAll(), obiectul document definește și o metodă querySelector() similară cu metoda querySelectorAll(), cu excepția faptului că returnează doar primul element care se potrivește (în ordinea documentului), sau null dacă nu există elemente care se potrivesc .
Aceste două metode sunt definite și de clasa Elements. Când sunt apelați pe un element, întregul document este căutat pentru o potrivire cu selectorul dat, iar apoi rezultatul este filtrat astfel încât să rămână doar descendenții elementului utilizat. Această abordare poate părea contraintuitivă, deoarece înseamnă că șirul selector poate include strămoșii elementului care se potrivește.
Structura documentului și navigarea documentelorDupă selectarea unui element de document, uneori este necesar să găsiți părți ale documentului legate structural (părinte, frați, element copil). Obiectul Document poate fi gândit ca un arbore de obiecte Node. Tipul Nod definește proprietăți care vă permit să navigați printr-un astfel de arbore. Există o altă interfață de aplicație pentru navigarea prin document, ca un arbore de obiecte Element.
Documentele ca arbori de noduriObiectul Document, obiectele sale Element și obiectele Text care reprezintă fragmentele de text din document sunt toate obiecte Node. Clasa Node definește următoarele proprietăți importante:
parentNodeNodul părinte al acestui nod sau nul pentru nodurile care nu au părinte, cum ar fi Document.
childNodesUn obiect asemănător matricei care poate fi citit (NodeList) care oferă o reprezentare a nodurilor copil.
primulCopil, ultimulCopilPrimul și ultimul nod copil sau nul dacă nodul dat nu are copii.
următorul Frate, precedentul FrateNodurile frați următoare și anterioare. Nodurile Brother sunt două noduri care au același părinte. Ordinea lor corespunde cu ordinea din document. Aceste proprietăți leagă nodurile într-o listă dublu legată.
nodeTypeTipul acestui nod. Nodurile de tip Document au valoarea 9 în această proprietate. Noduri de tip Element - valoare 1. Noduri de text de tip Text - valoare 3. Noduri de tip Comentarii - valoare 8 și noduri de tip DocumentFragment - valoare 11.
nodeValueConținutul text al nodurilor Text și Comentariu.
nodeNameNumele etichetei unui element în care toate caracterele sunt convertite în majuscule.
Cu aceste proprietăți ale clasei Node, vă puteți referi la al doilea nod copil al primului nod copil al obiectului Document, așa cum se arată mai jos:
Document.childNodes.childNodes == document.firstChild.firstChild.nextSibling
Să presupunem că documentul în cauză arată astfel:
Testează Hello World!
Apoi al doilea nod copil al primului nod copil va fi elementul . Conține valoarea 1 în proprietatea nodeType și valoarea „BODY” în proprietatea nodeName.
Cu toate acestea, rețineți că acest API este extrem de sensibil la modificările din textul documentului. De exemplu, dacă adăugați o singură linie nouă între etichetele și în acest document, acel caracter de linie nouă va deveni primul nod copil (nodul Text) al primului nod copil, iar al doilea nod copil va fi elementul, nu .
Documentele ca arbori de elementeCând elementele documentului în sine sunt de interes principal, mai degrabă decât textul din ele (și spațiul alb dintre ele), este mult mai convenabil să utilizați un API care vă permite să interpretați documentul ca un arbore de obiecte Element, ignorând textul. și noduri de comentariu care fac, de asemenea, parte din document.
Prima parte a acestui API este proprietatea copiilor a obiectelor Element. La fel ca proprietatea childNodes, valoarea sa este un obiect NodeList. Totuși, spre deosebire de proprietatea childNodes, lista de copii conține doar obiecte Element.
Rețineți că nodurile Text și Comment nu au noduri copil. Aceasta înseamnă că proprietatea Node.parentNode descrisă mai sus nu returnează niciodată noduri Text sau Comment. Valoarea proprietății parentNode a oricărui obiect Element va fi întotdeauna un alt obiect Element sau rădăcina arborelui, un obiect Document sau DocumentFragment.
A doua parte a API-ului de navigare a elementelor de document este proprietățile obiectului Element, similare cu proprietățile de accesare a nodurilor copil și frate ale obiectului Node:
firstElementChild, lastElementChildSimilar cu proprietățile firstChild și lastChild, dar returnează elemente copil.
nextElementSibling, previousElementSiblingSimilar cu proprietățile nextSibling și previousSibling, dar returnează elemente frate.
childElementCountNumărul de elemente copil. Returnează aceeași valoare ca proprietatea children.length.
Aceste proprietăți de acces pentru copii și frați sunt standardizate și implementate în toate browserele actuale, cu excepția IE.