1) ინდექსის ცნება
ინდექსიარის ინსტრუმენტი, რომელიც უზრუნველყოფს ცხრილის რიგების სწრაფ წვდომას ერთი ან მეტი სვეტის მნიშვნელობების საფუძველზე.
ამ ოპერატორში ბევრი მრავალფეროვნებაა, რადგან ის არ არის სტანდარტიზებული, რადგან სტანდარტები არ ეხება შესრულების საკითხებს.
2) ინდექსების შექმნა
ინდექსის შექმნა
ჩართული ()
3) ინდექსების შეცვლა და წაშლა
ინდექსის აქტივობის გასაკონტროლებლად ოპერატორი გამოიყენება:
ALTER ინდექსი
ინდექსის მოსაშორებლად გამოიყენეთ ოპერატორი:
ვარდნის ინდექსი
ა) ცხრილის შერჩევის წესები
1. მიზანშეწონილია ცხრილების ინდექსირება, რომლებშიც არჩეულია სტრიქონების 5%-ზე მეტი.
2. ცხრილები, რომლებსაც არ აქვთ დუბლიკატები SELECT განცხადების WHERE პუნქტში, უნდა იყოს ინდექსირებული.
3. ხშირად განახლებული ცხრილების ინდექსირება არ არის პრაქტიკული.
4. შეუსაბამოა ცხრილების ინდექსირება, რომლებიც იკავებს არაუმეტეს 2 გვერდს (Oracle-სთვის ეს არის 300 მწკრივზე ნაკლები), რადგან მის სრულ სკანირებას მეტი დრო არ სჭირდება.
ბ) სვეტის შერჩევის წესები
1. ძირითადი და უცხოური გასაღებები - ხშირად გამოიყენება ცხრილების შესაერთებლად, მონაცემების მისაღებად და ძიებისთვის. ეს ყოველთვის უნიკალური ინდექსებია მაქსიმალური სარგებლიანობით
2. რეფერენციული მთლიანობის ვარიანტების გამოყენებისას ყოველთვის გჭირდებათ ინდექსი FK-ზე.
3. სვეტები, რომლებითაც ხშირად ხდება მონაცემების დახარისხება და/ან დაჯგუფება.
4. სვეტები, რომლებიც ხშირად იძებნება SELECT განცხადების WHERE პუნქტში.
5. თქვენ არ უნდა შექმნათ ინდექსები გრძელ აღწერილ სვეტებზე.
გ) კომპოზიტური ინდექსების შექმნის პრინციპები
1. კომპოზიტური ინდექსები კარგია, თუ ცალკეულ სვეტებს აქვთ რამდენიმე უნიკალური მნიშვნელობები, მაგრამ კომპოზიციური ინდექსი უზრუნველყოფს მეტ უნიკალურობას.
2. თუ SELECT განაცხადის მიერ არჩეული ყველა მნიშვნელობა ეკუთვნის კომპოზიტურ ინდექსს, მაშინ მნიშვნელობები შეირჩევა ინდექსიდან.
3. რთული ინდექსი უნდა შეიქმნას, თუ WHERE პუნქტი იყენებს ორ ან მეტ მნიშვნელობას AND ოპერატორთან ერთად.
დ) არ არის რეკომენდებული შექმნა
არ არის რეკომენდირებული, რომ შექმნათ ინდექსები სვეტებზე, მათ შორის კომპოზიტურებზე, რომლებიც:
1. იშვიათად გამოიყენება მოთხოვნის შედეგების ძიების, გაერთიანებისა და დახარისხებისთვის.
2. შეიცავდეს ხშირად ცვალებად მნიშვნელობებს, რაც მოითხოვს ინდექსის ხშირ განახლებას, რაც ანელებს მონაცემთა ბაზის მუშაობას.
3. შეიცავდეს უნიკალური მნიშვნელობების მცირე რაოდენობას (10% მ/ფ-ზე ნაკლები) ან ხაზების დომინანტური რაოდენობა ერთი ან ორი მნიშვნელობით (მიმწოდებლის საცხოვრებელი ქალაქი მოსკოვია).
4. ფუნქციები ან გამოხატულება გამოიყენება მათზე WHERE პუნქტში და ინდექსი არ მუშაობს.
ე) არ უნდა დავივიწყოთ
თქვენ უნდა შეეცადოთ შეამციროთ ინდექსების რაოდენობა, რადგან ინდექსების დიდი რაოდენობა ამცირებს მონაცემთა განახლების სიჩქარეს. ამრიგად, MS SQL Server გირჩევთ შექმნათ არაუმეტეს 16 ინდექსი თითო ცხრილში.
როგორც წესი, ინდექსები იქმნება შეკითხვის მიზნებისთვის და რეფერენტული მთლიანობის შესანარჩუნებლად.
თუ ინდექსი არ გამოიყენება შეკითხვებისთვის, მაშინ ის უნდა წაიშალოს და უზრუნველყოფილი იყოს რეფერენციული მთლიანობა ტრიგერების გამოყენებით.
Oracle DBMS ცხრილის სტრიქონებზე სწრაფი წვდომის უზრუნველსაყოფად გამოიყენება ინდექსები. ინდექსები უზრუნველყოფს სწრაფ წვდომას მონაცემებზე ოპერაციების დროს, რომლებიც ირჩევენ ცხრილის რიგების შედარებით მცირე რაოდენობას.
მიუხედავად იმისა, რომ Oracle იძლევა შეუზღუდავი რაოდენობის ინდექსებს მაგიდაზე, ინდექსები გამოსადეგია მხოლოდ მაშინ, როდესაც ისინი გამოიყენება მოთხოვნების დასაჩქარებლად. წინააღმდეგ შემთხვევაში, ისინი მხოლოდ ადგილს იკავებენ და ამცირებენ სერვერის მუშაობას ინდექსირებული სვეტების განახლებისას. თქვენ უნდა გამოიყენოთ EXPLAIN PLAN (შესრულებისა და სტატისტიკის გეგმა) ფუნქცია, რათა დადგინდეს, თუ როგორ გამოიყენება ინდექსები თქვენს შეკითხვებში. ზოგჯერ, თუ ინდექსი ნაგულისხმევად არ გამოიყენება, შეგიძლიათ გამოიყენოთ შეკითხვის მინიშნებები ინდექსის გამოსაყენებლად.
შექმენით ინდექსები ცხრილის მონაცემების ჩასმის შემდეგ
როგორც წესი, ინდექსების შექმნამდე ჩასვით ან ჩატვირთავთ მონაცემებს ცხრილში. წინააღმდეგ შემთხვევაში, ინდექსების განახლების ხარჯი შეანელებს ჩასმის ან ჩატვირთვის ოპერაციებს. ამ წესის ერთადერთი გამონაკლისი არის ინდექსი კლასტერზე. მისი შექმნა შესაძლებელია მხოლოდ ცარიელი კლასტერისთვის.
გადართეთ დროებით მაგიდაზე, რათა თავიდან აიცილოთ თავისუფალი სივრცის პრობლემები ინდექსების შექმნისას
მაგიდაზე ინდექსის შექმნისას, რომელიც უკვე შეიცავს მონაცემებს, Oracle საჭიროებს დამატებით მეხსიერებას დახარისხებისთვის. ეს იყენებს ინდექსის შემქმნელისთვის გამოყოფილ დახარისხების მეხსიერების არეალს (თითოეული მომხმარებლისთვის გამოყოფილი თანხა დგინდება ინიციალიზაციის პარამეტრით SORT_AREA_SIZE), გარდა ამისა, Oracle სერვერმა უნდა გაასუფთავოს და შეცვალოს ინფორმაცია ინდექსის შექმნისას გამოყოფილი დროებითი სეგმენტებიდან. თუ ინდექსი ძალიან დიდია, რეკომენდებულია შემდეგი:
- შექმენით ახალი დროებითი ცხრილის სივრცე CREATE TABLESPACE განაცხადის გამოყენებით.
- მიუთითეთ ეს ახალი დროებითი სივრცე ALTER USER განაცხადის TEMPORARY TABLESPACE პარამეტრში.
- შექმენით ინდექსი CREATE INDEX განაცხადით.
- ჩამოაგდეთ ეს ცხრილი DROP TABLESPACE ბრძანებით. შემდეგ გამოიყენეთ ALTER USER განაცხადი, რათა აღადგინოთ თავდაპირველი მაგიდა, როგორც დროებითი.
აირჩიეთ სწორი ცხრილები და სვეტები ინდექსაციისთვის
გამოიყენეთ შემდეგი სახელმძღვანელო მითითებები იმის დასადგენად, თუ როდის უნდა შექმნათ ინდექსი.
- შექმენით ინდექსი, თუ ხშირად იღებთ სტრიქონების შედარებით მცირე რაოდენობას (15%-ზე ნაკლები) დიდი ცხრილიდან. ეს პროცენტი დიდად არის დამოკიდებული ცხრილის სკანირების შედარებით სიჩქარეზე და იმაზე, თუ რამდენად დაჯგუფებულია მწკრივის მონაცემები ინდექსის კლავიშში. რაც უფრო მაღალია დათვალიერების სიჩქარე, მით უფრო დაბალია პროცენტი; რაც უფრო ჯგუფურია მწკრივის მონაცემები, მით უფრო მაღალია პროცენტი.
- ინდექსის სვეტები, რომლებიც გამოიყენება შეერთებებში მრავალი ცხრილის შეერთების შესრულების გასაუმჯობესებლად.
- ინდექსები იქმნება ავტომატურად ძირითადი და უნიკალური გასაღებების საფუძველზე.
- მცირე ცხრილებს არ სჭირდებათ ინდექსირება. თუ შეამჩნევთ, რომ შეკითხვის შესრულების დრო მნიშვნელოვნად გაიზარდა, მაშინ, სავარაუდოდ, ის დიდი გახდა.
- სვეტის მნიშვნელობები შედარებით უნიკალურია;
- მნიშვნელობების დიდი დიაპაზონი (გამოდგება რეგულარული ინდექსებისთვის);
- მნიშვნელობების მცირე დიაპაზონი (შესაფერისი ბიტი ინდექსებისთვის);
- ძალიან მწირი სვეტები (ბევრი განუსაზღვრელი, „ცარიელი“ მნიშვნელობები), მაგრამ მოთხოვნები ძირითადად მნიშვნელოვან რიგებს ეხება. ამ შემთხვევაში, სასურველია შედარება, რომელიც ემთხვევა ყველა არანულის მნიშვნელობას:
WHERE COL_X > -9.99 * სიმძლავრე(10, 125) ვიდრე
WHERE COL_X არ არის NULL ეს იმიტომ ხდება, რომ პირველი შემთხვევა იყენებს COL_X ინდექსს (ვივარაუდოთ, რომ COL_X სვეტი არის რიცხვითი ტიპი).
შეზღუდეთ ინდექსების რაოდენობა ცხრილში
რაც მეტი ინდექსია, მით მეტია ზედნადები ცხრილის შეცვლისას. როდესაც სტრიქონები ემატება ან წაიშლება, ცხრილის ყველა ინდექსი განახლდება. როდესაც სვეტი განახლდება, ყველა ინდექსი, რომელშიც ის მონაწილეობს, ასევე უნდა განახლდეს.
ინდექსების შემთხვევაში, თქვენ უნდა აწონ-დაწონოთ მოთხოვნების შესრულების მიღწევები განახლებების შესრულების ჯარიმებთან მიმართებაში. მაგალითად, თუ ცხრილი ძირითადად მხოლოდ წაკითხვადია, შეგიძლიათ ფართოდ გამოიყენოთ ინდექსები; მაგრამ თუ ცხრილი ხშირად განახლდება, მიზანშეწონილია მინიმუმამდე დაიყვანოთ ინდექსების გამოყენება.
შეარჩიეთ სვეტების თანმიმდევრობა შედგენილ ინდექსებში
მიუხედავად იმისა, რომ სვეტები შეიძლება მითითებული იყოს ნებისმიერი თანმიმდევრობით CREATE INDEX განცხადებაში, CREATE INDEX განცხადებაში სვეტების თანმიმდევრობამ შეიძლება გავლენა მოახდინოს შეკითხვის შესრულებაზე. ზოგადად, სვეტები, რომლებიც ყველაზე ხშირად იქნება გამოყენებული, პირველ რიგში არის ჩამოთვლილი ინდექსში. თქვენ შეგიძლიათ შექმნათ რთული ინდექსი (მრავალი სვეტის გამოყენებით), რომელიც შეიძლება გამოყენებულ იქნას ინდექსში შემავალი ყველა ან ზოგიერთი სვეტის დასადგენად.
შეაგროვეთ სტატისტიკა ინდექსების სწორად გამოყენებისთვის
ინდექსები შეიძლება გამოყენებულ იქნას უფრო ეფექტურად, თუ მონაცემთა ბაზა აგროვებს და ინახავს სტატისტიკას შეკითხვებში გამოყენებული ცხრილების შესახებ. შეგიძლიათ შეაგროვოთ სტატისტიკა ინდექსის შექმნისას COMPUTE STATISTICS საკვანძო სიტყვის მითითებით CREATE INDEX განცხადებაში. იმის გამო, რომ მონაცემები მუდმივად განახლდება და მნიშვნელობების განაწილება იცვლება, სტატისტიკა პერიოდულად უნდა განახლდეს DBMS_STATS.GATHER_TABLE_STATISTICS და DBMS_STATS.GATHER_SCHEMA_STATISTICS პროცედურების გამოყენებით.
გაანადგურეთ არასაჭირო ინდექსები
ინდექსი იშლება შემდეგ შემთხვევებში:
- თუ ინდექსის გამოყენება არ აუმჯობესებს შეკითხვის შესრულებას. ეს სიტუაცია ჩნდება, თუ ცხრილი ძალიან მცირეა, ან თუ ცხრილს აქვს მრავალი სტრიქონი, მაგრამ მათგან რამდენიმე არის ინდექსის ჩანაწერი;
- თუ თქვენი მოთხოვნა წინადადებებზე არ იყენებს ინდექსს;
- თუ ინდექსი ასევე ჩამოიშლება მის ხელახლა აშენებამდე.
ეს სტატია განიხილავს ინდექსებს და მათ როლს შეკითხვის შესრულების დროის ოპტიმიზაციაში. სტატიის პირველ ნაწილში განხილულია ინდექსების სხვადასხვა ფორმები და მათი შენახვა. შემდეგი, ჩვენ განვიხილავთ სამ მთავარ Transact-SQL განცხადებას, რომლებიც გამოიყენება ინდექსებთან მუშაობისთვის: CREATE INDEX, ALTER INDEX და DROP INDEX. შემდეგ განიხილება სისტემის მუშაობაზე მისი გავლენის ინდექსების ფრაგმენტაცია. შემდეგ ის იძლევა რამდენიმე ზოგად სახელმძღვანელოს ინდექსების შესაქმნელად და აღწერს ინდექსების რამდენიმე სპეციალურ ტიპს.
Ზოგადი ინფორმაცია
მონაცემთა ბაზის სისტემები, როგორც წესი, იყენებენ ინდექსებს, რათა უზრუნველყონ სწრაფი წვდომა რელაციურ მონაცემებზე. ინდექსი არის ცალკეული ფიზიკური მონაცემების სტრუქტურა, რომელიც იძლევა მონაცემთა ერთ ან მეტ მწკრივზე სწრაფ წვდომას. ამრიგად, ინდექსების სწორად დარეგულირება არის შეკითხვის შესრულების გაუმჯობესების მთავარი ასპექტი.
მონაცემთა ბაზის ინდექსი მრავალი თვალსაზრისით ჰგავს წიგნის ინდექსს (ანბანური ინდექსი). როცა წიგნში თემის სწრაფად პოვნა გვჭირდება, ჯერ ინდექსში ვეძებთ წიგნის რომელ გვერდებზეა განხილული ეს თემა და შემდეგ დაუყოვნებლივ ვხსნით სასურველ გვერდს. ანალოგიურად, ცხრილის კონკრეტული მწკრივის ძიებისას, მონაცემთა ბაზის ძრავა წვდება ინდექსს, რათა იპოვოს მისი ფიზიკური მდებარეობა.
მაგრამ არსებობს ორი მნიშვნელოვანი განსხვავება წიგნის ინდექსსა და მონაცემთა ბაზის ინდექსს შორის:
წიგნის მკითხველს აქვს შესაძლებლობა, თავად გადაწყვიტოს, გამოიყენოს თუ არა ინდექსი თითოეულ კონკრეტულ შემთხვევაში. მონაცემთა ბაზის მომხმარებელს არ აქვს ეს შესაძლებლობა და ეს გადაწყვეტილება მისთვის მიიღება სისტემის კომპონენტის მიერ, რომელსაც ე.წ შეკითხვის ოპტიმიზატორი. (მომხმარებელს შეუძლია ინდექსების გამოყენებით მანიპულირება ინდექსის მინიშნებების საშუალებით, მაგრამ ეს მინიშნებები რეკომენდებულია მხოლოდ შეზღუდული რაოდენობის სპეციალურ შემთხვევებში.)
სამუშაო წიგნთან ერთად იქმნება კონკრეტული სამუშაო წიგნის ინდექსი, რის შემდეგაც იგი აღარ იცვლება. ეს ნიშნავს, რომ კონკრეტული თემის ინდექსი ყოველთვის მიუთითებს იმავე გვერდის ნომერზე. ამის საპირისპიროდ, მონაცემთა ბაზის ინდექსი შეიძლება შეიცვალოს, როდესაც შეიცვლება შესაბამისი მონაცემები.
თუ ცხრილს არ აქვს შესაბამისი ინდექსი, სისტემა იყენებს ცხრილის სკანირების მეთოდს რიგების მოსაძიებლად. გამოხატულება მაგიდის სკანირებანიშნავს, რომ სისტემა თანმიმდევრულად იბრუნებს და იკვლევს ცხრილის თითოეულ სტრიქონს (პირველიდან ბოლომდე) და ათავსებს მწკრივს შედეგების კომპლექტში, თუ WHERE პუნქტში ძებნის პირობა დაკმაყოფილებულია მისთვის. ამრიგად, ყველა სტრიქონი ამოღებულია მეხსიერებაში მათი ფიზიკური მდებარეობის მიხედვით. ეს მეთოდი ნაკლებად ეფექტურია, ვიდრე ინდექსების გამოყენებით წვდომა, როგორც ეს ქვემოთ არის ახსნილი.
ინდექსები ინახება მონაცემთა ბაზის დამატებით სტრუქტურებში, რომელსაც ე.წ ინდექსის გვერდები. თითოეული ინდექსირებული მწკრივისთვის არის ინდექსის ჩანაწერი, რომელიც ინახება ინდექსის გვერდზე. თითოეული ინდექსის ელემენტი შედგება ინდექსის გასაღებისა და ინდექსისგან. სწორედ ამიტომ, ინდექსის ელემენტი მნიშვნელოვნად უფრო მოკლეა, ვიდრე ცხრილის მწკრივი, რომელზეც ის მიუთითებს. ამ მიზეზით, ინდექსის ელემენტების რაოდენობა თითოეულ ინდექსის გვერდზე გაცილებით მეტია, ვიდრე მონაცემთა გვერდის მწკრივების რაოდენობა.
ინდექსების ეს თვისება ძალზე მნიშვნელოვანია, რადგან ინდექსის გვერდებზე გადასასვლელად საჭირო I/O ოპერაციების რაოდენობა მნიშვნელოვნად ნაკლებია, ვიდრე შესაბამისი მონაცემთა გვერდების გადასასვლელად საჭირო I/O ოპერაციების რაოდენობა. სხვა სიტყვებით რომ ვთქვათ, ცხრილის სკანირება მოითხოვს უფრო მეტ I/O ოპერაციას, ვიდრე ცხრილის ინდექსის სკანირება.
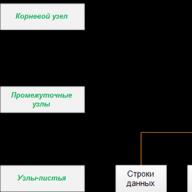
მონაცემთა ბაზის ძრავის ინდექსები იქმნება B+ ხის მონაცემთა სტრუქტურის გამოყენებით. B+ ხეს აქვს ხის სტრუქტურა, რომელშიც ყველა ქვედა კვანძი იმავე რაოდენობის დონეზეა დაშორებული ხის ზემოდან (ძირეული კვანძი). ეს თვისება შენარჩუნებულია მაშინაც კი, როდესაც მონაცემები დაემატება ან ამოღებულია ინდექსირებული სვეტიდან.
ქვემოთ მოყვანილი სურათი გვიჩვენებს B+ ხის სტრუქტურას Employee ცხრილისთვის და პირდაპირ წვდომას ამ ცხრილის მწკრივზე 25348 მნიშვნელობით Id სვეტისთვის. (ვვარაუდობთ, რომ Employee ცხრილი ინდექსირებულია Id სვეტით.) ამ ფიგურაში ასევე შეგიძლიათ იხილოთ, რომ B+ ხე შედგება ძირეული კვანძისგან, ხის კვანძებისგან და ნულოვანი ან მეტი შუალედური კვანძებისგან:
ამ ხეში შეგიძლიათ მოძებნოთ 25348 მნიშვნელობა შემდეგნაირად. ხის ფესვიდან დაწყებული, ის ეძებს ყველაზე პატარა საკვანძო მნიშვნელობას, რომელიც აღემატება სასურველ მნიშვნელობას. ამრიგად, ძირეულ კვანძში ეს მნიშვნელობა იქნება 29346, ამიტომ ხდება გადასვლა ამ მნიშვნელობასთან დაკავშირებულ შუალედურ კვანძზე. ამ კვანძში მნიშვნელობა 28559 აკმაყოფილებს მითითებულ მოთხოვნებს, რის შედეგადაც ხდება ამ მნიშვნელობასთან დაკავშირებულ ხის კვანძზე გადასვლა. ეს კვანძი შეიცავს სასურველ მნიშვნელობას 25348. საჭირო ინდექსის დადგენის შემდეგ, შეგვიძლია გამოვყოთ მისი მწკრივი მონაცემთა ცხრილიდან შესაბამისი მაჩვენებლების გამოყენებით. (ალტერნატიული ეკვივალენტური მიდგომა იქნება ინდექსზე ნაკლები ან ტოლი მნიშვნელობის ძიება.)
ინდექსირებული ძიება, როგორც წესი, უპირატესი მეთოდია დიდი რაოდენობით რიგების ცხრილების საძიებლად მისი აშკარა უპირატესობების გამო. ინდექსირებული ძიების გამოყენებით, ჩვენ შეგვიძლია ვიპოვოთ ცხრილის ნებისმიერი მწკრივი ძალიან მოკლე დროში, მხოლოდ რამდენიმე I/O ოპერაციების გამოყენებით. და თანმიმდევრული ძიება (ანუ ცხრილის სკანირება პირველი მწკრივიდან ბოლომდე) მეტ დროს მოითხოვს, რაც უფრო შორს არის საჭირო მწკრივი.
შემდეგ განყოფილებებში ჩვენ განვიხილავთ ინდექსების ორ არსებულ ტიპს, კლასტერულ და არაკლასტერულს და ვისწავლით როგორ შევქმნათ ინდექსები.
კლასტერული ინდექსები
კლასტერული ინდექსიგანსაზღვრავს მონაცემების ფიზიკურ თანმიმდევრობას ცხრილში. მონაცემთა ბაზის ძრავა საშუალებას გაძლევთ შექმნათ მხოლოდ ერთი კლასტერული ინდექსი ცხრილისთვის, რადგან ცხრილის რიგები ფიზიკურად არ შეიძლება დალაგდეს ერთზე მეტი გზით. კლასტერული ინდექსის გამოყენებით ძიება ხორციელდება B+ ხის ძირეული კვანძიდან ხის კვანძებისკენ, რომლებიც ერთმანეთთან არის დაკავშირებული ორმაგად დაკავშირებულ სიაში ე.წ. გვერდის ჯაჭვი.
კლასტერული ინდექსის მნიშვნელოვანი თვისებაა ის, რომ მისი ხის კვანძები შეიცავს მონაცემთა გვერდებს. (დაჯგუფებული ინდექსის კვანძების ყველა სხვა დონე შეიცავს ინდექსის გვერდებს.) ცხრილს, რომელსაც აქვს კლასტერული ინდექსი განსაზღვრული (ცალსახად ან იმპლიციტურად), ეწოდება კლასტერული ცხრილი. კლასტერული ინდექსის B+ ხის სტრუქტურა ნაჩვენებია ქვემოთ მოცემულ ფიგურაში:

კლასტერული ინდექსი იქმნება ნაგულისხმევად თითოეულ ცხრილში, რომელსაც აქვს პირველადი გასაღები, რომელიც განისაზღვრება ძირითადი გასაღების შეზღუდვით. გარდა ამისა, თითოეული კლასტერული ინდექსი ნაგულისხმევად უნიკალურია, ე.ი. სვეტში, რომელსაც აქვს განსაზღვრული კლასტერული ინდექსი, თითოეული მონაცემთა მნიშვნელობა შეიძლება გამოჩნდეს მხოლოდ ერთხელ. თუ კლასტერული ინდექსი იქმნება სვეტზე, რომელიც შეიცავს დუბლიკატ მნიშვნელობებს, მონაცემთა ბაზის სისტემა აიძულებს გაურკვევლობას ოთხი ბაიტიანი იდენტიფიკატორის მიმატებით რიგებში, რომლებიც შეიცავს დუბლიკატ მნიშვნელობებს.
კლასტერული ინდექსები უზრუნველყოფს მონაცემთა ძალიან სწრაფ წვდომას, როდესაც მოთხოვნა ეძებს მნიშვნელობების დიაპაზონს.
არაკლასტერული ინდექსები
არაკლასტერული ინდექსის სტრუქტურა ზუსტად იგივეა, რაც კლასტერული ინდექსი, მაგრამ ორი მნიშვნელოვანი განსხვავებებით:
არაკლასტერული ინდექსი არ ცვლის ცხრილის რიგების ფიზიკურ წესრიგს;
არაკლასტერული ინდექსის კვანძის გვერდები შედგება ინდექსის გასაღებებისა და სანიშნეებისგან.
თუ ცხრილზე განსაზღვრავთ ერთ ან მეტ არაკლასტერულ ინდექსს, ცხრილის რიგების ფიზიკური თანმიმდევრობა არ შეიცვლება. თითოეული არაკლასტერული ინდექსისთვის მონაცემთა ბაზის ძრავა ქმნის დამატებით ინდექსის სტრუქტურას, რომელიც ინახება ინდექსის გვერდებზე. არაკლასტერული ინდექსის B+ ხის სტრუქტურა ნაჩვენებია ქვემოთ მოცემულ ფიგურაში:

არაკლასტერულ ინდექსში სანიშნე მიუთითებს სად მდებარეობს ინდექსის კლავიშის შესაბამისი მწკრივი. ინდექსის გასაღების სანიშნე კომპონენტი შეიძლება იყოს ორი ტიპის, იმისდა მიხედვით, ცხრილი არის კლასტერული ცხრილი თუ გროვა. (SQL Server-ის ტერმინოლოგიაში, გროვა არის ცხრილი კლასტერული ინდექსის გარეშე.) თუ კლასტერული ინდექსი არსებობს, არაკლასტერული ინდექსის ჩანართი აჩვენებს ცხრილის დაჯგუფებული ინდექსის B+ ხეს. თუ ცხრილს არ აქვს კლასტერული ინდექსი, სანიშნე იდენტურია მწკრივის იდენტიფიკატორი (RID - მწკრივის იდენტიფიკატორი), შედგება სამი ნაწილისაგან: ფაილის მისამართი, რომელშიც ინახება ცხრილი, ფიზიკური ბლოკის (გვერდის) მისამართი, რომელშიც ინახება მწკრივი, და მწკრივის ოფსეტური გვერდზე.
როგორც უკვე აღვნიშნეთ, მონაცემთა ძებნა არაკლასტერული ინდექსის გამოყენებით შეიძლება განხორციელდეს ორი განსხვავებული გზით, ცხრილის ტიპის მიხედვით:
heap - კვეთს არაკლასტერული ინდექსის საძიებო სტრუქტურას, რის შემდეგაც ხდება მწკრივის ამოღება მწკრივის იდენტიფიკატორის გამოყენებით;
კლასტერული ცხრილი - არაკლასტერული ინდექსის სტრუქტურის საძიებო ტრავერსია, რასაც მოჰყვება შესაბამისი კლასტერული ინდექსის გადაკვეთა.
ორივე შემთხვევაში, I/O ოპერაციების რაოდენობა საკმაოდ დიდია, ამიტომ სიფრთხილით უნდა შეიმუშავოთ არაკლასტერული ინდექსი და გამოიყენოთ იგი მხოლოდ იმ შემთხვევაში, თუ დარწმუნებული ხართ, რომ მისი გამოყენება მნიშვნელოვნად გააუმჯობესებს შესრულებას.
Transact-SQL ენა და ინდექსები
ახლა, როდესაც ჩვენ ვიცნობთ ინდექსების ფიზიკურ სტრუქტურას, ამ განყოფილებაში განვიხილავთ, თუ როგორ შევქმნათ, შევცვალოთ და წავშალოთ ინდექსები, ასევე როგორ მივიღოთ ინდექსების ფრაგმენტაციის ინფორმაცია და ინდექსის ინფორმაციის რედაქტირება. ეს ყველაფერი მოგვამზადებს სისტემის მუშაობის გასაუმჯობესებლად ინდექსების გამოყენების შემდგომი განხილვისთვის.
ინდექსების შექმნა
ცხრილის ინდექსი იქმნება განცხადების გამოყენებით ინდექსის შექმნა. ამ ინსტრუქციას აქვს შემდეგი სინტაქსი:
შექმენით INDEX index_name ON table_name (სვეტი1,...) [INCLUDE (სვეტის_სახელი [,... ]) ] [[, ] PAD_INDEX = (ჩართვა | გამორთვა)] [[, ] DROP_EXISTING = (ჩართვა | გამორთვა)] [[ , ] SORT_IN_TEMPDB = (ჩართვა | გამორთვა)] [[, ] IGNORE_DUP_KEY = (ჩართვა | გამორთვა)] [[, ] ALLOW_ROW_LOCKS = (ჩართვა | გამორთვა)] [[, ] ALLOW_PAGE_LOCKS = (ჩართვა | გამორთვა)] [[, ] STATISTICS_NORECOMPUTE = (ჩართვა | გამორთვა)] [[, ] ონლაინ = (ჩართვა | გამორთვა)]] სინტაქსის კონვენცია
index_name პარამეტრი განსაზღვრავს შესაქმნელად ინდექსის სახელს. ინდექსი შეიძლება შეიქმნას ერთი ცხრილის ერთ ან მეტ სვეტზე, იდენტიფიცირებული table_name პარამეტრით. სვეტი, რომელზედაც იქმნება ინდექსი, მითითებულია სვეტის1 პარამეტრით. ამ პარამეტრის რიცხვითი სუფიქსი მიუთითებს, რომ ინდექსი შეიძლება შეიქმნას ცხრილის რამდენიმე სვეტზე. მონაცემთა ბაზის ძრავა ასევე მხარს უჭერს ხედებზე ინდექსების შექმნას.
შეგიძლიათ ნებისმიერი ცხრილის სვეტის ინდექსირება. ეს ნიშნავს, რომ VARBINARY(max), BIGINT და SQL_VARIANT მონაცემთა ტიპის მნიშვნელობების შემცველი სვეტები ასევე შეიძლება იყოს ინდექსირებული.
ინდექსი შეიძლება იყოს მარტივი ან კომპოზიციური. მარტივი ინდექსი იქმნება ერთ სვეტზე, ხოლო რთული ინდექსი რამდენიმე სვეტზე. რთული ინდექსს აქვს გარკვეული შეზღუდვები, რომლებიც დაკავშირებულია მის ზომასთან და სვეტების რაოდენობასთან. ინდექსს შეიძლება ჰქონდეს მაქსიმუმ 900 ბაიტი და მაქსიმუმ 16 სვეტი.
UNIQUE პარამეტრიმიუთითებს, რომ ინდექსირებული სვეტი შეიძლება შეიცავდეს მხოლოდ ერთმნიშვნელოვან (ანუ არაგანმეორებად) მნიშვნელობებს. ერთი ღირებულების კომპოზიტურ ინდექსში, უნიკალური უნდა იყოს თითოეული მწკრივის ყველა სვეტის მნიშვნელობების კომბინაცია. თუ UNIQUE საკვანძო სიტყვა არ არის მითითებული, მაშინ დასაშვებია მნიშვნელობების დუბლიკატი ინდექსირებული სვეტ(ებ)ში.
CLUSTERED პარამეტრიგანსაზღვრავს კლასტერულ ინდექსს და NONCLUSTERED პარამეტრი(ნაგულისხმევი) მიუთითებს, რომ ინდექსი არ ცვლის ცხრილის რიგების თანმიმდევრობას. მონაცემთა ბაზის ძრავა იძლევა მაქსიმუმ 249 არაკლასტერულ ინდექსს მაგიდაზე.
მონაცემთა ბაზის ძრავა გაუმჯობესებულია, რათა მხარდაჭერილი იყოს სვეტების მნიშვნელობების კლებადი მიმდევრობის მქონე ინდექსები. ASC პარამეტრი სვეტის სახელის შემდეგ მიუთითებს, რომ ინდექსი იქმნება სვეტის მნიშვნელობების აღმავალი თანმიმდევრობით, ხოლო DESC პარამეტრი მიუთითებს ინდექსის სვეტის მნიშვნელობების კლებადობით. ეს უზრუნველყოფს უფრო მეტ მოქნილობას ინდექსის გამოყენებისას. კლებადობით, თქვენ უნდა შექმნათ კომპოზიტური ინდექსები სვეტებზე, რომელთა მნიშვნელობები დალაგებულია საპირისპირო მიმართულებით.
პარამეტრის ჩართვასაშუალებას გაძლევთ მიუთითოთ არასაკვანძო სვეტები, რომლებიც დაემატება არაკლასტერული ინდექსის კვანძების გვერდებს. INCLUDE სიაში სვეტების სახელები არ უნდა განმეორდეს და სვეტი არ შეიძლება გამოყენებულ იქნას როგორც გასაღების, ისე არა გასაღების სვეტად.
იმისთვის, რომ ნამდვილად გაიგოთ INCLUDE პარამეტრის სარგებლიანობა, უნდა გესმოდეთ რა არის ეს დაფარვის ინდექსი. თუ მოთხოვნის ყველა სვეტი შედის ინდექსში, შეგიძლიათ მიიღოთ მნიშვნელოვანი შესრულების გაუმჯობესება, რადგან შეკითხვის ოპტიმიზატორს შეუძლია ყველა სვეტის მნიშვნელობების განთავსება ინდექსის გვერდებზე, ცხრილის მონაცემებზე წვდომის გარეშე. ამ შესაძლებლობას ეწოდება დაფარვის ინდექსი ან დაფარვის მოთხოვნა. ამიტომ, არაკლასტერული ინდექსის კვანძების გვერდებზე დამატებითი არა გასაღების სვეტების ჩართვა საშუალებას მოგცემთ მიიღოთ მეტი დაფარვის მოთხოვნები და მნიშვნელოვნად გააუმჯობესოთ მათი შესრულება.
FILLFACTOR პარამეტრიგანსაზღვრავს თითოეული ინდექსის გვერდის პროცენტს, რომელიც უნდა შეივსოს ინდექსის შექმნის დროს. FILLFACTOR პარამეტრის მნიშვნელობა შეიძლება დაყენდეს 1-დან 100-მდე დიაპაზონში. n=100 მნიშვნელობით, ყოველი ინდექსის გვერდი ივსება 100%-მდე, ე.ი. არსებულ კვანძის გვერდს, ისევე როგორც არა-კვანძის გვერდს არ ექნება თავისუფალი ადგილი ახალი რიგების ჩასართავად. ამიტომ, რეკომენდებულია ამ მნიშვნელობის გამოყენება მხოლოდ სტატიკური ცხრილებისთვის. (ნაგულისხმევი მნიშვნელობა, n=0, ნიშნავს, რომ ინდექსის კვანძის გვერდები სავსეა და ყოველი შუალედური გვერდი შეიცავს თავისუფალ ადგილს ერთი ჩანაწერისთვის.)
თუ FILLFACTOR პარამეტრი დაყენებულია 1-დან 99-მდე მნიშვნელობებზე, შექმნილი ინდექსის სტრუქტურის კვანძის გვერდები შეიცავს თავისუფალ ადგილს. რაც უფრო დიდია n-ის მნიშვნელობა, მით ნაკლებია თავისუფალი ადგილი ინდექსის კვანძის გვერდებზე. მაგალითად, n=60-ით, თითოეულ ინდექსის კვანძის გვერდს ექნება 40% თავისუფალი ადგილი მომავალი ინდექსის მწკრივის ჩასართავად. (ინდექსის რიგები ჩასმულია INSERT ან UPDATE განცხადების გამოყენებით.) ამრიგად, n=60 მნიშვნელობა გონივრული იქნება ცხრილებისთვის, რომელთა მონაცემებიც საკმაოდ ხშირად იცვლება. FILLFACTOR მნიშვნელობებისთვის 1-დან 99-მდე, შუალედური ინდექსის გვერდები შეიცავს თავისუფალ ადგილს თითო ჩანაწერისთვის.
ინდექსის შექმნის შემდეგ, FILLFACTOR მნიშვნელობა არ არის მხარდაჭერილი გამოყენებისას. სხვა სიტყვებით რომ ვთქვათ, ის მხოლოდ მიუთითებს თავისუფალი სივრცის პროცენტის დაყენებისას ხელმისაწვდომი მონაცემებით დაჯავშნულ სივრცეში. FILLFACTOR პარამეტრის თავდაპირველ მნიშვნელობამდე დასაბრუნებლად გამოიყენეთ ALTER INDEX განცხადება.
პარამეტრი PAD_INDEXმჭიდროდ არის დაკავშირებული FILLFACTOR პარამეტრთან. FILLFACTOR პარამეტრი ძირითადად განსაზღვრავს თავისუფალი სივრცის რაოდენობას ინდექსის კვანძების მთლიანი გვერდის ზომის პროცენტულად. და PAD_INDEX პარამეტრი განსაზღვრავს, რომ FILLFACTOR პარამეტრის მნიშვნელობა ვრცელდება როგორც ინდექსის გვერდებზე, ასევე მონაცემთა გვერდებზე ინდექსში.
DROP_EXISTING პარამეტრისაშუალებას გაძლევთ გააუმჯობესოთ შესრულება კლასტერული ინდექსის რეპროდუცირებისას მაგიდაზე, რომელსაც ასევე აქვს არაკლასტერული ინდექსი. დამატებითი ინფორმაციისთვის იხილეთ განყოფილება "ინდექსის აღდგენა" ქვემოთ.
SORT_IN_TEMPDB პარამეტრიგამოიყენება ინდექსის შექმნისას გამოყენებული შუალედური დახარისხების ოპერაციებიდან მონაცემების tempdb სისტემის მონაცემთა ბაზაში განსათავსებლად. ამან შეიძლება გააუმჯობესოს შესრულება, თუ tempdb განთავსებულია მონაცემებისგან განსხვავებულ დისკზე.
IGNORE_DUP_KEY პარამეტრისაშუალებას აძლევს სისტემას უგულებელყოს დუბლიკატი მნიშვნელობების ინდექსირებულ სვეტებში ჩასმის მცდელობა. ეს პარამეტრი უნდა იქნას გამოყენებული მხოლოდ ხანგრძლივი ტრანზაქციის შეწყვეტის თავიდან აცილების მიზნით, როდესაც INSERT განცხადება ჩასვამს დუბლიკატულ მონაცემებს ინდექსირებულ სვეტში. როდესაც ეს პარამეტრი ჩართულია, როდესაც INSERT განცხადება ცდილობს ცხრილში ჩასვას რიგები, რომლებიც არღვევს ინდექსის უნიკალურობას, მონაცემთა ბაზის სისტემა უბრალოდ გასცემს გაფრთხილებას მთელი განცხადების გაფუჭების ნაცვლად. ამ შემთხვევაში, მონაცემთა ბაზის ძრავა არ ჩასვამს სტრიქონებს დუბლიკატი საკვანძო მნიშვნელობებით, არამედ უბრალოდ უგულებელყოფს მათ და ამატებს სწორ რიგებს. თუ ეს პარამეტრი არ არის დაყენებული, მაშინ მთელი ინსტრუქციის შესრულება არანორმალურად შეწყდება.
Როდესაც პარამეტრი ALLOW_ROW_LOCKSგააქტიურებულია (ჩართულია), სისტემა იყენებს მწკრივის ჩაკეტვას. ანალოგიურად, როდესაც გააქტიურებულია პარამეტრი ALLOW_PAGE_LOCKS, სისტემა იყენებს გვერდის ჩაკეტვას ერთდროული წვდომის დროს. STATISTICS_NORECOMPUTE პარამეტრიგანსაზღვრავს სტატისტიკის ავტომატური გადაანგარიშების მდგომარეობას მითითებული ინდექსისთვის.
გააქტიურებულია ONLINE პარამეტრისაშუალებას გაძლევთ შექმნათ, ხელახლა შექმნათ და წაშალოთ ინდექსი დიალოგურ რეჟიმში. ეს პარამეტრი საშუალებას გაძლევთ ერთდროულად შეცვალოთ ძირითადი ცხრილის ან კლასტერული ინდექსის მონაცემები და ნებისმიერი ასოცირებული ინდექსები ინდექსის შეცვლისას. მაგალითად, სანამ კლასტერული ინდექსი ხელახლა იქმნება, შეგიძლიათ გააგრძელოთ მისი მონაცემების განახლება და ამ მონაცემებზე მოთხოვნების გაშვება.
პარამეტრი ჩართულიაქმნის მითითებულ ინდექსს ფაილის ნაგულისხმევ ჯგუფზე (ნაგულისხმევი მნიშვნელობა) ან მითითებულ ფაილურ ჯგუფზე (ფაილის_ჯგუფის მნიშვნელობა).
ქვემოთ მოყვანილი მაგალითი გვიჩვენებს, თუ როგორ უნდა შექმნათ არაკლასტერული ინდექსი Employee ცხრილის ID სვეტზე:
გამოიყენეთ SampleDb; CREATE INDEX ix_empid ON Employee(Id);
ერთი ღირებულების კომპოზიტური ინდექსის შექმნა ნაჩვენებია ქვემოთ მოცემულ მაგალითში:
გამოიყენეთ SampleDb; შექმენით უნიკალური ინდექსი ix_empid_prnu ON Works_on (EmpId, ProjectNumber) FILLFACTOR= 80-ით;
ამ მაგალითში, თითოეულ სვეტში მნიშვნელობები უნდა იყოს ერთნიშნა. ინდექსის შექმნისას ივსება სივრცის 80% თითოეულ ინდექსის კვანძის გვერდზე.
თქვენ არ შეგიძლიათ შექმნათ უნიკალური ინდექსი სვეტზე, თუ სვეტი შეიცავს დუბლიკატ მნიშვნელობებს. ასეთი ინდექსი შეიძლება შეიქმნას მხოლოდ იმ შემთხვევაში, თუ თითოეული მნიშვნელობა (მათ შორის NULL მნიშვნელობები) გამოჩნდება ზუსტად ერთხელ სვეტში. გარდა ამისა, არსებული მონაცემთა მნიშვნელობის ჩასმის ან შეცვლის ნებისმიერი მცდელობა არსებულ უნიკალურ ინდექსში შემავალ სვეტში უარყოფილი იქნება სისტემის მიერ, თუ მნიშვნელობა დუბლირებულია.
ინდექსის ფრაგმენტაციის შესახებ ინფორმაციის მიღება
ინდექსის სიცოცხლის განმავლობაში, ის შეიძლება ფრაგმენტული გახდეს, რაც ინდექსების გვერდებზე მონაცემების შენახვის პროცესს არაეფექტური გახდის. არსებობს ინდექსის ფრაგმენტაციის ორი ტიპი: შიდა ფრაგმენტაცია და გარე ფრაგმენტაცია. შიდა ფრაგმენტაცია განსაზღვრავს თითოეულ გვერდზე შენახული მონაცემების რაოდენობას, ხოლო გარე ფრაგმენტაცია ხდება მაშინ, როდესაც გვერდები ლოგიკური წესრიგის გარეშეა.
ინდექსის შიდა ფრაგმენტაციის შესახებ ინფორმაციის მისაღებად, DMV დინამიური მართვის ხედი ე.წ sys.dm_db_index_physical_stats. ეს DMV აბრუნებს ინფორმაციას მითითებული გვერდის მონაცემებისა და ინდექსების მოცულობისა და ფრაგმენტაციის შესახებ. თითოეული გვერდისთვის, თითო მწკრივი ბრუნდება B+ ხის თითოეული დონისთვის. ამ DMV-ის გამოყენებით, შეგიძლიათ მიიღოთ ინფორმაცია მონაცემთა გვერდებზე მწკრივების ფრაგმენტაციის ხარისხის შესახებ, რის საფუძველზეც შეგიძლიათ გადაწყვიტოთ მონაცემების რეორგანიზაცია.
sys.dm_db_index_physical_stats ხედის გამოყენება ნაჩვენებია ქვემოთ მოცემულ მაგალითში. (სანამ ჯგუფური მაგალითის გაშვებამდე, თქვენ უნდა ჩამოაგდოთ ყველა არსებული ინდექსი Works_on მაგიდაზე. ინდექსების ჩამოსაშლელად გამოიყენეთ DROP INDEX განცხადება, რომელიც ნაჩვენებია მოგვიანებით.)
გამოიყენეთ SampleDb; გამოაცხადეთ @dbId INT; გამოაცხადეთ @tabId INT; გამოაცხადეთ @indId INT; SET @dbId = DB_ID("SampleDb"); SET @tabId = OBJECT_ID ("თანამშრომელი"); აირჩიეთ avg_fragmentation_in_percent, avg_page_space_used_in_percent FROM sys.dm_db_index_physical_stats (@dbId, @tabId, NULL, NULL, NULL);
როგორც მაგალითიდან ხედავთ, sys.dm_db_index_physical_stats ხედს აქვს ხუთი პარამეტრი. პირველი სამი პარამეტრი განსაზღვრავს მიმდინარე მონაცემთა ბაზის, ცხრილისა და ინდექსის ID-ებს, შესაბამისად. მეოთხე პარამეტრი განსაზღვრავს დანაყოფის ID-ს, ხოლო ბოლო პარამეტრი განსაზღვრავს სკანირების დონეს, რომელიც გამოიყენება სტატისტიკური ინფორმაციის მისაღებად. (კონკრეტული პარამეტრის ნაგულისხმევი მნიშვნელობა შეიძლება განისაზღვროს NULL მნიშვნელობის გამოყენებით.)
ამ ხედში ყველაზე მნიშვნელოვანი სვეტებია avg_fragmentation_in_percent და avg_page_space_used_in_percent სვეტები. პირველი მიუთითებს ფრაგმენტაციის საშუალო დონეს პროცენტულად, ხოლო მეორე განსაზღვრავს დაკავებული სივრცის რაოდენობას პროცენტულად.
ინდექსის ინფორმაციის რედაქტირება
მას შემდეგ რაც გაეცნობით ინდექსის ფრაგმენტაციის ინფორმაციას, როგორც ეს იყო განხილული წინა ნაწილში, შეგიძლიათ შეცვალოთ ეს და სხვა ინდექსის ინფორმაცია შემდეგი სისტემის ხელსაწყოების გამოყენებით:
დირექტორია views sys.indexes;
კატალოგის ნახვები sys.index_columns;
სისტემის პროცედურა sp_helpindex;
ობიექტის საკუთრების ფუნქციები;
SQL Server Management Studio მართვის გარემო;
DMV დინამიური მართვის ხედი sys.dm_db_index_usage_stats;
DMV დინამიური მართვის ხედი sys.dm_db_missing_index_details.
კატალოგის ხედი sys.indexesშეიცავს რიგს თითოეული ინდექსისთვის და რიგს თითოეული ცხრილისთვის კლასტერული ინდექსის გარეშე. ამ კატალოგის ხედის ყველაზე მნიშვნელოვანი სვეტებია object_id, name და index_id სვეტები. სვეტი object_id შეიცავს მონაცემთა ბაზის ობიექტის სახელს, რომელიც ფლობს ინდექსს, ხოლო სახელი და index_id სვეტები შეიცავს შესაბამისად ამ ინდექსის სახელს და ID-ს.
კატალოგის ხედი sys.index_columnsშეიცავს რიგს თითოეული სვეტისთვის, რომელიც არის ინდექსის ან გროვის ნაწილი. ეს ინფორმაცია შეიძლება გამოყენებულ იქნას sys.indexes კატალოგის ხედით მიღებულ ინფორმაციასთან ერთად, რათა მიიღოთ დამატებითი ინფორმაცია მითითებული ინდექსის თვისებების შესახებ.
სისტემური პროცედურა sp_helpindexაბრუნებს ინფორმაციას ცხრილის ინდექსების შესახებ, ასევე სტატისტიკურ ინფორმაციას სვეტებისთვის. ამ პროცედურას აქვს შემდეგი სინტაქსი:
sp_helpindex [@db_object = ] "სახელი"
აქ @db_object ცვლადი წარმოადგენს ცხრილის სახელს.
ინდექსებთან დაკავშირებით, ობიექტის საკუთრების ფუნქციააქვს ორი თვისება: IsIndexed და IsIndexable. პირველი თვისება გვაწვდის ინფორმაციას იმის შესახებ, აქვს თუ არა ცხრილს ან ხედს ინდექსი, ხოლო მეორე თვისება მიუთითებს, არის თუ არა ცხრილი ან ხედი ინდექსირებადი.
SQL Server Management Studio-ის გამოყენებით არსებული ინდექსის ინფორმაციის რედაქტირებისთვის, აირჩიეთ სასურველი მონაცემთა ბაზა Databases საქაღალდეში, გააფართოვეთ Tables კვანძი და ამ კვანძში გააფართოვეთ სასურველი ცხრილი და მისი Indexes საქაღალდე. ცხრილის ინდექსების საქაღალდე აჩვენებს ამ ცხრილის ყველა არსებული ინდექსების სიას. ინდექსზე ორჯერ დაწკაპუნებით გაიხსნება Index Properties დიალოგური ფანჯარა ამ ინდექსის თვისებებით. (ასევე შეგიძლიათ შექმნათ ახალი ინდექსი ან წაშალოთ არსებული მენეჯმენტის სტუდიის გამოყენებით.)
Შესრულება sys.dm_db_index_usage_statsაბრუნებს სხვადასხვა ტიპის ინდექსის ოპერაციების რაოდენობას და ბოლო დროს, როდესაც შესრულდა თითოეული ტიპის ოპერაცია. ყოველი ცალკე ძიება, ძიება ან განახლების ოპერაცია მითითებულ ინდექსზე ერთ მოთხოვნაში განიხილება ინდექსის გამოყენებად და მატებს შესაბამის მრიცხველს ამ DMV-ში ერთით. ამ გზით, თქვენ შეგიძლიათ მიიღოთ ზოგადი ინფორმაცია იმის შესახებ, თუ რამდენად ხშირად გამოიყენება ინდექსი, ასე რომ თქვენ შეგიძლიათ გამოიყენოთ იგი იმის დასადგენად, თუ რომელი ინდექსები გამოიყენება უფრო ხშირად და რომელი უფრო ნაკლებად გამოიყენება.
Შესრულება sys.dm_db_missing_index_detailsაბრუნებს დეტალურ ინფორმაციას ცხრილის სვეტების შესახებ, რომლებისთვისაც არ არის ინდექსები. ამ DMV-ის ყველაზე მნიშვნელოვანი სვეტებია index_handle და object_id სვეტები. პირველი სვეტის მნიშვნელობა განსაზღვრავს კონკრეტულ გამოტოვებულ ინდექსს, ხოლო მეორე სვეტის მნიშვნელობა განსაზღვრავს ცხრილს, რომელზეც ინდექსი აკლია.
ინდექსების შეცვლა
მონაცემთა ბაზის ძრავა არის ერთ-ერთი იმ რამდენიმე მონაცემთა ბაზის სისტემა, რომელიც მხარს უჭერს განცხადებას ALTER ინდექსი. ეს განცხადება შეიძლება გამოყენებულ იქნას ინდექსის შენარჩუნების ოპერაციების შესასრულებლად. ALTER INDEX განცხადების სინტაქსი ძალიან ჰგავს CREATE INDEX განცხადების სინტაქსს. სხვა სიტყვებით რომ ვთქვათ, ეს განცხადება საშუალებას გაძლევთ შეცვალოთ ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY და STATISTICS_NORECOMPUTE პარამეტრების მნიშვნელობები, რომლებიც ადრე იყო აღწერილი CREATE INDEX განცხადებაში.
ზემოაღნიშნული ვარიანტების გარდა, ALTER INDEX განცხადება მხარს უჭერს სამ სხვა ვარიანტს:
REBUILD პარამეტრი, გამოიყენება ინდექსის ხელახლა შესაქმნელად;
REORGANIZE პარამეტრი, გამოიყენება ინდექსის კვანძის გვერდების რეორგანიზაციისთვის;
DISABLE პარამეტრი, გამოიყენება ინდექსის გასათიშად. ეს სამი ვარიანტი განიხილება შემდეგ ქვეთავებში.
ინდექსის აღდგენა
მონაცემების ნებისმიერმა ცვლილებამ INSERT, UPDATE ან DELETE განცხადებების გამოყენებით შეიძლება გამოიწვიოს მონაცემთა ფრაგმენტაცია. თუ ეს მონაცემები ინდექსირებულია, მაშინ ინდექსის ფრაგმენტაციაც შესაძლებელია, ინდექსის ინფორმაცია მიმოფანტული სხვადასხვა ფიზიკურ გვერდებზე. ინდექსის მონაცემების ფრაგმენტაციის შედეგად, მონაცემთა ბაზის ძრავა შეიძლება იძულებული იყოს შეასრულოს მონაცემების წაკითხვის დამატებითი ოპერაციები, რაც ამცირებს სისტემის მთლიან მუშაობას. ამ შემთხვევაში, თქვენ უნდა აღადგინოთ ყველა ფრაგმენტული ინდექსი.
ეს შეიძლება გაკეთდეს ორი გზით:
ALTER INDEX ამონაწერის REBUILD პარამეტრის მეშვეობით;
CREATE INDEX განცხადების DROP_EXISTING პარამეტრის მეშვეობით.
REBUILD პარამეტრი გამოიყენება ინდექსების აღდგენისთვის. თუ ამ პარამეტრის ინდექსის სახელის ნაცვლად ALL-ს მიუთითებთ, ცხრილის ყველა ინდექსი ხელახლა შეიქმნება. (ინდექსების დინამიურად ხელახალი შექმნის დაშვებით, თქვენ არ მოგიწევთ მათი ჩამოგდება და ხელახლა შექმნა.)
CREATE INDEX განცხადების DROP_EXISTING ვარიანტს შეუძლია გააუმჯობესოს ეფექტურობა კლასტერული ინდექსის ხელახლა შექმნისას მაგიდაზე, რომელსაც ასევე აქვს არაკლასტერული ინდექსები. იგი აზუსტებს, რომ არსებული კლასტერული ან არაკლასტერული ინდექსი უნდა ჩამოიშალოს და მითითებული ინდექსი ხელახლა შეიქმნას. როგორც უკვე აღვნიშნეთ, კლასტერულ ცხრილზე თითოეული არაკლასტერული ინდექსი თავის ხის კვანძებში შეიცავს ცხრილის კლასტერული ინდექსის შესაბამის მნიშვნელობებს. ამ მიზეზით, როდესაც მაგიდაზე ჩამოაგდებთ კლასტერულ ინდექსს, თქვენ უნდა ხელახლა შექმნათ მისი ყველა არაკლასტერული ინდექსი. DROP_EXISTING პარამეტრის გამოყენებით თავიდან აიცილებთ არაკლასტერული ინდექსების ხელახლა შექმნას.
DROP_EXISTING ვარიანტი უფრო ძლიერია ვიდრე REBUILD ვარიანტი, რადგან ის უფრო მოქნილია და გთავაზობთ რამდენიმე ვარიანტს, როგორიცაა სვეტების შეცვლა, რომლებიც ქმნიან ინდექსს და არაკლასტერული ინდექსის შეცვლა კლასტერულზე.
ინდექსის კვანძის გვერდების რეორგანიზაცია
ALTER INDEX განცხადების REORGANIZE პარამეტრი აწესრიგებს კვანძების გვერდებს მითითებულ ინდექსში ისე, რომ გვერდების ფიზიკური თანმიმდევრობა ემთხვევა მათ ლოგიკურ მიმდევრობას, მარცხნიდან მარჯვნივ. ეს შლის ინდექსის ფრაგმენტაციის გარკვეულ რაოდენობას, აუმჯობესებს ინდექსის შესრულებას.
ინდექსის გამორთვა
DISABLE ოფცია გამორთავს მითითებულ ინდექსს. გამორთული ინდექსი არ არის ხელმისაწვდომი გამოსაყენებლად, სანამ ის ხელახლა არ ჩაირთვება. გაითვალისწინეთ, რომ გამორთული ინდექსი არ იცვლება დაკავშირებულ მონაცემებში ცვლილებების შეტანისას. ამ მიზეზით, გამორთული ინდექსის ხელახლა გამოსაყენებლად, ის მთლიანად ხელახლა უნდა შეიქმნას. გამორთული ინდექსის გასააქტიურებლად გამოიყენეთ ALTER TABLE განაცხადის REBUILD ვარიანტი.
როდესაც მაგიდაზე კლასტერული ინდექსი გამორთულია, ცხრილის მონაცემები მიუწვდომელი იქნება, რადგან ცხრილის ყველა მონაცემთა გვერდი დაჯგუფებული ინდექსით ინახება მის ხის კვანძებში.
ინდექსების წაშლა და სახელის გადარქმევა
მიმდინარე მონაცემთა ბაზაში ინდექსების წასაშლელად გამოიყენეთ DROP INDEX ინსტრუქცია. გაითვალისწინეთ, რომ კლასტერული ინდექსის მაგიდაზე ჩაგდება შეიძლება იყოს ძალიან რესურსზე ინტენსიური ოპერაცია, რადგან საჭირო იქნება ყველა არაკლასტერული ინდექსის ხელახლა შექმნა. (ყველა არაკლასტერული ინდექსი იყენებს კლასტერული ინდექსის ინდექსის კლავიშს, როგორც მაჩვენებელს თავის კვანძის გვერდებზე.) DROP INDEX განაცხადის გამოყენება ინდექსის ჩამოსაშლელად ილუსტრირებულია ქვემოთ მოცემულ მაგალითში:
გამოიყენეთ SampleDb; DROP INDEX ix_empid ON თანამშრომელი;
DROP INDEX ინსტრუქციას აქვს დამატებითი პარამეტრზე გადატანა, რომლის მნიშვნელობა იგივეა რაც CREATE INDEX ამონაწერის ON პარამეტრი. სხვა სიტყვებით რომ ვთქვათ, შეგიძლიათ გამოიყენოთ ეს პარამეტრი, რათა მიუთითოთ სად გადაიტანოთ მონაცემთა რიგები, რომლებიც გროვდება ინდექსის კვანძების გვერდებზე. მონაცემები გადატანილია ახალ ადგილას გროვის სახით. თქვენ შეგიძლიათ მიუთითოთ ნაგულისხმევი ფაილური ჯგუფი ან დასახელებული ფაილური ჯგუფი მონაცემთა შენახვის ახალი მდებარეობისთვის.
DROP INDEX განცხადება არ შეიძლება გამოყენებულ იქნას ინდექსების ჩამოსაშლელად, რომლებიც წარმოიქმნება სისტემის მიერ მთლიანობის შეზღუდვებისთვის, როგორიცაა PRIMARY KEY და UNIQUE ინდექსები. ასეთი ინდექსების მოსაშორებლად, თქვენ უნდა ამოიღოთ შესაბამისი შეზღუდვა.
ინდექსების გადარქმევა შესაძლებელია sp_rename სისტემის პროცედურის გამოყენებით.
ინდექსების შექმნა, შეცვლა და წაშლა ასევე შესაძლებელია Management Studio-ში მონაცემთა ბაზის დიაგრამების ან Object Explorer-ის გამოყენებით. მაგრამ უმარტივესი გზაა საჭირო ცხრილის Indexes საქაღალდის გამოყენება. მენეჯმენტ სტუდიაში ინდექსების მართვა მენეჯმენტ სტუდიაში ცხრილების მართვის მსგავსია.
მიუხედავად იმისა, რომ მონაცემთა ბაზის ძრავა არ აყენებს პრაქტიკულ შეზღუდვას ინდექსების რაოდენობაზე, არსებობს რამდენიმე მიზეზი, თუ რატომ უნდა შეზღუდოთ რაოდენობა. პირველ რიგში, თითოეული ინდექსი იკავებს გარკვეულ ადგილს დისკზე, ამიტომ არსებობს შესაძლებლობა, რომ მონაცემთა ბაზის ინდექსის გვერდების საერთო რაოდენობამ გადააჭარბოს მონაცემთა ბაზაში არსებული მონაცემთა გვერდების რაოდენობას. მეორეც, მონაცემების მოსაპოვებლად ინდექსის გამოყენების სარგებლისგან განსხვავებით, მონაცემების ჩასმა და წაშლა არ იძლევა ასეთ სარგებელს ინდექსის შენარჩუნების აუცილებლობის გამო. რაც უფრო მეტი ინდექსი აქვს ცხრილს, მით მეტი სამუშაოა საჭირო მათი რეორგანიზაციისთვის. როგორც წესი, მიზანშეწონილია აირჩიოთ ინდექსები ხშირი შეკითხვებისთვის და შემდეგ შეაფასოთ მათი გამოყენება.
ინდექსების შექმნისა და გამოყენების ზოგიერთი ინსტრუქცია მოცემულია ამ განყოფილებაში. შემდეგი რეკომენდაციები მხოლოდ ზოგადი წესებია. საბოლოო ჯამში, მათი ეფექტურობა დამოკიდებული იქნება იმაზე, თუ როგორ გამოიყენება მონაცემთა ბაზა პრაქტიკაში და ყველაზე ხშირად შესრულებული მოთხოვნების ტიპზე. სვეტის ინდექსირება, რომელიც არასოდეს იქნება გამოყენებული, არანაირ კარგს არ მოიტანს.
ინდექსები და WHERE პუნქტის პირობები
თუ SELECT განცხადების WHERE პუნქტი შეიცავს საძიებო მდგომარეობას ერთი სვეტით, მაშინ ამ სვეტზე უნდა შეიქმნას ინდექსი. ეს განსაკუთრებით რეკომენდებულია მაღალი სელექციურობის პირობებში. პირობის სელექციურობით ვგულისხმობთ იმ მწკრივების რაოდენობის შეფარდებას, რომლებიც აკმაყოფილებენ პირობას ცხრილის რიგების მთლიან რაოდენობასთან. მაღალი სელექციურობა შეესაბამება ამ თანაფარდობის უფრო დაბალ მნიშვნელობას. ძიების დამუშავება ინდექსირებული სვეტის გამოყენებით ყველაზე წარმატებული იქნება, როდესაც პირობის სელექციურობა 5%-ზე ნაკლებია.
სვეტი არ უნდა იყოს ინდექსირებული, თუ პირობის შერჩევითობის დონე მუდმივია 80% ან მეტი. ამ შემთხვევაში, ინდექსის გვერდებს დასჭირდებათ დამატებითი I/O ოპერაციები, რაც შეამცირებს ინდექსების გამოყენებით მიღწეული დროის ნებისმიერ დანაზოგს. ამ შემთხვევაში, უფრო სწრაფია ძიების შესრულება ცხრილის სკანირებით, რასაც ჩვეულებრივ ირჩევს შეკითხვის ოპტიმიზატორი, რაც ინდექსს უსარგებლო გახდის.
თუ ხშირად გამოყენებული მოთხოვნის საძიებო პირობა შეიცავს AND ოპერატორებს, თქვენი საუკეთესო ვარიანტია შექმნათ რთული ინდექსი ცხრილის ყველა სვეტზე, რომელიც მითითებულია SELECT განცხადების WHERE პუნქტში. ასეთი კომპოზიტური ინდექსის შექმნა ნაჩვენებია ქვემოთ მოცემულ მაგალითში:
ეს მაგალითი ქმნის კომპოზიტურ ინდექსს WHERE პუნქტის ყველა სვეტზე. ამ შეკითხვაში, ორი პირობა არის AND ერთად, ასე რომ თქვენ უნდა შექმნათ რთული არაკლასტერული ინდექსი ორივე სვეტზე ამ პირობებში.
ინდექსები და შეერთების ოპერატორი
შეერთების ოპერაციისთვის, რეკომენდებულია ინდექსის შექმნა თითოეულ შეერთებულ სვეტზე. სვეტები, რომლებიც გაერთიანებულია, ხშირად წარმოადგენს ერთი ცხრილის ძირითად გასაღებს და სხვა ცხრილის შესაბამის უცხოურ გასაღებს. თუ თქვენ მიუთითებთ PRIMARY KEY და FOREIGN KEY მთლიანობის შეზღუდვებს შესაბამის შეერთების სვეტებზე, თქვენ უნდა შექმნათ მხოლოდ არაკლასტერული ინდექსი უცხო გასაღების სვეტზე, რადგან სისტემა ირიბად შექმნის კლასტერულ ინდექსს პირველადი გასაღების სვეტზე.
ქვემოთ მოყვანილი მაგალითი გვიჩვენებს, თუ როგორ უნდა შექმნათ ინდექსები, რომლებიც გამოყენებული იქნებოდა, თუ გქონდათ შეკითხვა შეერთების ოპერაციით და დამატებითი ფილტრით:
დაფარვის ინდექსი
როგორც უკვე აღვნიშნეთ, ინდექსში მოთხოვნის ყველა სვეტის ჩათვლით შეიძლება მნიშვნელოვნად გააუმჯობესოს შეკითხვის შესრულება. ასეთი ინდექსის შექმნა, რომელსაც საფარი ეწოდება, ნაჩვენებია ქვემოთ მოცემულ მაგალითში:
გამოიყენეთ AdventureWorks2012; GO DROP INDEX Person.Address.IX_Address_StateProvinceID; GO CREATE INDEX ix_address_zip ON Person.Address(PostCode) INCLUDE(City, StateProvinceID); GO SELECT City, StateProvinceID FROM Person.Address WHERE PostalCode = 84407;
ეს მაგალითი ჯერ წაშლის IX_Address_StateProvinceID ინდექსს მისამართების ცხრილიდან. შემდეგ იქმნება ახალი ინდექსი, რომელიც მოიცავს ორ დამატებით სვეტს საფოსტო კოდის სვეტის გარდა. და ბოლოს, SELECT განაცხადი მაგალითის ბოლოს აჩვენებს შეკითხვას, რომელიც დაფარულია ინდექსით. ამ მოთხოვნისთვის სისტემას არ სჭირდება მონაცემთა გვერდების მონაცემების ძებნა, რადგან შეკითხვის ოპტიმიზატორს შეუძლია ყველა სვეტის მნიშვნელობის პოვნა არაკლასტერული ინდექსის კვანძის გვერდებზე.
რეკომენდირებულია დაფარვის ინდექსები, რადგან ინდექსის გვერდები ჩვეულებრივ შეიცავს ბევრად მეტ ჩანაწერს, ვიდრე შესაბამისი მონაცემთა გვერდები. გარდა ამისა, ამ მეთოდის გამოსაყენებლად, გაფილტრული სვეტები უნდა იყოს პირველი საკვანძო სვეტები ინდექსში.
ინდექსები გამოთვლილ სვეტებზე
მონაცემთა ბაზის ძრავა საშუალებას გაძლევთ შექმნათ შემდეგი სპეციალური ტიპის ინდექსები:
ინდექსირებული ხედები;
ფილტრირებადი ინდექსები;
ინდექსები გამოთვლილ სვეტებზე;
დანაწევრებული ინდექსები;
სვეტის მდგრადობის ინდექსები;
XML ინდექსები;
სრული ტექსტის ინდექსები.
ეს სექცია განიხილავს გამოთვლილ სვეტებს და მათთან დაკავშირებულ ინდექსებს.
გამოთვლილი სვეტიარის ცხრილის სვეტი, რომელშიც ინახება ცხრილის მონაცემების გამოთვლების შედეგები. ასეთი სვეტი შეიძლება იყოს ვირტუალური ან მუდმივი. ამ ორი ტიპის სვეტები განიხილება შემდეგ ქვეთავებში.
ვირტუალური გამოთვლილი სვეტები
გამოთვლილი სვეტი, რომელსაც არ აქვს შესაბამისი კლასტერული ინდექსი, არის ლოგიკური სვეტი, ე.ი. ის ფიზიკურად არ ინახება მყარ დისკზე. ამრიგად, ის ფასდება ყოველ ჯერზე, როცა სტრიქონს წვდება. ვირტუალური გამოთვლილი სვეტების გამოყენება ნაჩვენებია ქვემოთ მოცემულ მაგალითში:
გამოიყენეთ SampleDb; CREATE TABLE შეკვეთები (OrderId INT NOT NULL, Price MONEY NOT NULL, რაოდენობა INT NOT NULL, OrderDate DATETIME NOT NULL, სულ ფასი * რაოდენობა, გაგზავნილი თარიღი DATEADD (დღე, 7, შეკვეთის თარიღი));
ამ მაგალითში შეკვეთების ცხრილს აქვს ორი ვირტუალური გამოთვლილი სვეტი: ჯამი და გაგზავნის თარიღი. მთლიანი სვეტი გამოითვლება ორი სხვა სვეტის, ფასისა და რაოდენობის გამოყენებით, ხოლო გაგზავნის თარიღის სვეტი გამოითვლება DATEADD ფუნქციისა და შეკვეთის თარიღის სვეტის გამოყენებით.
მუდმივი გამოთვლილი სვეტები
მონაცემთა ბაზის ძრავა საშუალებას გაძლევთ შექმნათ ინდექსები დეტერმინისტულ გამოთვლილ სვეტებზე, სადაც ქვემოთ მოცემულ სვეტებს აქვთ მონაცემთა ზუსტი ტიპები. (გამოთვლილი სვეტი განმსაზღვრელია, თუ ის ყოველთვის აბრუნებს იგივე მნიშვნელობებს იმავე ცხრილის მონაცემებისთვის.)
ინდექსირებული გამოთვლილი სვეტის შექმნა შესაძლებელია მხოლოდ იმ შემთხვევაში, თუ SET განცხადების შემდეგი პარამეტრები დაყენებულია ON-ზე (ეს პარამეტრები უზრუნველყოფს სვეტის განმსაზღვრელობას):
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
გარდა ამისა, NUMERIC_ROUNDABORT პარამეტრი უნდა იყოს გამორთული.
თუ შექმნით კლასტერულ ინდექსს გამოთვლილ სვეტზე, სვეტის მნიშვნელობები ფიზიკურად იარსებებს ცხრილის შესაბამის სტრიქონებში, რადგან დაჯგუფებული ინდექსის კვანძის გვერდები შეიცავს მონაცემთა რიგებს. შემდეგი მაგალითი ქმნის კლასტერულ ინდექსს შეკვეთების ცხრილიდან გამოთვლილ სვეტზე:
გამოიყენეთ SampleDb; შეკვეთების დაჯგუფების ix1 ინდექსის შექმნა (სულ);
CREATE INDEX განაცხადის შესრულების შემდეგ, გამოთვლილი ჯამური სვეტი ფიზიკურად იქნება წარმოდგენილი ცხრილში. ეს ნიშნავს, რომ გამოთვლილი სვეტის ძირითადი სვეტების ყველა განახლება გამოიწვევს მის განახლებას.
სვეტი შეიძლება იყოს მუდმივი სხვა გზით გამოყენებით PERSISTED პარამეტრი. ეს პარამეტრი საშუალებას გაძლევთ მიუთითოთ გამოთვლილი სვეტის ფიზიკური არსებობა შესაბამისი კლასტერული ინდექსის შექმნის გარეშეც კი. ეს შესაძლებლობა საჭიროა ფიზიკური გამოთვლილი სვეტების შესაქმნელად, რომლებიც იქმნება მიახლოებითი მონაცემების ტიპის სვეტებზე (float ან real). (როგორც უკვე აღვნიშნეთ, ინდექსი შეიძლება შეიქმნას მხოლოდ გამოთვლილ სვეტზე, თუ მისი ძირითადი სვეტები ზუსტი მონაცემების ტიპისაა.)
ეს მასალა განიხილავს მონაცემთა ბაზის ასეთ ობიექტებს Microsoft SQL სერვერიᲠოგორ ინდექსებითქვენ შეისწავლით რა არის ინდექსები, რა ტიპის ინდექსები არსებობს, როგორ შექმნათ, ოპტიმიზაცია და წაშალოთ ისინი.
რა არის ინდექსები მონაცემთა ბაზაში?
ინდექსიარის მონაცემთა ბაზის ობიექტი, რომელიც წარმოადგენს მონაცემთა სტრუქტურას, რომელიც შედგება კლავიშებისგან, რომლებიც აგებულია ცხრილის ან ხედის ერთი ან მეტი სვეტისგან და მაჩვენებლებისაგან, რომლებიც ასახავს იმ ადგილს, სადაც მითითებულია მონაცემები ინახება. ინდექსები შექმნილია ცხრილიდან მწკრივების უფრო სწრაფად ამოსაღებად; სხვა სიტყვებით რომ ვთქვათ, ინდექსები იძლევა ცხრილის მონაცემების სწრაფ ძიებას, რაც მნიშვნელოვნად აუმჯობესებს მოთხოვნისა და აპლიკაციის შესრულებას. ინდექსები ასევე შეიძლება გამოყენებულ იქნას ცხრილის სტრიქონების უნიკალურობის უზრუნველსაყოფად, რაც უზრუნველყოფს მონაცემთა მთლიანობას.
ინდექსების ტიპები Microsoft SQL Server-ში
შემდეგი ტიპის ინდექსები არსებობს Microsoft SQL Server-ში:
- კლასტერული (კლასტერული) არის ინდექსი, რომელიც ინახავს ცხრილის მონაცემებს, რომლებიც დალაგებულია ინდექსის გასაღების მნიშვნელობით. ცხრილს შეიძლება ჰქონდეს მხოლოდ ერთი კლასტერული ინდექსი, რადგან მონაცემთა დახარისხება შესაძლებელია მხოლოდ ერთი თანმიმდევრობით. თუ შესაძლებელია, თითოეულ ცხრილს უნდა ჰქონდეს კლასტერული ინდექსი; თუ ცხრილს არ აქვს კლასტერული ინდექსი, ცხრილს ეწოდება " თაიგულში" კლასტერული ინდექსი იქმნება ავტომატურად, როდესაც შექმნით PRIMARY KEY შეზღუდვებს ( მთავარი გასაღები) და UNIQUE, თუ მაგიდაზე კლასტერული ინდექსი ჯერ არ არის განსაზღვრული. თუ თქვენ შექმნით კლასტერულ ინდექსს მაგიდაზე ( გროვა) რომელიც შეიცავს არაკლასტერულ ინდექსებს, მაშინ ყველა მათგანი უნდა აღდგეს შექმნის შემდეგ.
- არაკლასტერული (არაკლასტერული) არის ინდექსი, რომელიც შეიცავს გასაღების მნიშვნელობას და მაჩვენებელს მონაცემთა მწკრივისკენ, რომელიც შეიცავს ამ გასაღების მნიშვნელობას. ცხრილს შეიძლება ჰქონდეს მრავალი არაკლასტერული ინდექსი. არაკლასტერული ინდექსები შეიძლება შეიქმნას ცხრილებზე კლასტერული ინდექსით ან მის გარეშე. სწორედ ამ ტიპის ინდექსი გამოიყენება ხშირად გამოყენებული მოთხოვნების შესრულების გასაუმჯობესებლად, ვინაიდან არაკლასტერული ინდექსები უზრუნველყოფს სწრაფ ძიებას და მონაცემებზე წვდომას საკვანძო მნიშვნელობებით;
- ფილტრირებადი (გაფილტრული) არის ოპტიმიზებული არაკლასტერული ინდექსი, რომელიც იყენებს ფილტრის პრედიკატს ცხრილის სტრიქონების ქვეჯგუფის ინდექსირებისთვის. თუ კარგად არის შემუშავებული, ამ ტიპის ინდექსს შეუძლია გააუმჯობესოს მოთხოვნის შესრულება და ასევე შეამციროს ინდექსის შენარჩუნებისა და შენახვის ხარჯები სრული ცხრილის ინდექსებთან შედარებით;
- უნიკალური (უნიკალური) არის ინდექსი, რომელიც უზრუნველყოფს დუბლიკატების არარსებობას ( იდენტური) ინდექსის გასაღების მნიშვნელობები, რითაც გარანტირებულია ამ გასაღებისთვის რიგების უნიკალურობა. ორივე კლასტერული და არაკლასტერული ინდექსები შეიძლება იყოს უნიკალური. თუ თქვენ შექმნით უნიკალურ ინდექსს მრავალ სვეტზე, ინდექსი უზრუნველყოფს, რომ გასაღების მნიშვნელობების თითოეული კომბინაცია უნიკალურია. როდესაც თქვენ ქმნით PRIMARY KEY ან UNIQUE შეზღუდვებს, SQL სერვერი ავტომატურად ქმნის უნიკალურ ინდექსს გასაღების სვეტებზე. უნიკალური ინდექსის შექმნა შესაძლებელია მხოლოდ იმ შემთხვევაში, თუ ცხრილს ამჟამად არ აქვს დუბლიკატი მნიშვნელობები საკვანძო სვეტებში;
- სვეტიანი (Columnstore) არის ინდექსი, რომელიც დაფუძნებულია მონაცემთა შენახვის ტექნოლოგიაზე. ამ ტიპის ინდექსი ეფექტურია დიდი მონაცემთა საწყობებისთვის, რადგან მას შეუძლია გაზარდოს მოთხოვნების შესრულება საწყობში 10-ჯერ და ასევე შეამციროს მონაცემთა ზომა 10-ჯერ, რადგან Columnstore ინდექსში მონაცემები შეკუმშულია. არსებობს როგორც კლასტერული სვეტების ინდექსები, ასევე არაკლასტერული;
- Მთლიანი ტექსტი (Მთლიანი ტექსტი) არის სპეციალური ტიპის ინდექსი, რომელიც უზრუნველყოფს ეფექტურ მხარდაჭერას რთული სიტყვების ძიებაში სიმბოლოების სტრიქონების მონაცემებზე. სრული ტექსტის ინდექსის შექმნისა და შენარჩუნების პროცესს ეწოდება " შევსება" არსებობს შევსების ისეთი სახეობები, როგორიცაა: სრული შევსება და შევსება ცვლილებების თვალთვალის საფუძველზე. ნაგულისხმევად, SQL Server სრულად ავსებს ახალ სრული ტექსტის ინდექსს მისი შექმნისთანავე, მაგრამ ამას შეიძლება დასჭირდეს რესურსების მნიშვნელოვანი რაოდენობა, რაც დამოკიდებულია ცხრილის ზომაზე, ამიტომ შესაძლებელია სრული პოპულაციის გადადება. ცვლილებების თვალყურის დევნებაზე დაფუძნებული დათესვა გამოიყენება სრული ტექსტის ინდექსის შესანარჩუნებლად მას შემდეგ, რაც ის თავდაპირველად სრულად იქნება დასახლებული;
- სივრცითი (სივრცითი) არის ინდექსი, რომელიც საშუალებას გაძლევთ უფრო ეფექტურად გამოიყენოთ კონკრეტული ოპერაციები სივრცულ ობიექტებზე გეომეტრიის ან გეოგრაფიის მონაცემთა ტიპის სვეტებში. ამ ტიპის ინდექსი შეიძლება შეიქმნას მხოლოდ სივრცულ სვეტზე, ხოლო ცხრილი, რომელზეც არის განსაზღვრული სივრცითი ინდექსი, უნდა შეიცავდეს პირველადი გასაღების ( ᲛᲗᲐᲕᲐᲠᲘ ᲒᲐᲡᲐᲦᲔᲑᲘ);
- XMLარის კიდევ ერთი სპეციალური ტიპის ინდექსი, რომელიც განკუთვნილია XML მონაცემთა ტიპის სვეტებისთვის. XML ინდექსი აუმჯობესებს მოთხოვნების დამუშავების ეფექტურობას XML სვეტების მიმართ. არსებობს XML ინდექსის ორი ტიპი: პირველადი და მეორადი. პირველადი XML ინდექსი ახდენს XML სვეტში შენახულ ყველა ტეგს, მნიშვნელობას და ბილიკს. მისი შექმნა შესაძლებელია მხოლოდ იმ შემთხვევაში, თუ ცხრილს აქვს კლასტერული ინდექსი პირველად გასაღებზე. მეორადი XML ინდექსი შეიძლება შეიქმნას მხოლოდ იმ შემთხვევაში, თუ ცხრილს აქვს პირველადი XML ინდექსი და ის გამოიყენება მოთხოვნების შესრულების გასაუმჯობესებლად XML სვეტზე წვდომის გარკვეულ ტიპზე, ამასთან დაკავშირებით არსებობს მეორადი ინდექსების რამდენიმე ტიპი: PATH. , ღირებულება და საკუთრება;
- ასევე არსებობს სპეციალური ინდექსები მეხსიერების ოპტიმიზებული ცხრილებისთვის ( მეხსიერების OLTP) როგორიცაა: ჰაში ( ჰაში) მეხსიერების ოპტიმიზებული ინდექსები და არაკლასტერული ინდექსები, რომლებიც იქმნება დიაპაზონის სკანირებისთვის და შეკვეთილი სკანირებისთვის.
ინდექსების შექმნა და წაშლა Microsoft SQL Server-ში
სანამ ინდექსის შექმნას დაიწყებთ, აუცილებელია მისი კარგად დაპროექტება, რათა ინდექსი ეფექტურად გამოიყენოთ, რადგან ცუდად შემუშავებულმა ინდექსებმა შეიძლება არ გააუმჯობესოს შესრულება, არამედ შეამციროს იგი. მაგალითად, მაგიდაზე ინდექსების დიდი რაოდენობა ამცირებს INSERT, UPDATE, DELETE და MERGE განცხადებების შესრულებას, რადგან როდესაც ცხრილში მონაცემები იცვლება, ყველა ინდექსი შესაბამისად უნდა განახლდეს. ჩვენ განვიხილავთ ზოგად რეკომენდაციებს ინდექსების დიზაინის შესახებ ცალკე სტატიაში, მაგრამ ახლა მოდით პირდაპირ გადავიდეთ ინდექსების შექმნისა და წაშლის პროცესის შესწავლაზე.
Შენიშვნა! ჩემი SQL სერვერი არის Microsoft SQL Server 2016 Express.
ინდექსების შექმნა
Microsoft SQL Server-ში ინდექსების შექმნის ორი გზა არსებობს: პირველი არის SQL Server Management Studio (SSMS) გარემოს გრაფიკული ინტერფეისის გამოყენება, ხოლო მეორე Transact-SQL ენის გამოყენებით, ჩვენ გავაანალიზებთ ორივე მეთოდს.
წყაროს მონაცემები მაგალითებისთვის
წარმოვიდგინოთ, რომ გვაქვს პროდუქტის ცხრილი სახელწოდებით TestTable, რომელსაც აქვს სამი სვეტი:
- ProductId – პროდუქტის იდენტიფიკატორი;
- ProductName – პროდუქტის სახელი;
- CategoryID – პროდუქტის კატეგორია.
კლასტერული ინდექსის შექმნის მაგალითი
როგორც უკვე ვთქვი, კლასტერული ინდექსი იქმნება ავტომატურად, თუ, მაგალითად, ცხრილის შექმნისას, ძირითად გასაღებად მივუთითებთ კონკრეტულ სვეტს ( ᲛᲗᲐᲕᲐᲠᲘ ᲒᲐᲡᲐᲦᲔᲑᲘ), მაგრამ რადგან ჩვენ ეს არ გაგვიკეთებია, მოდით შევხედოთ კლასტერული ინდექსის შექმნის მაგალითს თავად.
კლასტერული ინდექსის შესაქმნელად შეგვიძლია მაგიდის პირველადი გასაღები მივუთითოთ და ამით კლასტერული ინდექსი ავტომატურად შეიქმნება, ან ცალკე შევქმნათ კლასტერული ინდექსი.
მაგალითად, მოდით შევქმნათ კლასტერული ინდექსი პირველადი გასაღების შექმნის გარეშე. პირველ რიგში ამას გავაკეთებთ მენეჯმენტის სტუდიის გამოყენებით.
გახსენით SSMS და იპოვნეთ სასურველი ცხრილი ობიექტის ბრაუზერში და დააწკაპუნეთ მაუსის მარჯვენა ღილაკით ". ინდექსები", აირჩიეთ" შექმენით ინდექსი"და ინდექსის ტიპი, ჩვენს შემთხვევაში" კლასტერული».

Ფორმა " ახალი ინდექსი", სადაც უნდა მივუთითოთ ახალი ინდექსის სახელი ( ის უნდა იყოს უნიკალური ცხრილის შიგნით), ჩვენ ასევე მივუთითებთ, იქნება თუ არა ეს ინდექსი უნიკალური; თუ ვსაუბრობთ პროდუქტის იდენტიფიკატორზე პროდუქტის ცხრილში, მაშინ, რა თქმა უნდა, ის უნიკალური უნდა იყოს. შემდეგ აირჩიეთ სვეტი ( ინდექსის გასაღები), რომლის საფუძველზეც შევქმნით კლასტერულ ინდექსს, ე.ი. ცხრილში მონაცემთა რიგები დალაგდება " დამატება».

ყველა საჭირო პარამეტრის შეყვანის შემდეგ დააჭირეთ ღილაკს " კარგი“, საბოლოოდ შეიქმნება კლასტერული ინდექსი.

ანალოგიურად, შეიძლება შეიქმნას კლასტერული ინდექსი T-SQL განცხადების გამოყენებით არსების ინდექსიმაგალითად, ასე
შექმენით უნიკალური ჯგუფური ინდექსი IX_Clustered ON TestTable (ProductId ASC) GO
ან, როგორც უკვე ვთქვით, ჩვენ ასევე შეგვიძლია გამოვიყენოთ განცხადება პირველადი გასაღების შესაქმნელად, მაგალითად
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) GO
არაკლასტერული ინდექსის შექმნის მაგალითი ჩართული სვეტებით
ახლა შევხედოთ არაკლასტერული ინდექსის შექმნის მაგალითს, რომელშიც მივუთითებთ სვეტებს, რომლებიც არ იქნება გასაღები, მაგრამ ჩაირთვება ინდექსში. ეს სასარგებლოა იმ შემთხვევებში, როდესაც თქვენ ქმნით ინდექსს კონკრეტული მოთხოვნისთვის, მაგალითად, ისე, რომ ინდექსი მთლიანად ფარავს მოთხოვნას, ე.ი. შეიცავდა ყველა სვეტს ( ამას ჰქვია "მოთხოვნის დაფარვა"). შეკითხვის დაფარვა აუმჯობესებს შესრულებას, რადგან შეკითხვის ოპტიმიზატორს შეუძლია იპოვნოს ყველა სვეტის მნიშვნელობა ინდექსში ცხრილის მონაცემებზე წვდომის გარეშე, რაც გამოიწვევს დისკის I/O ოპერაციების ნაკლებობას. მაგრამ გახსოვდეთ, რომ ინდექსში არასაკვანძო სვეტების ჩართვა იწვევს ინდექსის ზომის ზრდას, ე.ი. ინდექსის შესანახად საჭიროა მეტი ადგილი დისკზე და ასევე შეიძლება გამოიწვიოს საბაზისო ცხრილზე INSERT, UPDATE, DELETE და MERGE ოპერაციების შესრულების შემცირება.
იმისათვის, რომ შევქმნათ არაკლასტერული ინდექსი Management Studio GUI-ს გამოყენებით, ჩვენ ასევე ვპოულობთ სასურველ ცხრილს და ინდექსების პუნქტს, მხოლოდ ამ შემთხვევაში ვირჩევთ ” შექმნა -> არაკლასტერული ინდექსი».

ფორმის გახსნის შემდეგ " ახალი ინდექსი"ჩვენ ვაზუსტებთ ინდექსის სახელს, ვამატებთ საკვანძო სვეტს ან სვეტებს ღილაკის გამოყენებით" დამატება", მაგალითად, ჩვენი სატესტო შემთხვევისთვის, მოდით დავაკონკრეტოთ CategoryID.


Transact-SQL-ში ასე გამოიყურება.
CREATE NONCLUSTERED INDEX IX_NonClustered ON TestTable (CategoryID ASC) INCLUDE (ProductName) GO
Microsoft SQL Server-ში ინდექსის წაშლის მაგალითი
ინდექსის წასაშლელად შეგიძლიათ დააწკაპუნოთ სასურველ ინდექსზე მაუსის მარჯვენა ღილაკით და დააწკაპუნოთ “ წაშლა", შემდეგ დაადასტურეთ თქვენი ქმედებები დაწკაპუნებით" კარგი».

ან ასევე შეგიძლიათ გამოიყენოთ ინსტრუქციები ვარდნის ინდექსი, Მაგალითად
DROP INDEX IX_NonClustered ON TestTable
უნდა აღინიშნოს, რომ DROP INDEX განცხადება არ ვრცელდება ინდექსებზე, რომლებიც შეიქმნა PRIMARY KEY და UNIQUE შეზღუდვების შექმნით. ამ შემთხვევაში, ინდექსის ჩამოსაშლელად, თქვენ უნდა გამოიყენოთ ALTER TABLE განცხადება DROP CONSTRAINT პუნქტით.
ინდექსების ოპტიმიზაცია Microsoft SQL Server-ში
SQL ცხრილებში მონაცემების განახლების, დამატების ან წაშლის შედეგად სერვერი ავტომატურად ახორციელებს შესაბამის ცვლილებებს ინდექსებში, მაგრამ დროთა განმავლობაში ყველა ამ ცვლილებამ შეიძლება გამოიწვიოს ინდექსში მონაცემების ფრაგმენტაცია, ე.ი. ისინი აღმოჩნდებიან მიმოფანტული მონაცემთა ბაზაში. ინდექსების ფრაგმენტაცია იწვევს მოთხოვნის შესრულების შემცირებას, ამიტომ პერიოდულად საჭიროა ინდექსის შენარჩუნების ოპერაციების შესრულება, კერძოდ, დეფრაგმენტაცია, როგორიცაა ინდექსის რეორგანიზაცია და აღდგენის ოპერაციები.
როდის გამოვიყენოთ ინდექსის რეორგანიზაცია და როდის აღვადგინოთ?
ამ კითხვაზე პასუხის გასაცემად, ჯერ უნდა დაადგინოთ ინდექსის ფრაგმენტაციის ხარისხი, რადგან ინდექსის ფრაგმენტაციის მიხედვით, სასურველი და ეფექტური იქნება დეფრაგმენტაციის ერთი ან სხვა მეთოდი. თქვენ შეგიძლიათ გამოიყენოთ სისტემის ცხრილის ფუნქცია ინდექსის ფრაგმენტაციის ხარისხის დასადგენად sys.dm_db_index_physical_stats, რომელიც აბრუნებს დეტალურ ინფორმაციას ინდექსების ზომისა და ფრაგმენტაციის შესახებ. მაგალითად, შემდეგი შეკითხვის გამოყენებით, შეგიძლიათ გაიგოთ ინდექსის ფრაგმენტაციის ხარისხი მიმდინარე მონაცემთა ბაზის ყველა ცხრილისთვის.
SELECT OBJECT_NAME(T1.object_id) AS NameTable, T1.index_id AS IndexId, T2.name AS IndexName, T1.avg_fragmentation_in_percent AS ფრაგმენტაცია FROM sys.dm_db_index_physical_stats (,NULL_ID) T JoIN sys. ინდექსები AS T2 ON T1.object_id = T2.object_id და T1.index_id = T2.index_id
ამ შემთხვევაში ჩვენ გვაინტერესებს სვეტი საშუალო_ფრაგმენტაცია_პროცენტში, ე.ი. ლოგიკური ფრაგმენტაციის პროცენტი.
- თუ ფრაგმენტაციის ხარისხი 5%-ზე ნაკლებია, მაშინ ინდექსის რეორგანიზაცია ან აღდგენა საერთოდ არ უნდა დაიწყოს;
- თუ ფრაგმენტაციის ხარისხი არის 5-დან 30% -მდე, მაშინ აზრი აქვს ინდექსის რეორგანიზაციის დაწყებას, რადგან ეს ოპერაცია იყენებს მინიმალურ სისტემის რესურსებს და არ საჭიროებს გრძელვადიან ჩაკეტვას;
- თუ ფრაგმენტაციის ხარისხი 30% -ზე მეტია, მაშინ აუცილებელია ინდექსის ხელახლა აშენება, რადგან ეს ოპერაცია, მნიშვნელოვანი ფრაგმენტაცია, უფრო დიდ ეფექტს იძლევა, ვიდრე ინდექსის რეორგანიზაციის ოპერაცია.
პირადად მე შემიძლია დავამატო შემდეგი, თუ თქვენ გაქვთ პატარა კომპანია და მონაცემთა ბაზა არ საჭიროებს მაქსიმალურ გამომუშავებას 24 საათის განმავლობაში, ე.ი. ვინაიდან ეს არ არის სუპერ აქტიური მონაცემთა ბაზა, შეგიძლიათ უსაფრთხოდ პერიოდულად შეასრულოთ ინდექსების აღდგენის ოპერაცია, ფრაგმენტაციის ხარისხის განსაზღვრის გარეშეც კი.
ინდექსების რეორგანიზაცია
ინდექსის რეორგანიზაციაარის ინდექსის დეფრაგმენტაციის პროცესი, რომელიც დეფრაგმენტირებს ფოთლის დონის კლასტერულ და არაკლასტერულ ინდექსებს ცხრილებსა და ხედებზე, ფოთლის დონის გვერდების ფიზიკური გადალაგება ლოგიკური თანმიმდევრობის მიხედვით ( მარცხნიდან მარჯვნივ) ბოლო კვანძები.
ინდექსის რეორგანიზაციისთვის შეგიძლიათ გამოიყენოთ SSMS გრაფიკული ინსტრუმენტი ან Transact-SQL განცხადება.
ინდექსის რეორგანიზაცია მართვის სტუდიის გამოყენებით

ინდექსის რეორგანიზაცია Transact-SQL-ის გამოყენებით
ALTER INDEX IX_NonClustered სატესტო მაგიდაზე REORGANIZE GO
ინდექსების აღდგენა
ინდექსის აღდგენაეს არის პროცესი, რომელიც შლის ძველ ინდექსს და ქმნის ახალს, რითაც აღმოფხვრის ფრაგმენტაციას.
ინდექსების აღდგენისთვის შეგიძლიათ გამოიყენოთ ორი მეთოდი.
Პირველი. ALTER INDEX განაცხადის გამოყენება REBUILD პუნქტით. ეს განცხადება ცვლის DBCC DBREINDEX განცხადებას. როგორც წესი, ეს არის მეთოდი, რომელიც გამოიყენება ინდექსების მასობრივად აღდგენისთვის.
მაგალითი
ALTER INDEX IX_NonClustered ON TestTable REBUILD GO
და მეორე, CREATE INDEX განაცხადის გამოყენებით DROP_EXISTING პუნქტით. შეიძლება გამოყენებულ იქნას, მაგალითად, ინდექსის აღდგენისთვის მისი განმარტების შეცვლით, ე.ი. საკვანძო სვეტების დამატება ან წაშლა.
მაგალითი
CREATE NONCLUSTERED INDEX IX_NonClustered ON TestTable (CategoryID ASC) WITH (DROP_EXISTING = ON) GO
Rebuild ფუნქცია ასევე ხელმისაწვდომია Management Studio-ში. დააწკაპუნეთ მარჯვენა ღილაკით სასურველ ინდექსზე " ხელახლა აშენება».

ამით დასრულდა მასალა Microsoft SQL Server-ში ინდექსების საფუძვლების შესახებ. თუ გაინტერესებთ T-SQL ენა, გირჩევთ წაიკითხოთ ჩემი წიგნი "
ერთ-ერთი ყველაზე მნიშვნელოვანი გზა მაღალი პროდუქტიულობის მისაღწევად SQL სერვერიარის ინდექსების გამოყენება. ინდექსი აჩქარებს შეკითხვის პროცესს ცხრილის მონაცემების მწკრივებზე სწრაფი წვდომით, ისევე როგორც წიგნის ინდექსი დაგეხმარებათ სწრაფად იპოვოთ თქვენთვის საჭირო ინფორმაცია. ამ სტატიაში მე მივცემ მოკლე მიმოხილვას ინდექსების შესახებ SQL სერვერიდა აუხსენით, როგორ არის ორგანიზებული ისინი მონაცემთა ბაზაში და როგორ უწყობს ხელს მონაცემთა ბაზის მოთხოვნების დაჩქარებას.ინდექსები იქმნება ცხრილისა და ხედვის სვეტებზე. ინდექსები იძლევა საშუალებას სწრაფად მოძებნოთ მონაცემები ამ სვეტების მნიშვნელობებზე დაყრდნობით. მაგალითად, თუ შექმნით ინდექსს პირველად გასაღებზე და შემდეგ მოძებნით მონაცემთა რიგს პირველადი გასაღების მნიშვნელობების გამოყენებით, მაშინ SQL სერვერიჯერ იპოვის ინდექსის მნიშვნელობას და შემდეგ გამოიყენებს ინდექსს მონაცემთა მთელი რიგის სწრაფად მოსაძებნად. ინდექსის გარეშე, შესრულდება ცხრილის ყველა მწკრივის სრული სკანირება, რამაც შეიძლება მნიშვნელოვანი გავლენა მოახდინოს შესრულებაზე.
თქვენ შეგიძლიათ შექმნათ ინდექსი ცხრილის ან ხედის უმეტეს სვეტებზე. გამონაკლისი არის ძირითადად სვეტები მონაცემთა ტიპებით დიდი ობიექტების შესანახად ( ლობი), როგორიცაა გამოსახულება, ტექსტიან ვარჩარი (მაქს). თქვენ ასევე შეგიძლიათ შექმნათ ინდექსები სვეტებზე, რომლებიც შექმნილია მონაცემების ფორმატში შესანახად XML, მაგრამ ეს ინდექსები ოდნავ განსხვავებულად არის სტრუქტურირებული, ვიდრე სტანდარტული და მათი განხილვა სცილდება ამ სტატიის ფარგლებს. ასევე, სტატიაში არ არის საუბარი სვეტების მაღაზიაინდექსები. ამის ნაცვლად, მე ყურადღებას ვამახვილებ იმ ინდექსებზე, რომლებიც ყველაზე ხშირად გამოიყენება მონაცემთა ბაზებში SQL სერვერი.
ინდექსი შედგება გვერდების ნაკრებისგან, ინდექსის კვანძებისგან, რომლებიც ორგანიზებულია ხის სტრუქტურაში - დაბალანსებული ხე. ეს სტრუქტურა იერარქიული ხასიათისაა და იწყება ფესვის კვანძით იერარქიის ზედა ნაწილში და ფოთლის კვანძებით, ფოთლებით, ბოლოში, როგორც ნაჩვენებია სურათზე: 
როდესაც თქვენ კითხულობთ ინდექსირებულ სვეტს, შეკითხვის ძრავა იწყება ძირეული კვანძის ზედა ნაწილში და მიდის ქვემოთ შუალედური კვანძების გავლით, თითოეული შუალედური ფენა შეიცავს უფრო დეტალურ ინფორმაციას მონაცემთა შესახებ. შეკითხვის ძრავა აგრძელებს მოძრაობას ინდექსის კვანძებში, სანამ არ მიაღწევს ქვედა დონეს ინდექსის ფოთლებით. მაგალითად, თუ თქვენ ეძებთ მნიშვნელობას 123 ინდექსირებულ სვეტში, შეკითხვის ძრავა პირველ რიგში განსაზღვრავს გვერდს პირველ შუალედურ დონეზე root დონეზე. ამ შემთხვევაში, პირველი გვერდი მიუთითებს მნიშვნელობაზე 1-დან 100-მდე, ხოლო მეორე 101-დან 200-მდე, ასე რომ შეკითხვის ძრავა მიიღებს წვდომას ამ შუალედური დონის მეორე გვერდზე. შემდეგ ნახავთ, რომ უნდა გადახვიდეთ შემდეგი საშუალო დონის მესამე გვერდზე. აქედან, შეკითხვის ქვესისტემა წაიკითხავს თავად ინდექსის მნიშვნელობას ქვედა დონეზე. ინდექსის ფურცლები შეიძლება შეიცავდეს ან თავად ცხრილის მონაცემებს ან უბრალოდ მაჩვენებელს ცხრილის მონაცემებით მწკრივებზე, რაც დამოკიდებულია ინდექსის ტიპზე: კლასტერული ინდექსი ან არაკლასტერული ინდექსი.
კლასტერული ინდექსი
კლასტერული ინდექსი ინახავს მონაცემების რეალურ რიგებს ინდექსის ფოთლებში. წინა მაგალითს რომ დავუბრუნდეთ, ეს ნიშნავს, რომ 123-ის საკვანძო მნიშვნელობასთან დაკავშირებული მონაცემთა რიგი შეინახება თავად ინდექსში. კლასტერული ინდექსის მნიშვნელოვანი მახასიათებელია ის, რომ ყველა მნიშვნელობა დალაგებულია კონკრეტული თანმიმდევრობით, აღმავალი ან დაღმავალი. ამიტომ, ცხრილს ან ხედს შეიძლება ჰქონდეს მხოლოდ ერთი კლასტერული ინდექსი. გარდა ამისა, უნდა აღინიშნოს, რომ ცხრილში მონაცემები ინახება დახარისხებული სახით მხოლოდ იმ შემთხვევაში, თუ ამ ცხრილში შეიქმნა კლასტერული ინდექსი.ცხრილს, რომელსაც არ აქვს კლასტერული ინდექსი, ეწოდება გროვა.
არაკლასტერული ინდექსი
კლასტერული ინდექსისგან განსხვავებით, არაკლასტერული ინდექსის ფოთლები შეიცავს მხოლოდ იმ სვეტებს ( გასაღები) რომლითაც განისაზღვრება ეს ინდექსი და ასევე შეიცავს ცხრილის რეალური მონაცემების მქონე რიგების მაჩვენებელს. ეს ნიშნავს, რომ ქვემოკითხვის სისტემა მოითხოვს დამატებით ოპერაციას საჭირო მონაცემების მოსაძებნად და მოსაპოვებლად. მონაცემთა მაჩვენებლის შინაარსი დამოკიდებულია იმაზე, თუ როგორ ინახება მონაცემები: კლასტერული ცხრილი ან გროვა. თუ მაჩვენებელი მიუთითებს კლასტერულ ცხრილზე, ის მიუთითებს კლასტერულ ინდექსზე, რომელიც შეიძლება გამოყენებულ იქნას ფაქტობრივი მონაცემების მოსაძებნად. თუ მაჩვენებელი ეხება გროვას, მაშინ ის მიუთითებს მონაცემთა მწკრივის კონკრეტულ იდენტიფიკატორზე. არაკლასტერული ინდექსების დალაგება შეუძლებელია როგორც კლასტერული ინდექსები, მაგრამ შეგიძლიათ შექმნათ ერთზე მეტი არაკლასტერული ინდექსი მაგიდაზე ან ხედზე, 999-მდე. ეს არ ნიშნავს იმას, რომ თქვენ უნდა შექმნათ რაც შეიძლება მეტი ინდექსი. ინდექსებს შეუძლიათ გააუმჯობესონ ან შეამცირონ სისტემის მუშაობა. გარდა იმისა, რომ შეგიძლიათ შექმნათ მრავალი არაკლასტერული ინდექსი, თქვენ ასევე შეგიძლიათ შეიტანოთ დამატებითი სვეტები ( ჩართული სვეტი) მის ინდექსში: ინდექსის ფოთლები შეინახავს არა მხოლოდ თავად ინდექსირებული სვეტების მნიშვნელობას, არამედ ამ არაინდექსირებული დამატებითი სვეტების მნიშვნელობებს. ეს მიდგომა საშუალებას მოგცემთ გადალახოთ ინდექსზე დაყენებული ზოგიერთი შეზღუდვა. მაგალითად, შეგიძლიათ ჩართოთ არაინდექსირებადი სვეტი ან გვერდის ავლით ინდექსის სიგრძის ლიმიტი (900 ბაიტი უმეტეს შემთხვევაში).ინდექსების სახეები
გარდა იმისა, რომ არის კლასტერული ან არაკლასტერული ინდექსი, ის შეიძლება შემდგომ კონფიგურირებული იყოს როგორც კომპოზიტური ინდექსი, უნიკალური ინდექსი ან დაფარვის ინდექსი.კომპოზიტური ინდექსი
ასეთი ინდექსი შეიძლება შეიცავდეს ერთზე მეტ სვეტს. შეგიძლიათ ინდექსში შეიტანოთ 16-მდე სვეტი, მაგრამ მათი საერთო სიგრძე შემოიფარგლება 900 ბაიტით. როგორც კლასტერული, ასევე არაკლასტერული ინდექსები შეიძლება იყოს კომპოზიტური.უნიკალური ინდექსი
ეს ინდექსი უზრუნველყოფს, რომ ინდექსირებული სვეტის თითოეული მნიშვნელობა უნიკალურია. თუ ინდექსი კომპოზიტურია, მაშინ უნიკალურობა ვრცელდება ინდექსის ყველა სვეტზე, მაგრამ არა თითოეულ ცალკეულ სვეტზე. მაგალითად, თუ შექმნით უნიკალურ ინდექსს სვეტებზე NAMEდა გვარი, მაშინ სრული სახელი უნდა იყოს უნიკალური, მაგრამ შესაძლებელია სახელის ან გვარის დუბლიკატი.უნიკალური ინდექსი ავტომატურად იქმნება, როდესაც თქვენ განსაზღვრავთ სვეტის შეზღუდვას: პირველადი გასაღები ან უნიკალური მნიშვნელობის შეზღუდვა:
- Მთავარი გასაღები
როდესაც თქვენ განსაზღვრავთ ძირითადი გასაღების შეზღუდვას ერთ ან მეტ სვეტზე, მაშინ SQL სერვერიავტომატურად ქმნის უნიკალურ კლასტერულ ინდექსს, თუ ადრე არ იყო შექმნილი კლასტერული ინდექსი (ამ შემთხვევაში, პირველადი გასაღებით იქმნება უნიკალური არაკლასტერული ინდექსი) - ღირებულებების უნიკალურობა
როდესაც თქვენ განსაზღვრავთ შეზღუდვას ღირებულებების უნიკალურობაზე, მაშინ SQL სერვერიავტომატურად ქმნის უნიკალურ არაკლასტერულ ინდექსს. შეგიძლიათ მიუთითოთ, რომ შეიქმნას უნიკალური კლასტერული ინდექსი, თუ მაგიდაზე ჯერ არ არის შექმნილი კლასტერული ინდექსი.
დაფარვის ინდექსი
ასეთი ინდექსი საშუალებას აძლევს კონკრეტულ შეკითხვას დაუყოვნებლივ მიიღოს ყველა საჭირო მონაცემი ინდექსის ფოთლებიდან, თავად ცხრილის ჩანაწერებზე დამატებითი წვდომის გარეშე.ინდექსების დიზაინი
რამდენადაც სასარგებლოა ინდექსები, ისინი ყურადღებით უნდა იყოს შემუშავებული. იმის გამო, რომ ინდექსებმა შეიძლება დაიკავონ მნიშვნელოვანი ადგილი დისკზე, თქვენ არ გსურთ შექმნათ მეტი ინდექსი, ვიდრე საჭიროა. გარდა ამისა, ინდექსები ავტომატურად ახლდება მონაცემთა რიგის განახლებისას, რამაც შეიძლება გამოიწვიოს დამატებითი რესურსის ზედნადები და შესრულების დეგრადაცია. ინდექსების შედგენისას მხედველობაში უნდა იქნას მიღებული რამდენიმე მოსაზრება მონაცემთა ბაზასთან და მის წინააღმდეგ მიმართულ მოთხოვნებთან დაკავშირებით.Მონაცემთა ბაზა
როგორც უკვე აღვნიშნეთ, ინდექსებს შეუძლიათ გააუმჯობესონ სისტემის მუშაობა, რადგან ისინი აწვდიან შეკითხვის სისტემას მონაცემთა მოძიების სწრაფ გზას. თუმცა, თქვენ ასევე უნდა გაითვალისწინოთ რამდენად ხშირად აპირებთ მონაცემების ჩასმას, განახლებას ან წაშლას. როდესაც თქვენ შეცვლით მონაცემებს, ინდექსები ასევე უნდა შეიცვალოს, რათა აისახოს შესაბამისი მოქმედებები მონაცემებზე, რამაც შეიძლება მნიშვნელოვნად შეამციროს სისტემის მუშაობა. ინდექსირების სტრატეგიის დაგეგმვისას გაითვალისწინეთ შემდეგი მითითებები:- ცხრილებისთვის, რომლებიც ხშირად განახლდება, გამოიყენეთ რაც შეიძლება ნაკლები ინდექსი.
- თუ ცხრილი შეიცავს დიდი რაოდენობით მონაცემებს, მაგრამ ცვლილებები უმნიშვნელოა, გამოიყენეთ იმდენი ინდექსი, რამდენიც საჭიროა თქვენი მოთხოვნების შესრულების გასაუმჯობესებლად. თუმცა, მცირე მაგიდებზე ინდექსების გამოყენებამდე კარგად დაფიქრდით, რადგან... შესაძლებელია, რომ ინდექსის ძიების გამოყენებას შეიძლება მეტი დრო დასჭირდეს, ვიდრე უბრალოდ ყველა მწკრივის სკანირება.
- კლასტერული ინდექსებისთვის შეეცადეთ შეინარჩუნოთ ველები რაც შეიძლება მოკლე. საუკეთესო მიდგომაა კლასტერული ინდექსის გამოყენება სვეტებზე, რომლებსაც აქვთ უნიკალური მნიშვნელობები და არ დაუშვებენ NULL-ს. სწორედ ამიტომ პირველადი გასაღები ხშირად გამოიყენება როგორც კლასტერული ინდექსი.
- სვეტის მნიშვნელობების უნიკალურობა გავლენას ახდენს ინდექსის შესრულებაზე. ზოგადად, რაც უფრო მეტი დუბლიკატი გაქვთ სვეტში, მით უფრო უარესია ინდექსი. მეორეს მხრივ, რაც უფრო მეტი უნიკალური მნიშვნელობებია, მით უკეთესია ინდექსის შესრულება. შეძლებისდაგვარად გამოიყენეთ უნიკალური ინდექსი.
- კომპოზიტური ინდექსისთვის, მხედველობაში მიიღება სვეტების თანმიმდევრობა ინდექსში. სვეტები, რომლებიც გამოიყენება გამონათქვამებში სად(Მაგალითად, WHERE FirstName = "ჩარლი") პირველ რიგში უნდა იყოს ინდექსში. შემდგომი სვეტები უნდა იყოს ჩამოთვლილი მათი მნიშვნელობების უნიკალურობიდან გამომდინარე (სვეტები ყველაზე მეტი უნიკალური მნიშვნელობებით პირველ ადგილზეა).
- თქვენ ასევე შეგიძლიათ მიუთითოთ ინდექსი გამოთვლილ სვეტებზე, თუ ისინი აკმაყოფილებენ გარკვეულ მოთხოვნებს. მაგალითად, გამონათქვამები, რომლებიც გამოიყენება სვეტის მნიშვნელობის მისაღებად, უნდა იყოს განმსაზღვრელი (ყოველთვის აბრუნებს იგივე შედეგს შეყვანის პარამეტრების მოცემული ნაკრებისთვის).
მონაცემთა ბაზის მოთხოვნები
ინდექსების შედგენისას კიდევ ერთი გასათვალისწინებელია ის, თუ რა მოთხოვნები იმართება მონაცემთა ბაზის წინააღმდეგ. როგორც უკვე აღვნიშნეთ, უნდა გაითვალისწინოთ რამდენად ხშირად იცვლება მონაცემები. გარდა ამისა, უნდა იქნას გამოყენებული შემდეგი პრინციპები:- შეეცადეთ ჩასვათ ან შეცვალოთ რაც შეიძლება მეტი მწკრივი ერთ შეკითხვაში, ვიდრე ამის გაკეთება რამდენიმე ერთ მოთხოვნაში.
- შექმენით არაკლასტერული ინდექსი სვეტებზე, რომლებიც ხშირად გამოიყენება საძიებო ტერმინებად თქვენს შეკითხვებში. სადდა კავშირები შეუერთდი.
- განიხილეთ სვეტების ინდექსირება, რომლებიც გამოიყენება მწკრივების ძიებაში ზუსტი მნიშვნელობის შესატყვისებისთვის.
ახლა კი რეალურად:
14 შეკითხვა SQL Server-ში ინდექსების შესახებ, რომელთა დასმაც გრცხვენიათ
რატომ არ შეიძლება ცხრილს ჰქონდეს ორი კლასტერული ინდექსი?
გსურთ მოკლე პასუხი? კლასტერული ინდექსი არის ცხრილი. როდესაც თქვენ ქმნით კლასტერულ ინდექსს მაგიდაზე, შენახვის ძრავა ახარისხებს ცხრილის ყველა რიგს აღმავალი ან კლებადობით, ინდექსის განმარტების მიხედვით. კლასტერული ინდექსი არ არის ცალკეული ერთეული, როგორც სხვა ინდექსები, არამედ არის მექანიზმი, რომელიც აწესრიგებს მონაცემთა ცხრილში და ხელს უწყობს მონაცემთა მწკრივებზე სწრაფ წვდომას.წარმოვიდგინოთ, რომ თქვენ გაქვთ ცხრილი, რომელიც შეიცავს გაყიდვების ტრანზაქციების ისტორიას. გაყიდვების ცხრილი შეიცავს ინფორმაციას, როგორიცაა შეკვეთის ID, პროდუქტის პოზიცია შეკვეთაში, პროდუქტის ნომერი, პროდუქტის რაოდენობა, შეკვეთის ნომერი და თარიღი და ა.შ. თქვენ ქმნით კლასტერულ ინდექსს სვეტებზე Შეკვეთის ნომერიდა LineID, დალაგებულია ზრდის მიხედვით, როგორც ნაჩვენებია შემდეგში T-SQLკოდი:
CREATE UNIQUE CLUSTERED INDEX ix_oriderid_lineid ON dbo.Sales(OrderID, LineID);
ამ სკრიპტის გაშვებისას, ცხრილის ყველა სტრიქონი ფიზიკურად იქნება დალაგებული ჯერ OrderID სვეტით და შემდეგ LineID-ით, მაგრამ თავად მონაცემები დარჩება ერთ ლოგიკურ ბლოკში, ცხრილში. ამ მიზეზით, თქვენ არ შეგიძლიათ შექმნათ ორი კლასტერული ინდექსი. შეიძლება იყოს მხოლოდ ერთი ცხრილი ერთი მონაცემით და ამ ცხრილის დალაგება შესაძლებელია მხოლოდ ერთხელ კონკრეტული თანმიმდევრობით.
თუ კლასტერული ცხრილი ბევრ სარგებელს იძლევა, მაშინ რატომ გამოვიყენოთ გროვა?
Მართალი ხარ. კლასტერული ცხრილები შესანიშნავია და თქვენი მოთხოვნების უმეტესობა უკეთესად შეასრულებს ცხრილებს, რომლებსაც აქვთ კლასტერული ინდექსი. მაგრამ ზოგიერთ შემთხვევაში შეიძლება დაგჭირდეთ მაგიდების დატოვება ბუნებრივ, ხელუხლებელ მდგომარეობაში, ე.ი. გროვის სახით და შექმენით მხოლოდ არაკლასტერული ინდექსები თქვენი მოთხოვნების გასაშვებად.გროვა, როგორც გახსოვთ, ინახავს მონაცემებს შემთხვევითი თანმიმდევრობით. როგორც წესი, შენახვის ქვესისტემა ამატებს მონაცემებს ცხრილში იმ თანმიმდევრობით, რომლითაც ის არის ჩასმული, მაგრამ შენახვის ქვესისტემას ასევე მოსწონს რიგების გადაადგილება უფრო ეფექტური შენახვისთვის. შედეგად, თქვენ არ გაქვთ შანსი წინასწარ განსაზღვროთ, რა თანმიმდევრობით შეინახება მონაცემები.
თუ მოთხოვნის ძრავას სჭირდება მონაცემების პოვნა არაკლასტერული ინდექსის სარგებლობის გარეშე, ის გააკეთებს ცხრილის სრულ სკანირებას მისთვის საჭირო რიგების მოსაძებნად. ძალიან პატარა მაგიდებზე ეს ჩვეულებრივ პრობლემას არ წარმოადგენს, მაგრამ როგორც გროვა იზრდება ზომაში, შესრულება სწრაფად იკლებს. რა თქმა უნდა, არაკლასტერული ინდექსი დაგეხმარებათ ფაილის, გვერდისა და მწკრივის მაჩვენებლის გამოყენებით, სადაც ინახება საჭირო მონაცემები - ეს ჩვეულებრივ ბევრად უკეთესი ალტერნატივაა ცხრილის სკანირებისთვის. ასეც რომ იყოს, რთულია კლასტერული ინდექსის უპირატესობების შედარება შეკითხვის შესრულების განხილვისას.
თუმცა, გროვას შეუძლია გარკვეულ სიტუაციებში მუშაობის გაუმჯობესება. განვიხილოთ ცხრილი ბევრი ჩანართი, მაგრამ ცოტა განახლებები ან წაშლები. მაგალითად, ცხრილი, რომელიც ინახავს ჟურნალს, ძირითადად გამოიყენება მნიშვნელობების ჩასართავად, სანამ არ დაარქივდება. გროვაზე, თქვენ ვერ იხილავთ პეიჯინგის და მონაცემთა ფრაგმენტაციას, როგორც კლასტერული ინდექსის შემთხვევაში, რადგან რიგები უბრალოდ ემატება გროვის ბოლოს. გვერდების ზედმეტად გაყოფამ შეიძლება მნიშვნელოვანი გავლენა იქონიოს შესრულებაზე და არა კარგი თვალსაზრისით. ზოგადად, გროვა საშუალებას გაძლევთ ჩაწეროთ მონაცემები შედარებით უმტკივნეულოდ და თქვენ არ მოგიწევთ შენახვა და ტექნიკური ხარჯები, როგორც ეს კლასტერული ინდექსით.
მაგრამ მონაცემების განახლებისა და წაშლის ნაკლებობა არ უნდა ჩაითვალოს ერთადერთ მიზეზად. ასევე მნიშვნელოვანი ფაქტორია მონაცემების შერჩევის მეთოდი. მაგალითად, არ უნდა გამოიყენოთ გროვა, თუ თქვენ ხშირად კითხულობთ მონაცემთა დიაპაზონს ან იმ მონაცემებს, რომლებსაც ხშირად კითხულობთ, სჭირდება დახარისხება ან დაჯგუფება.
ეს ყველაფერი ნიშნავს იმას, რომ თქვენ უნდა განიხილოთ გროვის გამოყენება მხოლოდ მაშინ, როდესაც მუშაობთ ძალიან პატარა ცხრილებთან, ან თქვენი მთელი ურთიერთქმედება მაგიდასთან შემოიფარგლება მხოლოდ მონაცემების ჩასმით და თქვენი მოთხოვნები ძალიან მარტივია (და თქვენ იყენებთ არაკლასტერულ ინდექსებს მაინც). წინააღმდეგ შემთხვევაში, დაიცავით კარგად შემუშავებული კლასტერული ინდექსი, როგორიცაა განსაზღვრული მარტივი აღმავალი კლავიშის ველზე, როგორც ფართოდ გამოყენებული სვეტი პირადობა.
როგორ შევცვალო ნაგულისხმევი ინდექსის შევსების ფაქტორი?
ინდექსის ნაგულისხმევი შევსების ფაქტორის შეცვლა ერთია. იმის გაგება, თუ როგორ მუშაობს ნაგულისხმევი თანაფარდობა, სხვა საკითხია. მაგრამ პირველი, გადადგით რამდენიმე ნაბიჯი უკან. ინდექსის შევსების ფაქტორი განსაზღვრავს გვერდის სივრცის რაოდენობას ინდექსის ქვედა დონეზე (ფოთლის დონეზე) შესანახად ახალი გვერდის შევსების დაწყებამდე. მაგალითად, თუ კოეფიციენტი დაყენებულია 90-ზე, მაშინ როდესაც ინდექსი გაიზრდება, ის დაიკავებს გვერდის 90%-ს და შემდეგ გადავა შემდეგ გვერდზე.ნაგულისხმევად, ინდექსის შევსების ფაქტორის მნიშვნელობა არის SQL სერვერიარის 0, რაც იგივეა, რაც 100. შედეგად, ყველა ახალი ინდექსი ავტომატურად იღებს ამ პარამეტრს, თუ კონკრეტულად არ მიუთითებთ თქვენს კოდში მნიშვნელობას, რომელიც განსხვავდება სისტემის სტანდარტული მნიშვნელობისგან ან არ შეცვლით ნაგულისხმევ ქცევას. Შეგიძლია გამოიყენო SQL Server Management Studioნაგულისხმევი მნიშვნელობის დასარეგულირებლად ან სისტემის შენახული პროცედურის გასაშვებად sp_configure. მაგალითად, შემდეგი ნაკრები T-SQLბრძანებები ადგენს კოეფიციენტის მნიშვნელობას 90-ზე (ჯერ უნდა გადახვიდეთ გაფართოებული პარამეტრების რეჟიმში):
EXEC sp_configure "მოწინავე ვარიანტების ჩვენება", 1; გადადით კონფიგურაციაზე; GO EXEC sp_configure "fill factor", 90; გადადით კონფიგურაციაზე; წადი
ინდექსის შევსების ფაქტორის მნიშვნელობის შეცვლის შემდეგ, თქვენ უნდა გადატვირთოთ სერვისი SQL სერვერი. ახლა შეგიძლიათ შეამოწმოთ მითითებული მნიშვნელობა sp_configure-ის გაშვებით მითითებული მეორე არგუმენტის გარეშე:
EXEC sp_configure "fill factor" GO
ამ ბრძანებამ უნდა დააბრუნოს მნიშვნელობა 90. შედეგად, ყველა ახლად შექმნილი ინდექსი გამოიყენებს ამ მნიშვნელობას. თქვენ შეგიძლიათ შეამოწმოთ ეს ინდექსის შექმნით და შევსების ფაქტორის მნიშვნელობის მოთხოვნით:
გამოიყენეთ AdventureWorks2012; -- თქვენი მონაცემთა ბაზა GO CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName); GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
ამ მაგალითში ჩვენ შევქმენით არაკლასტერული ინდექსი მაგიდაზე პირიმონაცემთა ბაზაში AdventureWorks2012. ინდექსის შექმნის შემდეგ შევსების ფაქტორის მნიშვნელობა შეგვიძლია მივიღოთ sys.indexes სისტემის ცხრილებიდან. მოთხოვნამ უნდა დააბრუნოს 90.
თუმცა, წარმოვიდგინოთ, რომ ჩვენ წავშალეთ ინდექსი და კვლავ შევქმენით იგი, მაგრამ ახლა დავაზუსტეთ კონკრეტული შევსების ფაქტორის მნიშვნელობა:
CREATE NONCLUSTERED INDEX ix_people_lastname ON Person.Person(LastName) WITH (fillfactor=80); GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
ამჯერად ჩვენ დავამატეთ ინსტრუქციები თანდა ვარიანტი შემავსებელი ფაქტორიჩვენი ინდექსის შექმნის ოპერაციისთვის ინდექსის შექმნადა მიუთითა მნიშვნელობა 80. ოპერატორი აირჩიეთახლა აბრუნებს შესაბამის მნიშვნელობას.
აქამდე ყველაფერი საკმაოდ მარტივი იყო. ის, სადაც თქვენ ნამდვილად შეგიძლიათ დაიწვათ მთელი ამ პროცესში, არის როდესაც შექმნით ინდექსს, რომელიც იყენებს ნაგულისხმევი კოეფიციენტის მნიშვნელობას, იმ პირობით, რომ თქვენ იცით ეს მნიშვნელობა. მაგალითად, ვიღაც აინტერესებს სერვერის პარამეტრებს და იმდენად ჯიუტია, რომ ინდექსის შევსების კოეფიციენტს 20-ზე აყენებს. ამასობაში, თქვენ აგრძელებთ ინდექსების შექმნას, თუ ვივარაუდებთ, რომ ნაგულისხმევი მნიშვნელობა არის 0. სამწუხაროდ, თქვენ არ გაქვთ საშუალება გაიგოთ შევსება. შეაფასეთ მანამ, სანამ არ შექმნით ინდექსს და შემდეგ შეამოწმეთ მნიშვნელობა, როგორც ეს გავაკეთეთ ჩვენს მაგალითებში. წინააღმდეგ შემთხვევაში, მოგიწევთ ლოდინი იმ მომენტამდე, როდესაც შეკითხვის შესრულება იმდენად შემცირდება, რომ რაღაცის ეჭვი გექნებათ.
კიდევ ერთი საკითხი, რომელიც უნდა იცოდეთ, არის ინდექსების აღდგენა. როგორც ინდექსის შექმნისას, თქვენ შეგიძლიათ მიუთითოთ ინდექსის შევსების ფაქტორის მნიშვნელობა მისი ხელახლა აშენებისას. თუმცა, შექმნის ინდექსის ბრძანებისგან განსხვავებით, აღდგენა არ იყენებს სერვერის ნაგულისხმევ პარამეტრებს, მიუხედავად იმისა, თუ როგორ შეიძლება ჩანდეს. უფრო მეტიც, თუ კონკრეტულად არ მიუთითებთ ინდექსის შევსების ფაქტორის მნიშვნელობას, მაშინ SQL სერვერიგამოიყენებს იმ კოეფიციენტის მნიშვნელობას, რომლითაც ეს ინდექსი არსებობდა მის რესტრუქტურიზაციამდე. მაგალითად, შემდეგი ოპერაცია ALTER ინდექსიაღადგენს ჩვენ მიერ ახლახანს შექმნილ ინდექსს:
ALTER INDEX ix_people_lastname ON Person.Person REBUILD; GO SELECT fill_factor FROM sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
როდესაც შევამოწმებთ შევსების ფაქტორის მნიშვნელობას, მივიღებთ მნიშვნელობას 80, რადგან ეს არის ის, რაც ჩვენ დავაზუსტეთ, როდესაც ჩვენ შევქმენით ინდექსი ბოლოს. ნაგულისხმევი მნიშვნელობა იგნორირებულია.
როგორც ხედავთ, ინდექსის შევსების ფაქტორის მნიშვნელობის შეცვლა არც ისე რთულია. გაცილებით რთულია მიმდინარე მნიშვნელობის ცოდნა და იმის გაგება, თუ როდის გამოიყენება იგი. თუ თქვენ ყოველთვის კონკრეტულად მიუთითებთ კოეფიციენტს ინდექსების შექმნისა და აღდგენისას, მაშინ ყოველთვის იცით კონკრეტული შედეგი. თუ თქვენ არ უნდა იდარდოთ იმაზე, რომ ვინმემ კვლავ არ გააფუჭოს სერვერის პარამეტრები, რაც გამოიწვევს ყველა ინდექსის აღდგენას სასაცილოდ დაბალი ინდექსის შევსების ფაქტორით.
შესაძლებელია თუ არა კლასტერული ინდექსის შექმნა სვეტზე, რომელიც შეიცავს დუბლიკატებს?
Კი და არა. დიახ, თქვენ შეგიძლიათ შექმნათ კლასტერული ინდექსი გასაღების სვეტზე, რომელიც შეიცავს დუბლიკატ მნიშვნელობებს. არა, საკვანძო სვეტის მნიშვნელობა არ შეიძლება დარჩეს არაუნიკალურ მდგომარეობაში. Ნება მომეცი აგიხსნა. თუ თქვენ შექმნით არაუნიკალურ კლასტერულ ინდექსს სვეტზე, შენახვის ძრავა ამატებს გამაერთიანებელს დუბლიკატულ მნიშვნელობას, რათა უზრუნველყოს უნიკალურობა და, შესაბამისად, შეძლოს თითოეული მწკრივის იდენტიფიცირება კლასტერულ ცხრილში.მაგალითად, თქვენ შეიძლება გადაწყვიტოთ შექმნათ კლასტერული ინდექსი სვეტზე, რომელიც შეიცავს მომხმარებლის მონაცემებს Გვარიგვარის შენარჩუნება. სვეტი შეიცავს მნიშვნელობებს Franklin, Hancock, Washington და Smith. შემდეგ ისევ ჩასვით მნიშვნელობები ადამსი, ჰენკოკი, სმიტი და სმიტი. მაგრამ გასაღების სვეტის მნიშვნელობა უნიკალური უნდა იყოს, ამიტომ შენახვის ძრავა შეცვლის დუბლიკატების მნიშვნელობას ისე, რომ ისინი ასე გამოიყურებოდეს: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567 და Smith5678.
ერთი შეხედვით, ეს მიდგომა კარგად ჩანს, მაგრამ მთელი რიცხვი ზრდის გასაღების ზომას, რაც შეიძლება პრობლემად იქცეს, თუ დუბლიკატების დიდი რაოდენობაა და ეს მნიშვნელობები გახდება არაკლასტერული ინდექსის ან უცხოურის საფუძველი. საკვანძო მითითება. ამ მიზეზების გამო, ყოველთვის უნდა შეეცადოთ შექმნათ უნიკალური კლასტერული ინდექსები, როდესაც ეს შესაძლებელია. თუ ეს შეუძლებელია, მაშინ მაინც შეეცადეთ გამოიყენოთ სვეტები ძალიან მაღალი უნიკალური მნიშვნელობის შემცველობით.
როგორ ინახება ცხრილი, თუ კლასტერული ინდექსი არ არის შექმნილი?
SQL სერვერიმხარს უჭერს ორი ტიპის ცხრილებს: კლასტერულ ცხრილებს, რომლებსაც აქვთ დაჯგუფებული ინდექსი და გროვის ცხრილები ან უბრალოდ გროვები. კლასტერული ცხრილებისგან განსხვავებით, გროვაზე მონაცემები არანაირად არ არის დალაგებული. არსებითად, ეს არის მონაცემთა გროვა (გროვა). თუ ასეთ ცხრილს რიგს დაამატებთ, შენახვის ძრავა უბრალოდ დაამატებს მას გვერდის ბოლოს. როდესაც გვერდი ივსება მონაცემებით, ის დაემატება ახალ გვერდზე. უმეტეს შემთხვევაში, თქვენ გსურთ შექმნათ კლასტერული ინდექსი მაგიდაზე, რათა ისარგებლოთ დახარისხებად და შეკითხვის სიჩქარით (სცადეთ წარმოიდგინოთ ტელეფონის ნომრის მოძიება დაუხარისხებელ მისამართთა წიგნში). თუმცა, თუ აირჩევთ არ შექმნათ კლასტერული ინდექსი, თქვენ მაინც შეგიძლიათ შექმნათ არაკლასტერული ინდექსი გროვაზე. ამ შემთხვევაში, თითოეულ ინდექსის მწკრივს ექნება მაჩვენებელი გროვის მწკრივისკენ. ინდექსში შედის ფაილის ID, გვერდის ნომერი და მონაცემთა ხაზის ნომერი.რა კავშირია მნიშვნელობის უნიკალურობის შეზღუდვებსა და ცხრილის ინდექსებთან პირველად გასაღებს შორის?
პირველადი გასაღები და უნიკალური შეზღუდვა უზრუნველყოფს, რომ სვეტის მნიშვნელობები უნიკალურია. თქვენ შეგიძლიათ შექმნათ მხოლოდ ერთი ძირითადი გასაღები ცხრილისთვის და ის არ შეიძლება შეიცავდეს მნიშვნელობებს NULL. თქვენ შეგიძლიათ შექმნათ რამდენიმე შეზღუდვა ცხრილისთვის მნიშვნელობის უნიკალურობაზე და თითოეულ მათგანს შეიძლება ჰქონდეს ერთი ჩანაწერი NULL.პირველადი გასაღების შექმნისას, შენახვის ძრავა ასევე ქმნის უნიკალურ კლასტერულ ინდექსს, თუ კლასტერული ინდექსი უკვე არ არის შექმნილი. თუმცა, თქვენ შეგიძლიათ უგულებელყოთ ნაგულისხმევი ქცევა და შეიქმნება არაკლასტერული ინდექსი. თუ პირველადი გასაღების შექმნისას არსებობს კლასტერული ინდექსი, შეიქმნება უნიკალური არაკლასტერული ინდექსი.
როდესაც თქვენ ქმნით უნიკალურ შეზღუდვას, შენახვის ძრავა ქმნის უნიკალურ, არაკლასტერულ ინდექსს. თუმცა, შეგიძლიათ მიუთითოთ უნიკალური კლასტერული ინდექსის შექმნა, თუ ის ადრე არ იყო შექმნილი.
ზოგადად, უნიკალური მნიშვნელობის შეზღუდვა და უნიკალური ინდექსი ერთი და იგივეა.
რატომ ჰქვია კლასტერულ და არაკლასტერულ ინდექსებს B-tree SQL Server-ში?
ძირითადი ინდექსები SQL Server-ში, კლასტერული ან არაკლასტერული, ნაწილდება გვერდების ერთობლიობაში, რომელსაც ეწოდება ინდექსის კვანძები. ეს გვერდები ორგანიზებულია კონკრეტულ იერარქიაში ხის სტრუქტურით, რომელსაც ეწოდება დაბალანსებული ხე. ზედა დონეზე არის ფესვის კვანძი, ბოლოში არის ფოთლის კვანძები, ზედა და ქვედა დონეებს შორის შუალედური კვანძებით, როგორც ნაჩვენებია სურათზე:ძირეული კვანძი უზრუნველყოფს მთავარ შესვლის წერტილს შეკითხვებისთვის, რომლებიც ცდილობენ ინდექსის მეშვეობით მონაცემების მოძიებას. ამ კვანძიდან დაწყებული, შეკითხვის ძრავა იწყებს ნავიგაციას იერარქიული სტრუქტურის ქვემოთ შესაბამის ფოთლის კვანძში, რომელიც შეიცავს მონაცემებს.
მაგალითად, წარმოიდგინეთ, რომ მიღებულია მოთხოვნა 82-ის საკვანძო მნიშვნელობის შემცველი რიგების შესარჩევად. შეკითხვის ქვესისტემა იწყებს მუშაობას ძირეული კვანძიდან, რომელიც ეხება შესაბამის შუალედურ კვანძს, ჩვენს შემთხვევაში 1-100. შუალედური კვანძიდან 1-100 ხდება გადასვლა 51-100 კვანძზე, იქიდან კი საბოლოო კვანძზე 76-100. თუ ეს არის კლასტერული ინდექსი, მაშინ კვანძის ფურცელი შეიცავს 82-ის ტოლი კლავიშთან დაკავშირებული მწკრივის მონაცემებს. თუ ეს არაჯგუფური ინდექსია, მაშინ ინდექსის ფურცელი შეიცავს მაჩვენებელს დაჯგუფებული ცხრილისკენ ან კონკრეტულ მწკრივში გროვა.
როგორ შეიძლება ინდექსმა გააუმჯობესოს შეკითხვის შესრულება, თუ თქვენ უნდა გაიაროთ ყველა ეს ინდექსის კვანძი?
პირველი, ინდექსები ყოველთვის არ აუმჯობესებენ შესრულებას. ძალიან ბევრი არასწორად შექმნილი ინდექსი აქცევს სისტემას ჭაობში და ამცირებს შეკითხვის შესრულებას. უფრო ზუსტია იმის თქმა, რომ თუ ინდექსები საგულდაგულოდ არის გამოყენებული, მათ შეუძლიათ მნიშვნელოვანი ეფექტურობის მიღწევა.წარმოიდგინეთ უზარმაზარი წიგნი, რომელიც ეძღვნება შესრულების დარეგულირებას SQL სერვერი(ქაღალდის ვერსია და არა ელექტრონული ვერსია). წარმოიდგინეთ, რომ გსურთ იპოვოთ ინფორმაცია რესურსის მმართველის კონფიგურაციის შესახებ. შეგიძლიათ თითი გვერდ-გვერდ გადაათრიოთ მთელ წიგნში, ან გახსნათ სარჩევი და გაიგოთ ზუსტი გვერდის ნომერი იმ ინფორმაციით, რომელსაც ეძებთ (იმ პირობით, რომ წიგნი სწორად არის ინდექსირებული და შიგთავსს აქვს სწორი ინდექსები). ეს რა თქმა უნდა დაზოგავს მნიშვნელოვან დროს, მიუხედავად იმისა, რომ ჯერ უნდა შეხვიდეთ სრულიად განსხვავებულ სტრუქტურაზე (ინდექსი), რათა მიიღოთ თქვენთვის საჭირო ინფორმაცია პირველადი სტრუქტურიდან (წიგნიდან).
წიგნის ინდექსის მსგავსად, ინდექსი SQL სერვერისაშუალებას გაძლევთ შეასრულოთ ზუსტი მოთხოვნები თქვენთვის საჭირო მონაცემებზე, ნაცვლად იმისა, რომ სრულად დაასკანიროთ ცხრილში მოცემული ყველა მონაცემი. მცირე ცხრილებისთვის, სრული სკანირება, როგორც წესი, არ არის პრობლემა, მაგრამ დიდი ცხრილები იკავებს მონაცემთა ბევრ გვერდს, რამაც შეიძლება გამოიწვიოს მოთხოვნის შესრულების მნიშვნელოვანი დრო, თუ არ არსებობს ინდექსი, რომელიც საშუალებას მისცემს შეკითხვის ძრავას დაუყოვნებლივ მიიღოს მონაცემების სწორი მდებარეობა. წარმოიდგინეთ, რომ დაიკარგებით მრავალ დონის გზის გასაყარზე, მთავარი მეტროპოლიის წინ, რუქის გარეშე და თქვენ მიიღებთ იდეას.
თუ ინდექსები ძალიან დიდია, რატომ არ უნდა შექმნათ ერთი ყველა სვეტზე?
არც ერთი კარგი საქმე არ უნდა დარჩეს დაუსჯელი. ყოველ შემთხვევაში, ასეა ინდექსებთან დაკავშირებით. რა თქმა უნდა, ინდექსები მშვენივრად მუშაობს მანამ, სანამ თქვენ აწარმოებთ ოპერატორის მოძიების შეკითხვებს აირჩიეთ, მაგრამ როგორც კი დაიწყება ხშირი ზარები ოპერატორებთან INSERT, განახლებადა წაშლაასე რომ, ლანდშაფტი ძალიან სწრაფად იცვლება.როდესაც თქვენ იწყებთ მონაცემთა მოთხოვნას ოპერატორის მიერ აირჩიეთ, შეკითხვის ძრავა პოულობს ინდექსს, მოძრაობს მის ხის სტრუქტურაში და აღმოაჩენს მონაცემებს, რომელსაც ეძებს. რა შეიძლება იყოს უფრო მარტივი? მაგრამ ყველაფერი იცვლება, თუ თქვენ წამოიწყებთ ცვლილების განცხადებას, როგორიცაა განახლება. დიახ, განცხადების პირველი ნაწილისთვის, შეკითხვის ძრავას შეუძლია კვლავ გამოიყენოს ინდექსი შეცვლილი მწკრივის დასადგენად - ეს კარგი ამბავია. და თუ ზედიზედ არის მონაცემების მარტივი ცვლილება, რომელიც არ იმოქმედებს საკვანძო სვეტების ცვლილებებზე, მაშინ ცვლილების პროცესი სრულიად უმტკივნეულო იქნება. მაგრამ რა მოხდება, თუ ცვლილება გამოიწვევს მონაცემების შემცველი გვერდების გაყოფას, ან საკვანძო სვეტის მნიშვნელობის შეცვლას, რაც იწვევს მის სხვა ინდექსის კვანძში გადატანას - ეს გამოიწვევს ინდექსს შესაძლოა საჭირო გახდეს რეორგანიზაცია, რომელიც გავლენას მოახდენს ყველა ასოცირებულ ინდექსზე და ოპერაციებზე. , რამაც გამოიწვია პროდუქტიულობის ფართო დაქვეითება.
მსგავსი პროცესები ხდება ოპერატორთან დარეკვისას წაშლა. ინდექსი დაგეხმარებათ წაშლილი მონაცემების დადგენაში, მაგრამ თავად მონაცემების წაშლამ შეიძლება გამოიწვიოს გვერდის შეცვლა. რაც შეეხება ოპერატორს INSERT, ყველა ინდექსის მთავარი მტერი: იწყებ დიდი რაოდენობით მონაცემების დამატებას, რაც იწვევს ინდექსების ცვლილებას და მათ რეორგანიზაციას და ყველა ზარალდება.
ასე რომ, გაითვალისწინეთ თქვენი მონაცემთა ბაზაში შეკითხვის ტიპები, როდესაც ფიქრობთ იმაზე, თუ რა ტიპის ინდექსები და რამდენი შექმნათ. მეტი არ ნიშნავს უკეთესს. ცხრილზე ახალი ინდექსის დამატებამდე გაითვალისწინეთ არა მხოლოდ ძირითადი მოთხოვნების ღირებულება, არამედ მოხმარებული დისკის სივრცის რაოდენობა, ფუნქციონირებისა და ინდექსების შენარჩუნების ღირებულება, რამაც შეიძლება გამოიწვიოს დომინოს ეფექტი სხვა ოპერაციებზე. თქვენი ინდექსის დიზაინის სტრატეგია თქვენი განხორციელების ერთ-ერთი ყველაზე მნიშვნელოვანი ასპექტია და უნდა მოიცავდეს ბევრ მოსაზრებას, ინდექსის ზომიდან, უნიკალური მნიშვნელობების რაოდენობამდე, მოთხოვნების ტიპებამდე, რომელსაც ინდექსი მხარს უჭერს.
აუცილებელია თუ არა სვეტზე კლასტერული ინდექსის შექმნა პირველადი გასაღებით?
თქვენ შეგიძლიათ შექმნათ კლასტერული ინდექსი ნებისმიერ სვეტზე, რომელიც აკმაყოფილებს საჭირო პირობებს. მართალია, კლასტერული ინდექსი და ძირითადი გასაღების შეზღუდვა შექმნილია ერთმანეთისთვის და არის სამოთხეში შექმნილი შესატყვისი, ასე რომ გესმოდეთ ის ფაქტი, რომ როდესაც პირველად შექმნით, მაშინ ავტომატურად შეიქმნება კლასტერული ინდექსი, თუ ის არ ყოფილა. ადრე შექმნილი. თუმცა, თქვენ შეიძლება გადაწყვიტოთ, რომ კლასტერული ინდექსი უკეთესად მუშაობს სხვაგან და ხშირად თქვენი გადაწყვეტილება გამართლებული იქნება.კლასტერული ინდექსის მთავარი მიზანია თქვენი ცხრილის ყველა მწკრივის დალაგება ინდექსის განსაზღვრისას მითითებული გასაღების სვეტის მიხედვით. ეს უზრუნველყოფს სწრაფ ძიებას და მარტივ წვდომას ცხრილის მონაცემებზე.
ცხრილის პირველადი გასაღები შეიძლება იყოს კარგი არჩევანი, რადგან ის ცალსახად განსაზღვრავს ცხრილების თითოეულ რიგს დამატებითი მონაცემების დამატების გარეშე. ზოგიერთ შემთხვევაში, საუკეთესო არჩევანი იქნება სუროგატი პირველადი გასაღები, რომელიც არა მხოლოდ უნიკალურია, არამედ მცირე ზომისაც და რომლის მნიშვნელობებიც თანმიმდევრულად იზრდება, რაც ამ მნიშვნელობაზე დაფუძნებულ არაკლასტერულ ინდექსებს უფრო ეფექტურს ხდის. შეკითხვის ოპტიმიზატორს ასევე მოსწონს კლასტერული ინდექსისა და პირველადი გასაღების ეს კომბინაცია, რადგან ცხრილების შეერთება უფრო სწრაფია, ვიდრე სხვა გზით შეერთება, რომელიც არ იყენებს ძირითად გასაღებს და მასთან დაკავშირებულ კლასტერულ ინდექსს. როგორც ვთქვი, ეს სამოთხეში შექმნილი მატჩია.
თუმცა, და ბოლოს, აღსანიშნავია, რომ კლასტერული ინდექსის შექმნისას გასათვალისწინებელია რამდენიმე ასპექტი: რამდენი არაკლასტერული ინდექსი დაფუძნდება მასზე, რამდენად ხშირად შეიცვლება საკვანძო ინდექსის სვეტის მნიშვნელობა და რამდენად დიდი. როდესაც კლასტერული ინდექსის სვეტების მნიშვნელობები იცვლება ან ინდექსი არ მუშაობს ისე, როგორც მოსალოდნელია, მაშინ ცხრილის ყველა სხვა ინდექსზე შეიძლება გავლენა იქონიოს. კლასტერული ინდექსი უნდა ეფუძნებოდეს ყველაზე მდგრად სვეტს, რომლის მნიშვნელობები იზრდება კონკრეტული თანმიმდევრობით, მაგრამ არ იცვლება შემთხვევითი გზით. ინდექსმა უნდა მხარი დაუჭიროს შეკითხვებს ცხრილის ყველაზე ხშირად მისაწვდომ მონაცემებთან მიმართებაში, ამიტომ მოთხოვნები სრულად სარგებლობს იმით, რომ მონაცემები დალაგებულია და ხელმისაწვდომია ძირეულ კვანძებში, ინდექსის ფოთლებში. თუ პირველადი გასაღები შეესაბამება ამ სცენარს, მაშინ გამოიყენეთ იგი. თუ არა, მაშინ აირჩიეთ სვეტების სხვა ნაკრები.
რა მოხდება, თუ ხედის ინდექსირებას ახდენთ, ის მაინც ხედია?
ხედი არის ვირტუალური ცხრილი, რომელიც ქმნის მონაცემებს ერთი ან მეტი ცხრილიდან. არსებითად, ეს არის დასახელებული მოთხოვნა, რომელიც ამოიღებს მონაცემებს ძირითადი ცხრილებიდან, როდესაც თქვენ კითხულობთ ამ ხედს. თქვენ შეგიძლიათ გააუმჯობესოთ შეკითხვის შესრულება ამ ხედზე კლასტერული და არაკლასტერული ინდექსების შექმნით, ისევე, როგორც თქვენ ქმნით ინდექსებს მაგიდაზე, მაგრამ მთავარი გაფრთხილება ისაა, რომ ჯერ შექმნით კლასტერულ ინდექსს, შემდეგ კი შეგიძლიათ შექმნათ არაკლასტერული.როდესაც იქმნება ინდექსირებული ხედი (მატერიალიზებული ხედი), მაშინ თავად ხედის განმარტება რჩება ცალკეულ ერთეულად. ყოველივე ამის შემდეგ, ეს მხოლოდ მყარი კოდირებული ოპერატორია აირჩიეთ, ინახება მონაცემთა ბაზაში. მაგრამ ინდექსი სრულიად განსხვავებული ამბავია. როდესაც პროვაიდერზე ქმნით კლასტერულ ან არაკლასტერულ ინდექსს, მონაცემები ფიზიკურად ინახება დისკზე, ისევე როგორც ჩვეულებრივი ინდექსი. გარდა ამისა, როდესაც მონაცემები იცვლება ძირითად ცხრილებში, ხედის ინდექსი ავტომატურად იცვლება (ეს ნიშნავს, რომ თქვენ შეიძლება თავიდან აიცილოთ ნახვების ინდექსირება ცხრილებზე, რომლებიც ხშირად იცვლება). ნებისმიერ შემთხვევაში, ხედი რჩება ხედად - ცხრილების ხედვა, მაგრამ ერთი შესრულებული მომენტში, მის შესაბამისი ინდექსებით.
სანამ ხედზე ინდექსის შექმნას შეძლებთ, ის უნდა აკმაყოფილებდეს რამდენიმე შეზღუდვას. მაგალითად, ხედს შეუძლია მიმართოს მხოლოდ ბაზის ცხრილებს, მაგრამ არა სხვა ხედებს და ეს ცხრილები უნდა იყოს იმავე მონაცემთა ბაზაში. სინამდვილეში ბევრი სხვა შეზღუდვაა, ასე რომ, დარწმუნდით, რომ შეამოწმეთ დოკუმენტაცია SQL სერვერიყველა ბინძური დეტალისთვის.
რატომ გამოვიყენოთ დაფარვის ინდექსი კომპოზიტური ინდექსის ნაცვლად?
პირველ რიგში, მოდით დავრწმუნდეთ, რომ გვესმის განსხვავება ამ ორს შორის. რთული ინდექსი არის ჩვეულებრივი ინდექსი, რომელიც შეიცავს ერთზე მეტ სვეტს. მრავალი საკვანძო სვეტი შეიძლება გამოყენებულ იქნას იმის უზრუნველსაყოფად, რომ ცხრილის თითოეული მწკრივი უნიკალურია, ან შეიძლება გქონდეთ რამდენიმე სვეტი, რათა დარწმუნდეთ, რომ პირველადი გასაღები უნიკალურია, ან შეიძლება ცდილობთ ოპტიმიზაციას გაუწიოთ ხშირად გამოძახებული მოთხოვნების შესრულება მრავალ სვეტზე. ზოგადად, რაც უფრო მეტ საკვანძო სვეტს შეიცავს ინდექსი, მით უფრო ნაკლებად ეფექტური იქნება ინდექსი, რაც ნიშნავს, რომ კომპოზიტური ინდექსები გონივრულად უნდა იქნას გამოყენებული.როგორც აღინიშნა, შეკითხვას შეუძლია დიდი სარგებლობა მოახდინოს, თუ ყველა საჭირო მონაცემი დაუყოვნებლივ განთავსდება ინდექსის ფოთლებზე, ისევე როგორც თავად ინდექსი. ეს არ არის პრობლემა კლასტერული ინდექსისთვის, რადგან ყველა მონაცემი უკვე არსებობს (ამიტომ მნიშვნელოვანია, რომ ყურადღებით იფიქროთ კლასტერული ინდექსის შექმნისას). მაგრამ ფოთლებზე არაჯგუფური ინდექსი შეიცავს მხოლოდ საკვანძო სვეტებს. ყველა სხვა მონაცემზე წვდომისთვის, შეკითხვის ოპტიმიზატორი საჭიროებს დამატებით ნაბიჯებს, რომლებსაც შეუძლიათ მნიშვნელოვანი ზედნადების დამატება თქვენი მოთხოვნების შესრულებაზე.
სწორედ აქ მოდის დაფარვის ინდექსი სამაშველოში. როდესაც თქვენ განსაზღვრავთ არაკლასტერულ ინდექსს, შეგიძლიათ მიუთითოთ დამატებითი სვეტები თქვენი საკვანძო სვეტებისთვის. მაგალითად, ვთქვათ, თქვენი აპლიკაცია ხშირად ითხოვს სვეტის მონაცემებს Შეკვეთის ნომერიდა Შეკვეთის თარიღიმაგიდაზე Გაყიდვების:
SELECT OrderID, OrderDate FROM Sales WHERE OrderID = 12345;
თქვენ შეგიძლიათ შექმნათ რთული არაკლასტერული ინდექსი ორივე სვეტზე, მაგრამ OrderDate სვეტი დაამატებს მხოლოდ ინდექსის შენარჩუნების ზედნადებს, განსაკუთრებით სასარგებლო კლავიშის სვეტის გარეშე. საუკეთესო გამოსავალი იქნება საკვანძო სვეტზე დაფარვის ინდექსის შექმნა Შეკვეთის ნომერიდა დამატებით ჩართული სვეტი Შეკვეთის თარიღი:
CREATE NONCLUSTERED INDEX ix_orderid ON dbo.Sales(OrderID) incluDE (OrderDate);
ეს თავიდან აიცილებს ზედმეტი სვეტების ინდექსირების ნაკლოვანებებს, ხოლო შეკითხვის გაშვებისას შენარჩუნებულია ფოთლებში მონაცემების შენახვის უპირატესობები. ჩართული სვეტი არ არის გასაღების ნაწილი, მაგრამ მონაცემები ინახება ფოთლის კვანძზე, ინდექსის ფურცელზე. ამან შეიძლება გააუმჯობესოს მოთხოვნის შესრულება დამატებითი ხარჯების გარეშე. გარდა ამისა, დაფარვის ინდექსში შემავალი სვეტები ექვემდებარება ნაკლებ შეზღუდვებს, ვიდრე ინდექსის ძირითადი სვეტები.
აქვს თუ არა მნიშვნელობა საკვანძო სვეტში დუბლიკატების რაოდენობას?
ინდექსის შექმნისას თქვენ უნდა შეეცადოთ შეამციროთ დუბლიკატების რაოდენობა თქვენს საკვანძო სვეტებში. უფრო სწორად: შეეცადეთ შეინარჩუნოთ გამეორების სიჩქარე რაც შეიძლება დაბალი.თუ თქვენ მუშაობთ კომპოზიტურ ინდექსთან, მაშინ დუბლირება ვრცელდება ყველა საკვანძო სვეტზე მთლიანობაში. ერთი სვეტი შეიძლება შეიცავდეს ბევრ დუბლიკატულ მნიშვნელობას, მაგრამ ინდექსის ყველა სვეტს შორის მინიმალური გამეორება უნდა იყოს. მაგალითად, თქვენ ქმნით კომპოზიციურ არაკლასტერულ ინდექსს სვეტებზე Სახელიდა Გვარი, შეგიძლიათ გქონდეთ John Doe-ს ბევრი მნიშვნელობა და ბევრი Doe-ის მნიშვნელობა, მაგრამ გსურთ გქონდეთ რაც შეიძლება ნაკლები John Doe-ის მნიშვნელობა, ან სასურველია მხოლოდ ერთი John Doe-ის მნიშვნელობა.
საკვანძო სვეტის მნიშვნელობების უნიკალურობის თანაფარდობას ეწოდება ინდექსის სელექციურობა. რაც უფრო მეტი უნიკალური მნიშვნელობებია, მით უფრო მაღალია სელექციურობა: უნიკალურ ინდექსს აქვს მაქსიმალური შერჩევითობა. შეკითხვის ძრავას ნამდვილად მოსწონს სვეტები მაღალი სელექციურობის მნიშვნელობებით, განსაკუთრებით თუ ეს სვეტები შედის თქვენი ყველაზე ხშირად შესრულებული მოთხოვნების WHERE პუნქტებში. რაც უფრო შერჩევითია ინდექსი, მით უფრო ჩქარა შეკითხვის ძრავას შეუძლია შეამციროს მიღებული მონაცემთა ნაკრების ზომა. მინუსი, რა თქმა უნდა, ის არის, რომ შედარებით მცირე უნიკალური მნიშვნელობის მქონე სვეტები იშვიათად იქნებიან კარგი კანდიდატები ინდექსაციისთვის.
შესაძლებელია თუ არა არაკლასტერული ინდექსის შექმნა საკვანძო სვეტის მონაცემების მხოლოდ კონკრეტულ ქვეჯგუფზე?
ნაგულისხმევად, არაკლასტერული ინდექსი შეიცავს ერთ სტრიქონს ცხრილის თითოეული მწკრივისთვის. რა თქმა უნდა, იგივეს თქმა შეგიძლიათ კლასტერულ ინდექსზე, თუ ვივარაუდებთ, რომ ასეთი ინდექსი არის ცხრილი. მაგრამ როდესაც საქმე ეხება არაკლასტერულ ინდექსს, ერთი-ერთზე ურთიერთობა მნიშვნელოვანი კონცეფციაა, რადგან ვერსიით დაწყებული SQL Server 2008, თქვენ გაქვთ შესაძლებლობა შექმნათ ფილტრირებადი ინდექსი, რომელიც ზღუდავს მასში შემავალ რიგებს. გაფილტრულ ინდექსს შეუძლია გააუმჯობესოს მოთხოვნის შესრულება, რადგან... ის უფრო მცირე ზომისაა და შეიცავს გაფილტრულ, უფრო ზუსტ სტატისტიკას, ვიდრე ყველა ცხრილი - ეს იწვევს გაუმჯობესებული შესრულების გეგმების შექმნას. გაფილტრული ინდექსი ასევე მოითხოვს ნაკლებ საცავ ადგილს და შენარჩუნების დაბალ ხარჯებს. ინდექსი განახლდება მხოლოდ მაშინ, როდესაც იცვლება ფილტრის შესაბამისი მონაცემები.გარდა ამისა, ფილტრირებადი ინდექსის შექმნა მარტივია. ოპერატორში ინდექსის შექმნათქვენ უბრალოდ უნდა მიუთითოთ სადფილტრის მდგომარეობა. მაგალითად, შეგიძლიათ გაფილტროთ ყველა მწკრივი, რომელიც შეიცავს NULL-ს ინდექსიდან, როგორც ეს ნაჩვენებია კოდში:
CREATE NONCLUSTERED INDEX ix_trackingnumber ON Sales.SalesOrderDetail(CarrierTrackingNumber) სადაც CarrierTrackingNumber NULL არ არის;
ჩვენ შეგვიძლია, ფაქტობრივად, გავფილტროთ ნებისმიერი მონაცემი, რომელიც არ არის მნიშვნელოვანი კრიტიკულ შეკითხვებში. მაგრამ ფრთხილად იყავით, რადგან... SQL სერვერიაწესებს რამდენიმე შეზღუდვას გაფილტვრად ინდექსებზე, მაგალითად, ხედზე ფილტრირებადი ინდექსის შექმნის შეუძლებლობა, ამიტომ ყურადღებით წაიკითხეთ დოკუმენტაცია.
შეიძლება ასევე იყოს ის, რომ თქვენ შეგიძლიათ მიაღწიოთ მსგავს შედეგებს ინდექსირებული ხედის შექმნით. თუმცა, გაფილტრულ ინდექსს აქვს რამდენიმე უპირატესობა, როგორიცაა შენარჩუნების ხარჯების შემცირების შესაძლებლობა და თქვენი შესრულების გეგმების ხარისხის გაუმჯობესება. გაფილტრული ინდექსების აღდგენა შესაძლებელია ონლაინ რეჟიმში. სცადეთ ეს ინდექსირებული ხედით.
და ისევ ცოტა მთარგმნელისგან
Habrahabr-ის გვერდებზე ამ თარგმანის გამოჩენის მიზანი იყო მოგიყვეთ ან შეგახსენოთ SimpleTalk ბლოგის შესახებ. RedGate.
ის აქვეყნებს ბევრ გასართობ და საინტერესო პოსტს.
მე არ ვარ ასოცირებული რომელიმე კომპანიის პროდუქტთან RedGateარც მათი გაყიდვით.
როგორც დაგპირდით, წიგნები მათთვის, ვისაც სურს მეტი იცოდეს
მე გირჩევთ სამ ძალიან კარგ წიგნს ჩემგან (ბმულები მივყავართ აანთებსვერსიები მაღაზიაში ამაზონი):
 |
Microsoft SQL Server 2012 T-SQL საფუძვლები (დეველოპერის მითითება) ავტორი იციკ ბენ-განი გამოცემის თარიღი: 2012 წლის 15 ივლისი ავტორი, თავისი საქმის ოსტატი, გვაწვდის საბაზისო ცოდნას მონაცემთა ბაზებთან მუშაობის შესახებ. თუ ყველაფერი დაგავიწყდათ ან არასოდეს იცოდით, ნამდვილად ღირს წაკითხვა. | პრინციპში, შეგიძლიათ გახსნათ მარტივი ინდექსები