1) Konsep indeks
Indeks adalah alat yang menyediakan akses cepat ke baris tabel berdasarkan nilai satu atau lebih kolom.
Ada banyak variasi dalam operator ini karena tidak terstandarisasi, karena standar tidak mengatasi masalah kinerja.
2) Membuat indeks
BUAT INDEKS
PADA()
3) Mengubah dan menghapus indeks
Untuk mengontrol aktivitas indeks, operator digunakan:
MENGUBAH INDEKS
Untuk menghapus indeks, gunakan operator:
JATUHKAN INDEKS
a) Aturan pemilihan meja
1. Dianjurkan untuk mengindeks tabel yang tidak lebih dari 5% barisnya dipilih.
2. Tabel yang tidak memiliki duplikat dalam klausa WHERE pada pernyataan SELECT harus diindeks.
3. Tidaklah praktis untuk mengindeks tabel yang sering diperbarui.
4. Tidak tepat untuk mengindeks tabel yang menempati tidak lebih dari 2 halaman (untuk Oracle kurang dari 300 baris), karena pemindaian penuhnya tidak memakan waktu lebih lama.
b) Aturan pemilihan kolom
1. Kunci primer dan asing - sering digunakan untuk menggabungkan tabel, mengambil data, dan mencari. Ini selalu merupakan indeks unik dengan utilitas maksimal
2. Saat menggunakan opsi integritas referensial, Anda selalu memerlukan indeks pada FK.
3. Kolom yang sering digunakan untuk mengurutkan dan/atau mengelompokkan data.
4. Kolom yang sering dicari pada klausa WHERE pada pernyataan SELECT.
5. Anda tidak boleh membuat indeks pada kolom deskriptif yang panjang.
c) Prinsip pembuatan indeks komposit
1. Indeks gabungan baik jika masing-masing kolom memiliki sedikit nilai unik, namun indeks gabungan memberikan lebih banyak keunikan.
2. Jika semua nilai yang dipilih oleh pernyataan SELECT termasuk dalam indeks komposit, maka nilai tersebut dipilih dari indeks.
3. Indeks gabungan harus dibuat jika klausa WHERE menggunakan dua nilai atau lebih yang digabungkan dengan operator AND.
d) Tidak disarankan untuk membuat
Tidak disarankan membuat indeks pada kolom, termasuk kolom komposit, yang:
1. Jarang digunakan untuk pencarian, penggabungan, dan pengurutan hasil query.
2. Berisi nilai yang sering berubah, yang memerlukan pembaruan indeks secara berkala, sehingga memperlambat kinerja database.
3. Berisi sejumlah kecil nilai unik (kurang dari 10% m/f) atau sejumlah baris dominan dengan satu atau dua nilai (kota tempat tinggal pemasok adalah Moskow).
4. Fungsi atau ekspresi diterapkan padanya dalam klausa WHERE, dan indeks tidak berfungsi.
e) Kita tidak boleh lupa
Anda harus berusaha mengurangi jumlah indeks, karena jumlah indeks yang banyak mengurangi kecepatan pembaruan data. Oleh karena itu, MS SQL Server merekomendasikan pembuatan tidak lebih dari 16 indeks per tabel.
Biasanya, indeks dibuat untuk tujuan kueri dan untuk menjaga integritas referensial.
Jika indeks tidak digunakan untuk kueri, maka indeks tersebut harus dihapus dan integritas referensial harus dipastikan menggunakan pemicu.
Untuk menyediakan akses cepat ke baris tabel Oracle DBMS, indeks digunakan. Indeks menyediakan akses cepat ke data selama operasi yang memilih baris tabel dalam jumlah yang relatif kecil.
Meskipun Oracle mengizinkan jumlah indeks yang tidak terbatas pada sebuah tabel, indeks hanya berguna jika digunakan untuk mempercepat kueri. Jika tidak, kolom tersebut hanya akan memakan ruang dan mengurangi kinerja server saat memperbarui kolom yang diindeks. Anda harus menggunakan fitur EXPLAIN PLAN (rencana eksekusi dan statistik) untuk menentukan bagaimana indeks digunakan dalam kueri Anda. Terkadang, jika indeks tidak digunakan secara default, Anda bisa menggunakan petunjuk kueri untuk menggunakan indeks.
Buat indeks setelah memasukkan data tabel
Biasanya, Anda memasukkan atau memuat data ke dalam tabel sebelum membuat indeks. Jika tidak, biaya tambahan untuk memperbarui indeks akan memperlambat operasi penyisipan atau pemuatan. Satu-satunya pengecualian terhadap aturan ini adalah indeks pada kunci cluster. Itu hanya dapat dibuat untuk cluster kosong.
Beralih ke tablespace sementara untuk menghindari masalah ruang kosong saat membuat indeks
Saat membuat indeks pada tabel yang sudah berisi data, Oracle membutuhkan memori tambahan untuk pengurutan. Ini menggunakan area memori penyortiran yang dialokasikan untuk pembuat indeks (jumlah yang dialokasikan untuk setiap pengguna ditentukan oleh parameter inisialisasi SORT_AREA_SIZE), selain itu, server Oracle harus membersihkan dan menukar informasi dari segmen sementara yang dialokasikan selama pembuatan indeks. Jika indeksnya sangat besar, disarankan untuk melakukan hal berikut:
- Buat ruang tabel sementara baru menggunakan pernyataan CREATE TABLESPACE.
- Tentukan ruang sementara baru ini dalam parameter TABLESPACE SEMENTARA dari pernyataan ALTER USER.
- Buat indeks dengan pernyataan CREATE INDEX.
- Jatuhkan tablespace ini dengan perintah DROP TABLESPACE. Kemudian gunakan pernyataan ALTER USER untuk mengembalikan tablespace asli sebagai sementara.
Pilih tabel dan kolom yang tepat untuk pengindeksan
Gunakan panduan berikut untuk menentukan kapan membuat indeks.
- Buat indeks jika Anda sering mengambil baris dalam jumlah yang relatif kecil (kurang dari 15%) dari tabel besar. Persentase ini sangat bergantung pada kecepatan relatif pemindaian tabel dan seberapa mengelompokkan data baris dalam kunci indeks. Semakin tinggi kecepatan penelusuran, semakin rendah persentasenya; semakin banyak data baris yang terkelompok, semakin tinggi persentasenya.
- Kolom indeks yang digunakan dalam penggabungan untuk meningkatkan kinerja penggabungan beberapa tabel.
- Indeks dibuat secara otomatis berdasarkan kunci utama dan unik.
- Tabel kecil tidak perlu diindeks. Jika Anda memperhatikan bahwa waktu eksekusi kueri telah meningkat secara signifikan, kemungkinan besar waktu tersebut menjadi lama.
- nilai pada kolom tersebut relatif unik;
- rentang nilai yang besar (cocok untuk indeks reguler);
- rentang nilai yang kecil (cocok untuk indeks bit);
- kolom yang sangat jarang (banyak nilai yang tidak ditentukan dan "kosong"), tetapi sebagian besar kuerinya berisi baris yang bermakna. Dalam hal ini, perbandingan yang cocok dengan semua nilai bukan nol lebih disukai:
WHERE COL_X > -9,99 *power(10, 125) daripada
DIMANA COL_X BUKAN NULL Ini karena kasus pertama menggunakan indeks COL_X (dengan asumsi kolom COL_X adalah tipe numerik).
Batasi jumlah indeks per tabel
Semakin banyak indeks, semakin tinggi biaya overhead saat memodifikasi tabel. Ketika baris ditambahkan atau dihapus, semua indeks pada tabel diperbarui. Saat kolom diperbarui, semua indeks yang berpartisipasi juga harus diperbarui.
Dalam hal indeks, Anda perlu mempertimbangkan peningkatan kinerja untuk kueri versus penalti kinerja untuk pembaruan. Misalnya, jika tabel hanya bersifat baca-saja, Anda dapat menggunakan indeks secara ekstensif; namun jika tabel sering diupdate, disarankan untuk meminimalkan penggunaan indeks.
Pilih urutan kolom dalam indeks gabungan
Meskipun kolom dapat ditentukan dalam urutan apa pun dalam pernyataan CREATE INDEX, urutan kolom dalam pernyataan CREATE INDEX dapat memengaruhi kinerja kueri. Secara umum, kolom yang paling sering digunakan dicantumkan pertama dalam indeks. Anda dapat membuat indeks gabungan (menggunakan beberapa kolom), yang dapat digunakan untuk menanyakan semua kolom yang disertakan dalam indeks atau hanya beberapa saja.
Kumpulkan statistik untuk penggunaan indeks yang tepat
Indeks dapat digunakan secara lebih efektif jika database mengumpulkan dan memelihara statistik tentang tabel yang digunakan dalam kueri. Anda dapat mengumpulkan statistik selama pembuatan indeks dengan menentukan kata kunci COMPUTE STATISTICS dalam pernyataan CREATE INDEX. Karena data terus diperbarui dan distribusi nilai berubah, statistik harus diperbarui secara berkala menggunakan prosedur DBMS_STATS.GATHER_TABLE_STATISTICS dan DBMS_STATS.GATHER_SCHEMA_STATISTICS.
Hancurkan indeks yang tidak perlu
Indeks dihapus dalam kasus berikut:
- jika menggunakan indeks tidak meningkatkan kinerja kueri. Situasi ini terjadi jika tabel terlalu kecil atau jika tabel memiliki banyak baris, namun hanya sedikit yang merupakan entri indeks;
- jika permintaan proposal Anda tidak menggunakan indeks;
- jika indeks juga dihilangkan sebelum dibangun kembali.
Artikel ini membahas indeks dan perannya dalam mengoptimalkan waktu eksekusi kueri. Bagian pertama artikel ini membahas berbagai bentuk indeks dan cara menyimpannya. Selanjutnya, kita memeriksa tiga pernyataan Transact-SQL utama yang digunakan untuk bekerja dengan indeks: CREATE INDEX, ALTER INDEX, dan DROP INDEX. Kemudian fragmentasi indeks dampaknya terhadap kinerja sistem dipertimbangkan. Bagian ini kemudian memberikan beberapa pedoman umum untuk membuat indeks dan menjelaskan beberapa jenis indeks khusus.
Informasi Umum
Sistem basis data biasanya menggunakan indeks untuk menyediakan akses cepat ke data relasional. Indeks adalah struktur data fisik terpisah yang memungkinkan akses cepat ke satu atau lebih baris data. Oleh karena itu, penyetelan indeks yang tepat merupakan aspek kunci dalam meningkatkan kinerja kueri.
Indeks database dalam banyak hal mirip dengan indeks (indeks alfabet) sebuah buku. Ketika kita perlu mencari topik dalam sebuah buku dengan cepat, pertama-tama kita melihat indeks di halaman buku mana topik tersebut dibahas, lalu segera membuka halaman yang diinginkan. Demikian pula, ketika mencari baris tertentu dalam tabel, Mesin Database mengakses indeks untuk menemukan lokasi fisiknya.
Namun ada dua perbedaan signifikan antara indeks buku dan indeks database:
Pembaca buku memiliki kesempatan untuk memutuskan sendiri apakah akan menggunakan indeks dalam setiap kasus atau tidak. Pengguna database tidak memiliki kesempatan ini, dan keputusan ini dibuat untuknya oleh komponen sistem yang disebut pengoptimal kueri. (Pengguna dapat memanipulasi penggunaan indeks melalui petunjuk indeks, namun petunjuk ini direkomendasikan untuk digunakan hanya dalam sejumlah kasus khusus yang terbatas.)
Indeks untuk buku kerja tertentu dibuat bersama dengan buku kerja, setelah itu tidak lagi diubah. Artinya indeks topik tertentu akan selalu mengarah ke nomor halaman yang sama. Sebaliknya, indeks database dapat berubah setiap kali data terkait berubah.
Jika tabel tidak memiliki indeks yang sesuai, sistem menggunakan metode pemindaian tabel untuk mengambil baris. Ekspresi pemindaian tabel berarti bahwa sistem secara berurutan mengambil dan memeriksa setiap baris tabel (dari yang pertama hingga yang terakhir), dan menempatkan baris tersebut dalam kumpulan hasil jika kondisi pencarian dalam klausa WHERE terpenuhi. Dengan demikian, semua baris diambil sesuai dengan lokasi fisiknya di memori. Cara ini kurang efisien dibandingkan akses menggunakan indeks, seperti dijelaskan di bawah.
Indeks disimpan dalam struktur database tambahan yang disebut halaman indeks. Untuk setiap baris yang diindeks ada entri indeks, yang disimpan di halaman indeks. Setiap elemen indeks terdiri dari kunci indeks dan indeks. Inilah sebabnya mengapa elemen indeks jauh lebih pendek daripada baris tabel yang ditunjuknya. Oleh karena itu, jumlah elemen indeks pada setiap halaman indeks jauh lebih besar dibandingkan jumlah baris pada halaman data.
Properti indeks ini sangat penting karena jumlah operasi I/O yang diperlukan untuk melintasi halaman indeks jauh lebih sedikit daripada jumlah operasi I/O yang diperlukan untuk melintasi halaman data terkait. Dengan kata lain, pemindaian tabel mungkin memerlukan lebih banyak operasi I/O dibandingkan pemindaian indeks tabel.
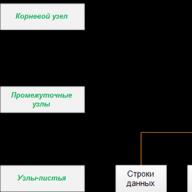
Indeks Mesin Basis Data dibuat menggunakan struktur data pohon B+. Pohon B+ memiliki struktur pohon di mana semua simpul paling bawah mempunyai jumlah tingkat yang sama dari puncak (simpul akar) pohon. Properti ini dipertahankan bahkan ketika data ditambahkan atau dihapus dari kolom yang diindeks.
Gambar di bawah menunjukkan struktur pohon B+ untuk tabel Karyawan dan akses langsung ke baris dalam tabel tersebut dengan nilai 25348 untuk kolom Id. (Kami berasumsi bahwa tabel Karyawan diindeks oleh kolom Id.) Anda juga dapat melihat pada gambar ini bahwa pohon B+ terdiri dari simpul akar, simpul pohon, dan nol atau lebih simpul perantara:
Anda dapat mencari pohon ini untuk nilai 25348 sebagai berikut. Dimulai dari akar pohon, ia mencari nilai kunci terkecil yang lebih besar atau sama dengan nilai yang diinginkan. Jadi, pada node akar, nilainya akan menjadi 29346, sehingga transisi dilakukan ke node perantara yang terkait dengan nilai ini. Dalam node ini, nilai 28559 memenuhi persyaratan yang ditentukan, akibatnya transisi dilakukan ke node pohon yang terkait dengan nilai ini. Node ini berisi nilai yang diinginkan 25348. Setelah menentukan indeks yang diperlukan, kita dapat mengekstrak barisnya dari tabel data menggunakan pointer yang sesuai. (Pendekatan alternatif yang setara adalah dengan mencari nilai yang kurang dari atau sama dengan indeks.)
Pencarian terindeks biasanya merupakan metode yang disukai untuk mencari tabel dengan jumlah baris yang banyak karena keuntungannya yang jelas. Dengan menggunakan pencarian terindeks, kita dapat menemukan baris mana pun dalam tabel dalam waktu yang sangat singkat hanya dengan menggunakan beberapa operasi I/O. Dan pencarian berurutan (yaitu memindai tabel dari baris pertama hingga terakhir) membutuhkan lebih banyak waktu, semakin jauh jarak baris yang diperlukan.
Di bagian berikut, kita akan melihat dua tipe indeks yang ada, terkluster dan tidak terkluster, serta mempelajari cara membuat indeks.
Indeks Berkelompok
Indeks berkerumun menentukan urutan fisik data dalam tabel. Mesin Basis Data memungkinkan Anda membuat hanya satu indeks berkerumun untuk sebuah tabel, karena Baris-baris tabel tidak dapat diurutkan secara fisik dengan lebih dari satu cara. Pencarian menggunakan indeks berkerumun dilakukan dari simpul akar pohon B+ menuju simpul-simpul di pohon yang dihubungkan bersama dalam daftar tertaut ganda yang disebut rantai halaman.
Properti penting dari indeks berkerumun adalah simpul pohonnya berisi halaman data. (Semua level node indeks terklaster lainnya berisi halaman indeks.) Tabel yang memiliki indeks terklaster yang ditentukan (baik secara eksplisit maupun implisit) disebut tabel terklaster. Struktur pohon B+ dari indeks berkerumun ditunjukkan pada gambar di bawah ini:

Indeks berkerumun dibuat secara default pada setiap tabel yang memiliki kunci utama yang ditentukan oleh batasan kunci utama. Selain itu, setiap indeks berkerumun bersifat unik secara default, yaitu. Dalam kolom yang memiliki indeks berkerumun yang ditentukan, setiap nilai data hanya dapat muncul satu kali. Jika indeks berkerumun dibuat pada kolom yang berisi nilai duplikat, sistem database menerapkan ketidakjelasan dengan menambahkan pengidentifikasi empat byte ke baris yang berisi nilai duplikat.
Indeks berkerumun memberikan akses data yang sangat cepat ketika kueri mencari rentang nilai.
Indeks yang tidak berkerumun
Struktur indeks nonclustered sama persis dengan indeks clustered, namun dengan dua perbedaan penting:
indeks yang tidak berkerumun tidak mengubah urutan fisik baris tabel;
Halaman simpul indeks yang tidak dikelompokkan terdiri dari kunci indeks dan bookmark.
Jika Anda menentukan satu atau lebih indeks noncluster pada tabel, urutan fisik baris tabel tidak akan diubah. Untuk setiap indeks noncluster, Mesin Database membuat struktur indeks tambahan yang disimpan di halaman indeks. Struktur pohon B+ dari indeks non-cluster ditunjukkan pada gambar di bawah ini:

Penanda dalam indeks noncluster menunjukkan di mana baris yang sesuai dengan kunci indeks berada. Komponen penanda kunci indeks dapat terdiri dari dua jenis, bergantung pada apakah tabel tersebut merupakan tabel berkerumun atau heap. (Dalam terminologi SQL Server, heap adalah tabel tanpa indeks berkerumun.) Jika ada indeks berkerumun, tab indeks tidak berkerumun memperlihatkan pohon B+ dari indeks berkerumun tabel. Jika tabel tidak memiliki indeks berkerumun, penandanya sama pengidentifikasi baris (RID - Pengidentifikasi Baris), terdiri dari tiga bagian: alamat file tempat tabel disimpan, alamat blok fisik (halaman) tempat baris disimpan, dan offset baris dalam halaman.
Seperti disebutkan sebelumnya, pencarian data menggunakan indeks noncluster dapat dilakukan dengan dua cara berbeda, bergantung pada jenis tabelnya:
heap - melintasi struktur pencarian indeks non-cluster, setelah itu baris diambil menggunakan pengidentifikasi baris;
tabel berkerumun - penjelajahan pencarian dari struktur indeks yang tidak berkerumun diikuti dengan penjelajahan indeks berkerumun yang sesuai.
Dalam kedua kasus tersebut, jumlah operasi I/O cukup besar, jadi Anda harus merancang indeks noncluster dengan hati-hati, dan menggunakannya hanya jika Anda yakin bahwa penggunaannya akan meningkatkan kinerja secara signifikan.
Bahasa dan indeks Transact-SQL
Sekarang kita sudah familiar dengan struktur fisik indeks, di bagian ini kita akan melihat cara membuat, memodifikasi, dan menghapus indeks, serta cara memperoleh informasi fragmentasi indeks dan mengedit informasi indeks. Semua ini akan mempersiapkan kita untuk diskusi selanjutnya tentang penggunaan indeks untuk meningkatkan kinerja sistem.
Membuat Indeks
Indeks pada tabel dibuat menggunakan pernyataan BUAT INDEKS. Instruksi ini memiliki sintaks berikut:
BUAT INDEX nama_indeks PADA nama_tabel (kolom1 ,...) [ TERMASUK (nama_kolom [ ,... ]) ] [[, ] PAD_INDEX = (ON | OFF)] [[, ] DROP_EXISTING = (ON | OFF)] [[ , ] SORT_IN_TEMPDB = (ON | OFF)] [[, ] IGNORE_DUP_KEY = (ON | OFF)] [[, ] ALLOW_ROW_LOCKS = (ON | OFF)] [[, ] ALLOW_PAGE_LOCKS = (ON | OFF)] [[, ] STATISTICS_NORECOMPUTE = (ON | OFF)] [[, ] ONLINE = (ON | OFF)]] Konvensi sintaksis
Parameter index_name menentukan nama indeks yang akan dibuat. Indeks dapat dibuat pada satu atau lebih kolom dari satu tabel, yang diidentifikasi dengan parameter table_name. Kolom tempat indeks dibuat ditentukan oleh parameter kolom1. Akhiran numerik dari parameter ini menunjukkan bahwa indeks dapat dibuat pada beberapa kolom tabel. Mesin Basis Data juga mendukung pembuatan indeks pada tampilan.
Anda dapat mengindeks kolom tabel mana pun. Artinya kolom yang berisi nilai tipe data VARBINARY(max), BIGINT, dan SQL_VARIANT juga dapat diindeks.
Indeksnya bisa sederhana atau gabungan. Indeks sederhana dibuat pada satu kolom, sedangkan indeks gabungan dibuat pada beberapa kolom. Indeks gabungan memiliki batasan tertentu terkait ukuran dan jumlah kolomnya. Sebuah indeks dapat memiliki maksimal 900 byte dan maksimal 16 kolom.
Parameter UNIK menetapkan bahwa kolom yang diindeks hanya dapat berisi nilai bernilai tunggal (yaitu, tidak berulang). Dalam indeks komposit bernilai tunggal, yang unik harus berupa kombinasi nilai semua kolom di setiap baris. Jika kata kunci UNIK tidak ditentukan, maka nilai duplikat di kolom yang diindeks diperbolehkan.
Parameter TERKUMPULAN menentukan indeks berkerumun, dan Parameter TIDAK TERMASUK(default) menetapkan bahwa indeks tidak mengubah urutan baris dalam tabel. Mesin Basis Data mengizinkan maksimal 249 indeks noncluster dalam satu tabel.
Mesin Basis Data telah ditingkatkan untuk mendukung indeks dengan urutan nilai kolom menurun. Parameter ASC setelah nama kolom menentukan bahwa indeks dibuat dengan urutan nilai kolom menaik, dan parameter DESC menentukan urutan nilai kolom indeks dalam urutan menurun. Hal ini memberikan fleksibilitas yang lebih besar dalam penggunaan indeks. Dengan urutan menurun, Anda harus membuat indeks komposit pada kolom yang nilainya diurutkan berlawanan arah.
TERMASUK parameter Memungkinkan Anda menentukan kolom bukan kunci yang ditambahkan ke halaman simpul indeks noncluster. Nama kolom dalam daftar INCLUDE tidak boleh diulang, dan kolom tidak dapat digunakan sebagai kolom kunci dan bukan kunci.
Untuk benar-benar memahami kegunaan parameter INCLUDE, Anda perlu memahami apa itu parameter meliputi indeks. Jika semua kolom kueri disertakan dalam indeks, Anda bisa mendapatkan peningkatan kinerja yang signifikan karena Pengoptimal kueri dapat menemukan semua nilai kolom di seluruh halaman indeks tanpa mengakses data dalam tabel. Kemampuan ini disebut indeks penutup atau kueri penutup. Oleh karena itu, menyertakan kolom non-kunci tambahan di halaman simpul indeks non-cluster akan memungkinkan Anda memperoleh lebih banyak kueri cakupan dan meningkatkan kinerjanya secara signifikan.
Parameter FILLFACTOR menentukan persentase setiap halaman indeks yang harus diisi pada saat pembuatan indeks. Nilai parameter FILLFACTOR dapat diatur dalam rentang 1 hingga 100. Dengan nilai n=100, setiap halaman indeks terisi hingga 100%, yaitu. halaman node yang ada maupun halaman non-node tidak akan memiliki ruang kosong untuk menyisipkan baris baru. Oleh karena itu, disarankan untuk menggunakan nilai ini hanya untuk tabel statis. (Nilai default, n=0, berarti halaman simpul indeks penuh dan setiap halaman perantara berisi ruang kosong untuk satu entri.)
Jika parameter FILLFACTOR diatur ke nilai antara 1 dan 99, halaman simpul dari struktur indeks yang dibuat akan berisi ruang kosong. Semakin besar nilai n, semakin sedikit ruang kosong yang ada pada halaman node indeks. Misalnya, dengan n=60, setiap halaman simpul indeks akan memiliki 40% ruang kosong untuk penyisipan baris indeks di masa mendatang. (Baris indeks disisipkan menggunakan pernyataan INSERT atau UPDATE.) Dengan demikian, nilai n=60 akan masuk akal untuk tabel yang datanya cukup sering berubah. Untuk nilai FILLFACTOR antara 1 dan 99, halaman indeks perantara berisi ruang kosong untuk masing-masing satu entri.
Setelah indeks dibuat, nilai FILLFACTOR tidak didukung selama penggunaan. Dengan kata lain, ini hanya menunjukkan jumlah ruang yang dicadangkan dengan data yang tersedia saat mengatur persentase ruang kosong. Untuk mengembalikan parameter FILLFACTOR ke nilai aslinya, gunakan pernyataan ALTER INDEX.
Parameter PAD_INDEX terkait erat dengan parameter FILLFACTOR. Parameter FILLFACTOR pada dasarnya menentukan jumlah ruang kosong sebagai persentase dari total ukuran halaman node indeks. Dan parameter PAD_INDEX menetapkan bahwa nilai parameter FILLFACTOR berlaku untuk halaman indeks dan halaman data dalam indeks.
Parameter DROP_EXISTING Memungkinkan Anda meningkatkan kinerja saat mereproduksi indeks berkerumun pada tabel yang juga memiliki indeks non-kluster. Untuk informasi lebih lanjut, lihat bagian "Membangun Kembali Indeks" di bawah.
Parameter SORT_IN_TEMPDB digunakan untuk menempatkan data dari operasi penyortiran perantara yang digunakan saat membuat indeks ke dalam database sistem tempdb. Hal ini dapat meningkatkan kinerja jika tempdb terletak pada disk yang berbeda dari data.
Parameter IGNORE_DUP_KEY Mengizinkan sistem mengabaikan upaya memasukkan nilai duplikat ke dalam kolom yang diindeks. Opsi ini hanya boleh digunakan untuk menghindari pembatalan transaksi yang sudah berjalan lama ketika pernyataan INSERT menyisipkan data duplikat ke dalam kolom yang diindeks. Ketika opsi ini diaktifkan, ketika pernyataan INSERT mencoba memasukkan baris ke dalam tabel yang melanggar keunikan indeks, sistem database hanya mengeluarkan peringatan alih-alih membuat seluruh pernyataan menjadi crash. Dalam hal ini, Mesin Basis Data tidak menyisipkan baris dengan nilai kunci duplikat, namun mengabaikannya dan menambahkan baris yang benar. Jika parameter ini tidak disetel, maka eksekusi seluruh instruksi akan berhenti secara tidak normal.
Kapan parameter ALLOW_ROW_LOCKS diaktifkan (diaktifkan), sistem menerapkan penguncian baris. Begitu pula saat diaktifkan parameter ALLOW_PAGE_LOCKS, sistem menerapkan penguncian halaman selama akses bersamaan. Parameter STATISTICS_NORECOMPUTE menentukan status penghitungan ulang statistik secara otomatis untuk indeks yang ditentukan.
Diaktifkan Parameter ONLINE memungkinkan Anda membuat, membuat ulang, dan menghapus indeks dalam mode dialog. Opsi ini memungkinkan Anda untuk secara bersamaan mengubah data tabel utama atau indeks berkerumun dan indeks terkait apa pun sambil mengubah indeks. Misalnya, saat indeks berkerumun sedang dibuat ulang, Anda dapat terus memperbarui datanya dan menjalankan kueri pada data tersebut.
Parameter AKTIF membuat indeks yang ditentukan pada grup file default (nilai default) atau grup file yang ditentukan (nilai grup_file).
Contoh di bawah ini menunjukkan cara membuat indeks non-cluster pada kolom Id pada tabel Karyawan:
GUNAKAN SampleDb; BUAT INDEKS ix_empid PADA Karyawan(Id);
Pembuatan indeks komposit bernilai tunggal ditunjukkan pada contoh di bawah ini:
GUNAKAN SampleDb; BUAT INDEKS UNIK ix_empid_prnu PADA Works_on (EmpId, ProjectNumber) DENGAN FILLFACTOR= 80;
Dalam contoh ini, nilai di setiap kolom harus berupa satu digit. Saat indeks dibuat, 80% ruang di setiap halaman node indeks terisi.
Anda tidak dapat membuat indeks unik pada kolom jika kolom tersebut berisi nilai duplikat. Indeks seperti itu hanya dapat dibuat jika setiap nilai (termasuk nilai NULL) muncul tepat satu kali dalam kolom. Selain itu, segala upaya untuk memasukkan atau mengubah nilai data yang ada ke dalam kolom yang disertakan dalam indeks unik yang ada akan ditolak oleh sistem jika nilainya diduplikasi.
Mendapatkan informasi tentang fragmentasi indeks
Selama masa pakai indeks, indeks dapat menjadi terfragmentasi, sehingga proses penyimpanan data di halaman indeks menjadi tidak efisien. Ada dua jenis fragmentasi indeks: fragmentasi internal dan fragmentasi eksternal. Fragmentasi internal menentukan jumlah data yang disimpan di setiap halaman, sedangkan fragmentasi eksternal terjadi ketika halaman berada di luar urutan logis.
Untuk memperoleh informasi tentang fragmentasi indeks internal, tampilan manajemen dinamis DMV disebut sys.dm_db_index_physical_stats. DMV ini mengembalikan informasi tentang volume dan fragmentasi data dan indeks halaman tertentu. Untuk setiap halaman, satu baris dikembalikan untuk setiap tingkat pohon B+. Dengan menggunakan DMV ini, Anda dapat memperoleh informasi tentang tingkat fragmentasi baris di halaman data, berdasarkan informasi tersebut Anda dapat memutuskan apakah akan mengatur ulang data.
Penggunaan tampilan sys.dm_db_index_physical_stats ditunjukkan pada contoh di bawah ini. (Sebelum menjalankan contoh batch, Anda harus menghapus semua indeks yang ada di tabel Works_on. Untuk menghapus indeks, gunakan pernyataan DROP INDEX, yang akan ditampilkan nanti.)
GUNAKAN SampleDb; DEKLARASIKAN @dbId INT; DEKLARASIKAN @tabId INT; DEKLARASIKAN @indId INT; SET @dbId = DB_ID("SampleDb"); SET @tabId = OBJECT_ID("Karyawan"); PILIH avg_fragmentation_in_percent, avg_page_space_used_in_percent DARI sys.dm_db_index_physical_stats (@dbId, @tabId, NULL, NULL, NULL);
Seperti yang Anda lihat dari contoh, tampilan sys.dm_db_index_physical_stats memiliki lima parameter. Tiga parameter pertama masing-masing menentukan ID database, tabel, dan indeks saat ini. Parameter keempat menentukan ID partisi, dan parameter terakhir menentukan tingkat pemindaian yang digunakan untuk memperoleh informasi statistik. (Nilai default untuk parameter tertentu dapat ditentukan menggunakan nilai NULL.)
Kolom terpenting dalam tampilan ini adalah kolom avg_fragmentation_in_percent dan avg_page_space_used_in_percent. Yang pertama menunjukkan tingkat rata-rata fragmentasi dalam persentase, dan yang kedua menentukan jumlah ruang yang ditempati dalam persentase.
Mengedit Informasi Indeks
Setelah Anda memahami informasi fragmentasi indeks seperti yang dibahas di bagian sebelumnya, Anda dapat mengedit informasi ini dan informasi indeks lainnya menggunakan alat sistem berikut:
tampilan direktori sys.indexes;
tampilan katalog sys.index_columns;
prosedur sistem sp_helpindex;
fungsi properti objek;
Lingkungan manajemen SQL Server Management Studio;
tampilan manajemen dinamis DMV sys.dm_db_index_usage_stats;
Tampilan manajemen dinamis DMV sys.dm_db_missing_index_details.
Tampilan katalog sys.indexes berisi satu baris untuk setiap indeks dan satu baris untuk setiap tabel tanpa indeks berkerumun. Kolom terpenting pada tampilan katalog ini adalah kolom object_id, name, dan index_id. Kolom object_id berisi nama objek database yang memiliki indeks, dan kolom name dan index_id masing-masing berisi nama dan ID indeks tersebut.
Tampilan katalog sys.index_columns berisi baris untuk setiap kolom yang merupakan bagian dari indeks atau heap. Informasi ini dapat digunakan bersama dengan informasi yang diperoleh melalui tampilan katalog sys.indexes untuk memperoleh informasi tambahan tentang properti indeks yang ditentukan.
Prosedur sistem sp_helpindex mengembalikan informasi tentang indeks tabel serta informasi statistik untuk kolom. Prosedur ini memiliki sintaks berikut:
sp_helpindex [@db_object = ] "nama"
Di sini variabel @db_object mewakili nama tabel.
Sehubungan dengan indeks, fungsi properti objek memiliki dua properti: IsIndexed dan IsIndexable. Properti pertama memberikan informasi tentang apakah tabel atau tampilan memiliki indeks, dan properti kedua menunjukkan apakah tabel atau tampilan dapat diindeks.
Untuk mengedit informasi indeks yang ada menggunakan SQL Server Management Studio, pilih database yang diinginkan di folder Databases, perluas node Tabel, dan di node tersebut, perluas tabel yang diinginkan dan folder Indeksnya. Folder Indeks tabel akan menampilkan daftar semua indeks yang ada untuk tabel tersebut. Mengklik dua kali pada indeks akan membuka kotak dialog Index Properties dengan properti indeks tersebut. (Anda juga dapat membuat indeks baru atau menghapus indeks yang sudah ada menggunakan Management Studio.)
Pertunjukan sys.dm_db_index_usage_stats mengembalikan hitungan berbagai jenis operasi indeks dan terakhir kali setiap jenis operasi dilakukan. Setiap operasi pencarian, pencarian, atau pembaruan terpisah pada indeks tertentu dalam satu kueri dianggap sebagai penggunaan indeks dan menambah penghitung terkait di DMV tersebut sebanyak satu. Dengan cara ini, Anda bisa mendapatkan informasi umum tentang seberapa sering suatu indeks digunakan, sehingga Anda bisa menggunakannya untuk menentukan indeks mana yang lebih banyak digunakan dan mana yang lebih sedikit.
Pertunjukan sys.dm_db_missing_index_details Mengembalikan informasi rinci tentang kolom tabel yang tidak ada indeksnya. Kolom terpenting DMV ini adalah kolom index_handle dan object_id. Nilai di kolom pertama mengidentifikasi indeks spesifik yang hilang, dan nilai di kolom kedua mengidentifikasi tabel yang indeksnya hilang.
Mengubah indeks
Mesin Basis Data adalah salah satu dari sedikit sistem basis data yang mendukung pernyataan tersebut MENGUBAH INDEKS. Pernyataan ini dapat digunakan untuk melakukan operasi pemeliharaan indeks. Sintaks pernyataan ALTER INDEX sangat mirip dengan sintaks pernyataan CREATE INDEX. Dengan kata lain, pernyataan ini memungkinkan Anda untuk mengubah nilai parameter ALLOW_ROW_LOCKS, ALLOW_PAGE_LOCKS, IGNORE_DUP_KEY, dan STATISTICS_NORECOMPUTE yang dijelaskan sebelumnya dalam pernyataan CREATE INDEX.
Selain opsi di atas, pernyataan ALTER INDEX mendukung tiga opsi lain:
parameter MEMBANGUN KEMBALI, digunakan untuk membuat ulang indeks;
ORGANISASI ULANG parameter, digunakan untuk mengatur ulang halaman simpul indeks;
NONAKTIFKAN parameter, digunakan untuk menonaktifkan indeks. Ketiga opsi ini dibahas dalam subbagian berikut.
Membangun kembali indeks
Setiap perubahan pada data yang menggunakan pernyataan INSERT, UPDATE, atau DELETE dapat mengakibatkan fragmentasi data. Jika data ini diindeks, maka fragmentasi indeks juga mungkin terjadi, dengan informasi indeks tersebar di berbagai halaman fisik. Akibat fragmentasi data indeks, Mesin Basis Data mungkin terpaksa melakukan operasi pembacaan data tambahan, sehingga mengurangi kinerja sistem secara keseluruhan. Dalam hal ini, Anda perlu MEMBANGUN KEMBALI semua indeks yang terfragmentasi.
Hal ini dapat dilakukan dengan dua cara:
melalui parameter REBUILD dari pernyataan ALTER INDEX;
melalui parameter DROP_EXISTING dari pernyataan CREATE INDEX.
Parameter REBUILD digunakan untuk membangun kembali indeks. Jika Anda menentukan SEMUA alih-alih nama indeks untuk parameter ini, semua indeks pada tabel akan dibuat ulang. (Dengan mengizinkan indeks dibuat ulang secara dinamis, Anda tidak perlu menghapus dan membuatnya kembali.)
Opsi DROP_EXISTING dari pernyataan CREATE INDEX dapat meningkatkan kinerja ketika membuat ulang indeks berkerumun pada tabel yang juga memiliki indeks noncluster. Ini menentukan bahwa indeks berkerumun atau tidak berkerumun yang ada harus dihilangkan dan indeks yang ditentukan harus dibuat ulang. Seperti disebutkan sebelumnya, setiap indeks non-cluster pada tabel cluster berisi nilai-nilai yang sesuai dari indeks cluster tabel di node pohonnya. Karena alasan ini, ketika Anda menjatuhkan indeks berkerumun pada tabel, Anda harus membuat ulang semua indeks yang tidak berkerumun. Menggunakan parameter DROP_EXISTING menghindari keharusan membuat ulang indeks noncluster lagi.
Opsi DROP_EXISTING lebih kuat daripada opsi REBUILD karena lebih fleksibel dan menyediakan beberapa opsi, seperti mengubah kolom yang membentuk indeks dan mengubah indeks yang tidak berkerumun menjadi berkerumun.
Menata Ulang Halaman Node Indeks
Parameter REORGANIZE dari pernyataan ALTER INDEX menata ulang halaman node dalam indeks yang ditentukan sehingga urutan fisik halaman sesuai dengan urutan logisnya, dari kiri ke kanan. Ini menghilangkan sejumlah fragmentasi indeks, sehingga meningkatkan kinerja indeks.
Nonaktifkan indeks
Opsi DISABLE menonaktifkan indeks yang ditentukan. Indeks yang dinonaktifkan tidak dapat digunakan sampai diaktifkan kembali. Perhatikan bahwa indeks yang dinonaktifkan tidak berubah ketika ada perubahan pada data terkait. Oleh karena itu, untuk menggunakan kembali indeks yang dinonaktifkan, indeks tersebut harus dibuat ulang sepenuhnya. Untuk mengaktifkan indeks yang dinonaktifkan, gunakan opsi REBUILD dari pernyataan ALTER TABLE.
Ketika indeks berkerumun pada tabel dinonaktifkan, data tabel tidak akan dapat diakses karena semua halaman data tabel dengan indeks berkerumun disimpan di simpul pohonnya.
Menghapus dan mengganti nama indeks
Untuk menghapus indeks di database saat ini, gunakan instruksi DROP INDEX. Perhatikan bahwa menghapus indeks berkerumun pada tabel bisa menjadi operasi yang sangat intensif sumber daya karena Semua indeks non-cluster perlu dibuat ulang. (Semua indeks yang tidak berkerumun menggunakan kunci indeks dari indeks berkerumun sebagai penunjuk di halaman simpulnya.) Menggunakan pernyataan DROP INDEX untuk menghapus indeks diilustrasikan dalam contoh di bawah ini:
GUNAKAN SampleDb; DROP INDEX ix_empid PADA Karyawan;
Instruksi DROP INDEX memiliki tambahan Pindah ke parameter, yang artinya sama dengan parameter ON pada pernyataan CREATE INDEX. Dengan kata lain, Anda dapat menggunakan parameter ini untuk menentukan tempat memindahkan baris data yang ada di halaman simpul indeks berkerumun. Data dipindahkan ke lokasi baru sebagai heap. Anda dapat menentukan grup file default atau grup file bernama untuk lokasi penyimpanan data baru.
Pernyataan DROP INDEX tidak dapat digunakan untuk menghapus indeks yang dibuat secara implisit oleh sistem karena batasan integritas, seperti indeks PRIMARY KEY dan UNIQUE. Untuk menghapus indeks tersebut, Anda harus menghapus batasan yang sesuai.
Indeks dapat diganti namanya menggunakan prosedur sistem sp_rename.
Indeks juga dapat dibuat, dimodifikasi, dan dihapus di Management Studio dengan menggunakan Diagram Database atau Object Explorer. Namun cara termudah adalah dengan menggunakan folder Indexes pada tabel yang diperlukan. Mengelola indeks di Management Studio mirip dengan mengelola tabel di Management Studio.
Meskipun Mesin Basis Data tidak memberikan batasan praktis pada jumlah indeks, ada beberapa alasan mengapa Anda harus membatasi jumlahnya. Pertama, setiap indeks memerlukan sejumlah ruang disk, sehingga ada kemungkinan jumlah halaman indeks database melebihi jumlah halaman data dalam database. Kedua, tidak seperti manfaat menggunakan indeks untuk mengambil data, memasukkan dan menghapus data tidak memberikan manfaat karena kebutuhan untuk memelihara indeks. Semakin banyak indeks yang dimiliki suatu tabel, semakin banyak pekerjaan yang diperlukan untuk mengatur ulang tabel tersebut. Sebagai aturan umum, sebaiknya pilih indeks untuk kueri yang sering ditanyakan dan kemudian evaluasi penggunaannya.
Beberapa pedoman untuk membuat dan menggunakan indeks disediakan di bagian ini. Rekomendasi berikut hanyalah aturan umum. Pada akhirnya, efektivitasnya akan bergantung pada bagaimana database digunakan dalam praktiknya dan jenis kueri yang paling sering dieksekusi. Mengindeks kolom yang tidak akan pernah digunakan tidak akan ada gunanya.
Indeks dan Kondisi Klausul WHERE
Jika klausa WHERE dari pernyataan SELECT berisi kondisi pencarian dengan satu kolom, maka indeks harus dibuat pada kolom tersebut. Hal ini terutama direkomendasikan pada kondisi selektivitas tinggi. Yang dimaksud dengan selektivitas suatu kondisi adalah rasio jumlah baris yang memenuhi kondisi terhadap jumlah total baris dalam tabel. Selektivitas yang tinggi berhubungan dengan nilai yang lebih rendah dari rasio ini. Pemrosesan pencarian menggunakan kolom yang diindeks akan paling berhasil bila selektivitas kondisi kurang dari 5%.
Kolom tidak boleh diindeks jika tingkat selektivitas kondisi konstan pada 80% atau lebih. Dalam hal ini, halaman indeks akan memerlukan operasi I/O tambahan, yang akan mengurangi penghematan waktu yang dicapai dengan menggunakan indeks. Dalam hal ini, akan lebih cepat melakukan pencarian dengan memindai tabel, yang biasanya dipilih oleh pengoptimal kueri, sehingga menjadikan indeks tidak berguna.
Jika kondisi pencarian dari kueri yang sering digunakan berisi operator AND, cara terbaik Anda adalah membuat indeks gabungan pada semua kolom tabel yang ditentukan dalam klausa WHERE pada pernyataan SELECT. Pembuatan indeks komposit tersebut ditunjukkan pada contoh di bawah ini:
Contoh ini membuat indeks gabungan pada semua kolom klausa WHERE. Dalam kueri ini, dua ketentuan di-AND bersama-sama, jadi Anda harus membuat indeks gabungan yang tidak dikelompokkan pada kedua kolom dalam ketentuan ini.
Indeks dan operator gabungan
Untuk operasi penggabungan, disarankan untuk membuat indeks pada setiap kolom yang digabungkan. Kolom yang digabungkan sering kali mewakili kunci utama dari satu tabel dan kunci asing terkait dari tabel lain. Jika Anda menentukan batasan integritas PRIMARY KEY dan FOREIGN KEY pada kolom gabungan yang sesuai, Anda sebaiknya hanya membuat indeks noncluster pada kolom kunci asing karena sistem secara implisit akan membuat indeks berkerumun pada kolom kunci utama.
Contoh di bawah ini menunjukkan cara membuat indeks yang akan digunakan jika Anda memiliki kueri dengan operasi gabungan dan filter tambahan:
Meliputi indeks
Seperti disebutkan sebelumnya, menyertakan semua kolom kueri dalam indeks dapat meningkatkan performa kueri secara signifikan. Pembuatan indeks seperti itu, yang disebut meliputi, ditunjukkan pada contoh di bawah ini:
GUNAKAN AdventureWorks2012; GO DROP INDEX Orang.Alamat.IX_Address_StateProvinceID; BUAT INDEX ix_address_zip PADA Person.Address(PostalCode) INCLUDE(City, StateProvinceID); GO SELECT City, StateProvinceID DARI Person.Address WHERE PostalCode = 84407;
Contoh ini pertama-tama menghapus indeks IX_Address_StateProvinceID dari tabel Alamat. Indeks baru kemudian dibuat yang mencakup dua kolom tambahan selain kolom Kode Pos. Terakhir, pernyataan SELECT di akhir contoh menunjukkan kueri yang dicakup oleh indeks. Untuk kueri ini, sistem tidak perlu mencari data di halaman data karena pengoptimal kueri dapat menemukan semua nilai kolom di halaman simpul indeks noncluster.
Disarankan untuk menyertakan indeks karena halaman indeks biasanya berisi lebih banyak entri daripada halaman data terkait. Selain itu, untuk menggunakan metode ini, kolom yang difilter harus menjadi kolom kunci pertama dalam indeks.
Indeks pada kolom terhitung
Mesin Basis Data memungkinkan Anda membuat tipe indeks khusus berikut:
tampilan yang diindeks;
indeks yang dapat disaring;
indeks pada kolom terhitung;
indeks yang dipartisi;
indeks persistensi kolom;
indeks XML;
indeks teks lengkap.
Bagian ini membahas kolom terhitung dan indeks terkaitnya.
Kolom terhitung merupakan kolom tabel yang menyimpan hasil perhitungan data tabel. Kolom seperti itu bisa bersifat virtual atau persisten. Kedua jenis kolom ini dibahas pada subbagian berikut.
Kolom terhitung virtual
Kolom terhitung yang tidak memiliki indeks berkerumun yang sesuai adalah kolom logis, yaitu. itu tidak disimpan secara fisik di hard drive. Oleh karena itu, ini dievaluasi setiap kali baris diakses. Penggunaan kolom terhitung virtual ditunjukkan pada contoh di bawah ini:
GUNAKAN SampleDb; BUAT TABEL Pesanan (OrderId INT BUKAN NULL, Harga UANG BUKAN NULL, Jumlah INT BUKAN NULL, Tanggal Pemesanan DATETIME BUKAN NULL, Total SEBAGAI Harga * Jumlah, Tanggal Pengiriman SEBAGAI DATEADD (HARI, 7, tanggal pemesanan));
Tabel Pesanan dalam contoh ini memiliki dua kolom terhitung virtual: total dan tanggal pengiriman. Kolom total dihitung menggunakan dua kolom lainnya, harga dan kuantitas, dan kolom tanggal pengiriman dihitung menggunakan fungsi DATEADD dan kolom tanggal pemesanan.
Kolom terhitung konstan
Mesin Basis Data memungkinkan Anda membuat indeks pada kolom terhitung deterministik yang kolom dasarnya memiliki tipe data yang tepat. (Kolom terhitung dikatakan deterministik jika selalu mengembalikan nilai yang sama untuk data tabel yang sama.)
Kolom terhitung yang diindeks hanya dapat dibuat jika parameter pernyataan SET berikut diatur ke ON (parameter ini memastikan bahwa kolom bersifat deterministik):
QUOTED_IDENTIFIER
CONCAT_NULL_YIELDS_NULL
Selain itu, parameter NUMERIC_ROUNDABORT harus dinonaktifkan.
Jika Anda membuat indeks berkerumun pada kolom terhitung, nilai kolom tersebut akan secara fisik ada di baris tabel terkait karena halaman simpul indeks berkerumun berisi baris data. Contoh berikut membuat indeks berkerumun pada total kolom terhitung dari tabel Pesanan:
GUNAKAN SampleDb; BUAT INDEKS CLUSTERED ix1 PADA Pesanan (Total);
Setelah menjalankan pernyataan CREATE INDEX, kolom total terhitung akan ditampilkan secara fisik di tabel. Ini berarti bahwa semua pembaruan pada kolom dasar kolom terhitung akan menyebabkannya diperbarui.
Kolom dapat dibuat konstan dengan cara lain menggunakan Parameter BERTAHAN. Opsi ini memungkinkan Anda menentukan keberadaan fisik kolom terhitung tanpa membuat indeks berkerumun yang sesuai. Kemampuan ini diperlukan untuk membuat kolom terhitung fisik, yang dibuat pada kolom dengan tipe data perkiraan (float atau real). (Seperti disebutkan sebelumnya, indeks hanya dapat dibuat pada kolom terhitung jika kolom dasarnya memiliki tipe data yang sama.)
Materi kali ini akan membahas tentang objek database tersebut Microsoft SQLServer Bagaimana indeks Anda akan mempelajari apa itu indeks, jenis indeks apa saja, cara membuat, mengoptimalkan, dan menghapusnya.
Apa yang dimaksud dengan indeks dalam database?
Indeks adalah objek database yang merupakan struktur data yang terdiri dari kunci yang dibangun dari satu atau lebih kolom tabel atau tampilan, dan pointer yang memetakan ke tempat penyimpanan data tertentu. Indeks dirancang untuk mengambil baris dari tabel lebih cepat; dengan kata lain, indeks memungkinkan pencarian data dalam tabel dengan cepat, yang sangat meningkatkan kinerja kueri dan aplikasi. Indeks juga dapat digunakan untuk memastikan bahwa baris dalam tabel bersifat unik, sehingga menjamin integritas data.
Jenis Indeks di Microsoft SQL Server
Jenis indeks berikut ini ada di Microsoft SQL Server:
- Berkelompok (Berkelompok) adalah indeks yang menyimpan data tabel yang diurutkan berdasarkan nilai kunci indeks. Sebuah tabel hanya dapat memiliki satu indeks cluster karena datanya hanya dapat diurutkan dalam satu urutan. Jika memungkinkan, setiap tabel harus memiliki indeks berkerumun; jika tabel tidak memiliki indeks berkerumun, tabel tersebut disebut " dalam satu kelompok" Indeks berkerumun dibuat secara otomatis ketika Anda membuat batasan PRIMARY KEY ( kunci utama) dan UNIK jika indeks berkerumun pada tabel belum ditentukan. Jika Anda membuat indeks berkerumun pada tabel ( tumpukan) yang berisi indeks non-cluster, maka semuanya harus dibangun kembali setelah pembuatan.
- Tidak berkerumun (Tidak berkerumun) adalah indeks yang berisi nilai kunci dan penunjuk ke baris data yang berisi nilai kunci tersebut. Sebuah tabel dapat memiliki beberapa indeks yang tidak dikelompokkan. Indeks non-cluster dapat dibuat pada tabel dengan atau tanpa indeks cluster. Jenis indeks inilah yang digunakan untuk meningkatkan kinerja kueri yang sering digunakan, karena indeks non-cluster menyediakan pencarian cepat dan akses ke data berdasarkan nilai kunci;
- Dapat disaring (Tersaring) adalah indeks noncluster yang dioptimalkan yang menggunakan predikat filter untuk mengindeks subset baris dalam tabel. Jika dirancang dengan baik, jenis indeks ini dapat meningkatkan kinerja kueri dan juga mengurangi biaya pemeliharaan dan penyimpanan indeks dibandingkan dengan indeks tabel lengkap;
- Unik (Unik) adalah indeks yang memastikan tidak ada duplikat ( identik) nilai kunci indeks, sehingga menjamin keunikan baris untuk kunci ini. Indeks berkerumun dan tidak berkerumun bisa bersifat unik. Jika Anda membuat indeks unik pada beberapa kolom, indeks tersebut memastikan bahwa setiap kombinasi nilai dalam kunci adalah unik. Saat Anda membuat batasan PRIMARY KEY atau UNIQUE, server SQL secara otomatis membuat indeks unik pada kolom kunci. Indeks unik hanya dapat dibuat jika tabel saat ini tidak memiliki nilai duplikat di kolom kunci;
- berbentuk kolom (toko kolom) adalah indeks berdasarkan teknologi penyimpanan data kolom. Jenis indeks ini efektif untuk gudang data yang besar, karena dapat meningkatkan kinerja kueri ke gudang hingga 10 kali lipat dan juga mengurangi ukuran data hingga 10 kali lipat, karena data dalam indeks Columnstore dikompresi. Ada indeks kolom berkerumun dan yang tidak berkerumun;
- Teks lengkap (Teks lengkap) adalah tipe indeks khusus yang memberikan dukungan efisien untuk pencarian kata kompleks pada data string karakter. Proses membuat dan memelihara indeks teks lengkap disebut " isian" Ada beberapa jenis pengisian seperti: pengisian penuh dan pengisian berdasarkan pelacakan perubahan. Secara default, SQL Server sepenuhnya mengisi indeks teks lengkap baru segera setelah dibuat, namun hal ini memerlukan sejumlah besar sumber daya, bergantung pada ukuran tabel, sehingga mungkin saja menunda populasi penuh. Penyemaian berbasis pelacakan perubahan digunakan untuk mempertahankan indeks teks lengkap setelah awalnya diunggulkan sepenuhnya;
- Spasial (Spasial) adalah indeks yang memungkinkan Anda menggunakan operasi spesifik pada objek spasial secara lebih efisien dalam kolom tipe data geometri atau geografi. Jenis indeks ini hanya dapat dibuat pada kolom spasial, dan tabel yang menentukan indeks spasial harus berisi kunci utama ( KUNCI UTAMA);
- XML adalah tipe indeks khusus lainnya yang dirancang untuk kolom dengan tipe data XML. Indeks XML meningkatkan efisiensi pemrosesan kueri terhadap kolom XML. Ada dua jenis indeks XML: primer dan sekunder. Indeks XML utama mengindeks semua tag, nilai, dan jalur yang disimpan dalam kolom XML. Itu hanya dapat dibuat jika tabel memiliki indeks berkerumun pada kunci utama. Indeks XML sekunder hanya dapat dibuat jika tabel memiliki indeks XML primer dan digunakan untuk meningkatkan kinerja kueri pada jenis akses tertentu ke kolom XML, dalam hal ini, ada beberapa jenis indeks sekunder: PATH , NILAI dan PROPERTI;
- Ada juga indeks khusus untuk tabel dengan memori yang dioptimalkan ( OLTP Dalam Memori) seperti: Hash ( hash) indeks yang dioptimalkan memori dan indeks noncluster yang dibuat untuk pemindaian jangkauan dan pemindaian yang dipesan.
Membuat dan Menghapus Indeks di Microsoft SQL Server
Sebelum Anda mulai membuat indeks, Anda perlu mendesainnya dengan baik agar dapat menggunakan indeks secara efektif, karena indeks yang dirancang dengan buruk mungkin tidak meningkatkan kinerja, melainkan menurunkannya. Misalnya, memiliki banyak indeks pada tabel akan mengurangi kinerja pernyataan INSERT, UPDATE, DELETE, dan MERGE karena ketika data dalam tabel berubah, semua indeks harus diperbarui sesuai dengan itu. Kita akan melihat rekomendasi umum untuk mendesain indeks di artikel terpisah, namun sekarang mari kita beralih langsung ke proses pembuatan dan penghapusan indeks.
Catatan! Server SQL saya adalah Microsoft SQL Server 2016 Express.
Membuat Indeks
Ada dua cara untuk membuat indeks di Microsoft SQL Server: yang pertama menggunakan antarmuka grafis lingkungan SQL Server Management Studio (SSMS), dan yang kedua menggunakan bahasa Transact-SQL, kami akan menganalisis kedua metode tersebut.
Sumber data misalnya
Bayangkan kita memiliki tabel produk bernama TestTable, yang memiliki tiga kolom:
- ProductId – pengenal produk;
- Nama Produk – nama produk;
- KategoriID – kategori produk.
Contoh pembuatan indeks berkerumun
Seperti yang sudah saya katakan, indeks berkerumun dibuat secara otomatis jika, misalnya, saat membuat tabel, kita menentukan kolom tertentu sebagai kunci utama ( KUNCI UTAMA), tetapi karena kita belum melakukannya, mari kita lihat sendiri contoh pembuatan indeks berkerumun.
Untuk membuat indeks berkerumun, kita dapat menentukan kunci utama untuk tabel tersebut, sehingga indeks berkerumun akan dibuat secara otomatis, atau kita dapat membuat indeks berkerumun secara terpisah.
Misalnya saja kita membuat indeks berkerumun, tanpa membuat kunci utama. Pertama kita akan melakukan ini menggunakan Management Studio.
Buka SSMS dan temukan tabel yang diinginkan di browser objek dan klik kanan pada item “ Indeks", Pilih " Buat indeks" dan tipe indeks, dalam kasus kami " Berkelompok».

Formulir " Indeks baru", dimana kita perlu menentukan nama indeks baru ( itu harus unik di dalam tabel), kami juga menunjukkan apakah indeks ini akan unik; jika kita berbicara tentang pengidentifikasi produk di tabel produk, maka tentu saja harus unik. Kemudian pilih kolom ( kunci indeks), atas dasar itu kita akan membuat indeks berkerumun, mis. baris data dalam tabel akan diurutkan menggunakan " Menambahkan».

Setelah memasukkan semua parameter yang diperlukan, klik “ OKE", pada akhirnya indeks berkerumun akan dibuat.

Demikian pula, seseorang dapat membuat indeks berkerumun menggunakan pernyataan T-SQL INDEKS MAKHLUK, misalnya seperti ini
BUAT INDEKS CLUSTERED UNIK IX_Clustered PADA TestTable (ProductId ASC) GO
Atau, seperti yang sudah kami katakan, kita juga bisa menggunakan pernyataan untuk membuat kunci utama, misalnya
ALTER TABLE TestTable ADD CONSTRAINT PK_TestTable PRIMARY KEY CLUSTERED (ProductId ASC) GO
Contoh pembuatan indeks noncluster dengan kolom yang disertakan
Sekarang mari kita lihat contoh pembuatan indeks non-cluster, di mana kita akan menunjukkan kolom yang tidak akan menjadi kunci, tetapi akan dimasukkan dalam indeks. Ini berguna jika Anda membuat indeks untuk kueri tertentu, misalnya, sehingga indeks tersebut sepenuhnya mencakup kueri, yaitu. berisi semua kolom ( ini disebut "Cakupan Permintaan"). Cakupan kueri meningkatkan kinerja karena pengoptimal kueri dapat menemukan semua nilai kolom dalam indeks tanpa mengakses data tabel, sehingga mengurangi operasi I/O disk. Namun perlu diingat bahwa memasukkan kolom non-kunci ke dalam indeks memerlukan peningkatan ukuran indeks, yaitu. menyimpan indeks akan memerlukan lebih banyak ruang disk dan juga dapat mengakibatkan penurunan kinerja untuk operasi INSERT, UPDATE, DELETE, dan MERGE pada tabel dasar.
Untuk membuat indeks non-cluster menggunakan GUI Management Studio, kami juga menemukan tabel yang diinginkan dan item Indeks, hanya dalam hal ini kami memilih “ Buat -> Indeks Non-Cluster».

Setelah membuka formulir" Indeks baru"kita tentukan nama indeks, tambahkan kolom atau kolom kunci menggunakan tombol" Menambahkan", misalnya, untuk kasus pengujian kita, tentukan ID Kategori.


Di Transact-SQL akan terlihat seperti ini.
BUAT INDEKS NONCLUSTERED IX_NonClustered PADA TestTable (CategoryID ASC) INCLUDE (Nama Produk) GO
Contoh menghapus indeks di Microsoft SQL Server
Untuk menghapus indeks, Anda dapat mengklik kanan pada indeks yang diinginkan dan klik " Menghapus", lalu konfirmasikan tindakan Anda dengan mengklik" OKE».

atau Anda juga bisa menggunakan petunjuknya JATUHKAN INDEKS, Misalnya
JATUHKAN INDEX IX_NonClustered PADA TestTable
Perlu dicatat bahwa pernyataan DROP INDEX tidak berlaku untuk indeks yang dibuat dengan membuat batasan PRIMARY KEY dan UNIQUE. Dalam hal ini, untuk menghapus indeks, Anda harus menggunakan pernyataan ALTER TABLE dengan klausa DROP CONSTRAINT.
Mengoptimalkan Indeks di Microsoft SQL Server
Sebagai hasil dari memperbarui, menambah atau menghapus data dalam tabel SQL, server secara otomatis membuat perubahan yang sesuai pada indeks, tetapi seiring waktu semua perubahan ini dapat menyebabkan fragmentasi data dalam indeks, mis. mereka pada akhirnya akan tersebar di seluruh database. Fragmentasi indeks menyebabkan penurunan kinerja query, sehingga secara berkala perlu dilakukan operasi pemeliharaan indeks, yaitu defragmentasi, seperti operasi reorganisasi indeks dan pembangunan kembali.
Kapan menggunakan reorganisasi indeks dan kapan harus membangun kembali?
Untuk menjawab pertanyaan ini, pertama-tama Anda perlu menentukan tingkat fragmentasi indeks, karena bergantung pada fragmentasi indeks, satu atau beberapa metode defragmentasi akan lebih disukai dan lebih efektif. Anda dapat menggunakan fungsi tabel sistem untuk menentukan tingkat fragmentasi indeks sys.dm_db_index_physical_stats, yang mengembalikan informasi rinci tentang ukuran dan fragmentasi indeks. Misalnya, dengan menggunakan kueri berikut, Anda bisa mengetahui tingkat fragmentasi indeks untuk semua tabel di database saat ini.
PILIH OBJECT_NAME(T1.object_id) SEBAGAI NameTable, T1.index_id SEBAGAI IndexId, T2.name SEBAGAI IndexName, T1.avg_fragmentation_in_percent SEBAGAI Fragmentasi FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) SEBAGAI T1 KIRI GABUNG sys. indeks SEBAGAI T2 PADA T1.object_id = T2.object_id DAN T1.index_id = T2.index_id
Dalam hal ini, kami tertarik pada kolom tersebut rata-rata_fragmentasi_dalam_persen, yaitu. persentase fragmentasi logis.
- Jika tingkat fragmentasi kurang dari 5%, maka penataan ulang atau pembangunan kembali indeks tidak boleh dimulai sama sekali;
- Jika tingkat fragmentasi berkisar antara 5 hingga 30%, maka masuk akal untuk memulai reorganisasi indeks, karena operasi ini menggunakan sumber daya sistem minimal dan tidak memerlukan pemblokiran jangka panjang;
- Jika derajat fragmentasi lebih dari 30%, maka indeks perlu dibangun kembali, karena operasi ini, dengan fragmentasi yang signifikan, memberikan pengaruh yang lebih besar daripada operasi reorganisasi indeks.
Secara pribadi, saya dapat menambahkan yang berikut ini jika Anda memiliki perusahaan kecil dan database tidak memerlukan output maksimal 24 jam sehari, yaitu. Karena ini bukan database super aktif, Anda dapat dengan aman melakukan operasi pembuatan ulang indeks secara berkala, bahkan tanpa menentukan tingkat fragmentasi.
Mengatur Ulang Indeks
Reorganisasi indeks adalah proses defragmentasi indeks yang mendefrag indeks clustered dan non-clustered tingkat daun pada tabel dan tampilan dengan menyusun ulang halaman tingkat daun secara fisik berdasarkan urutan logis ( dari kiri ke kanan) simpul akhir.
Anda dapat menggunakan alat grafis SSMS atau pernyataan Transact-SQL untuk mengatur ulang indeks.
Menata Ulang Indeks Menggunakan Management Studio

Mengatur Ulang Indeks Menggunakan Transact-SQL
ALTER INDEX IX_NonClustered PADA TestTable REORGANISASI GO
Membangun kembali indeks
Membangun kembali indeks adalah proses yang menghapus indeks lama dan membuat indeks baru, sehingga menghilangkan fragmentasi.
Anda dapat menggunakan dua metode untuk membangun kembali indeks.
Pertama. Menggunakan pernyataan ALTER INDEX dengan klausa REBUILD. Pernyataan ini menggantikan pernyataan DBCC DBREINDEX. Biasanya, ini adalah metode yang digunakan untuk membangun kembali indeks secara massal.
Contoh
ALTER INDEX IX_NonClustered PADA TestTable REBUILD GO
Dan yang kedua, menggunakan pernyataan CREATE INDEX dengan klausa DROP_EXISTING. Dapat digunakan, misalnya, untuk membangun kembali indeks dengan mengubah definisinya, yaitu. menambah atau menghapus kolom kunci.
Contoh
BUAT INDEKS NONCLUSTERED IX_NonClustered PADA TestTable (CategoryID ASC) DENGAN(DROP_EXISTING = ON) GO
Fungsionalitas pembangunan kembali juga tersedia di Management Studio. Klik kanan pada indeks yang diinginkan " Membangun kembali».

Sekianlah materi tentang dasar-dasar indeks di Microsoft SQL Server. Jika Anda tertarik dengan bahasa T-SQL, saya sarankan membaca buku saya “
Salah satu cara terpenting untuk mencapai produktivitas tinggi SQLServer adalah penggunaan indeks. Indeks mempercepat proses kueri dengan menyediakan akses cepat ke baris data dalam tabel, seperti indeks dalam buku membantu Anda menemukan informasi yang Anda perlukan dengan cepat. Pada artikel ini saya akan memberikan gambaran singkat tentang indeks di SQLServer dan menjelaskan bagaimana mereka diatur dalam database dan bagaimana mereka membantu mempercepat query database.Indeks dibuat pada kolom tabel dan tampilan. Indeks menyediakan cara untuk mencari data dengan cepat berdasarkan nilai di kolom tersebut. Misalnya, jika Anda membuat indeks pada kunci utama lalu mencari baris data menggunakan nilai kunci utama, maka SQLServer pertama-tama akan menemukan nilai indeks dan kemudian menggunakan indeks untuk menemukan seluruh baris data dengan cepat. Tanpa indeks, pemindaian penuh terhadap semua baris dalam tabel akan dilakukan, yang dapat berdampak signifikan pada performa.
Anda dapat membuat indeks pada sebagian besar kolom dalam tabel atau tampilan. Pengecualiannya terutama adalah kolom dengan tipe data untuk menyimpan objek besar ( LOB), seperti gambar, teks atau varchar(maks). Anda juga dapat membuat indeks pada kolom yang dirancang untuk menyimpan data dalam format XML, namun indeks ini disusun sedikit berbeda dari indeks standar dan pertimbangannya berada di luar cakupan artikel ini. Selain itu, artikel tersebut tidak membahas toko kolom indeks. Sebaliknya, saya fokus pada indeks yang paling umum digunakan dalam database SQLServer.
Indeks terdiri dari sekumpulan halaman, node indeks, yang disusun dalam struktur pohon - pohon yang seimbang. Struktur ini bersifat hierarkis dan dimulai dengan simpul akar di bagian atas hierarki dan simpul daun, yaitu daun, di bagian bawah, seperti yang ditunjukkan pada gambar: 
Saat Anda mengkueri kolom yang diindeks, mesin kueri dimulai dari bagian atas simpul akar dan turun ke bawah melalui simpul perantara, dengan setiap lapisan perantara berisi informasi lebih rinci tentang data. Mesin kueri terus bergerak melalui node indeks hingga mencapai level terbawah dengan indeks keluar. Misalnya, jika Anda mencari nilai 123 di kolom yang diindeks, mesin kueri akan menentukan halaman pada tingkat menengah pertama di tingkat akar terlebih dahulu. Dalam hal ini, halaman pertama menunjuk ke nilai dari 1 hingga 100, dan halaman kedua dari 101 hingga 200, sehingga mesin kueri akan mengakses halaman kedua dari tingkat menengah ini. Selanjutnya Anda akan melihat bahwa Anda harus membuka halaman ketiga dari tingkat menengah berikutnya. Dari sini, subsistem kueri akan membaca nilai indeks itu sendiri di tingkat yang lebih rendah. Daun indeks dapat berisi data tabel itu sendiri atau sekadar penunjuk ke baris dengan data dalam tabel, bergantung pada jenis indeks: indeks berkerumun atau indeks tidak berkerumun.
Indeks berkerumun
Indeks berkerumun menyimpan baris data sebenarnya di daun indeks. Kembali ke contoh sebelumnya, ini berarti baris data yang terkait dengan nilai kunci 123 akan disimpan dalam indeks itu sendiri. Ciri penting dari indeks berkerumun adalah semua nilai diurutkan dalam urutan tertentu, baik menaik atau menurun. Oleh karena itu, tabel atau tampilan hanya dapat memiliki satu indeks berkerumun. Selain itu, perlu diperhatikan bahwa data dalam tabel disimpan dalam bentuk terurut hanya jika indeks berkerumun telah dibuat pada tabel ini.Tabel yang tidak memiliki indeks berkerumun disebut heap.
Indeks non-cluster
Berbeda dengan indeks yang berkerumun, daun indeks yang tidak berkerumun hanya berisi kolom-kolom tersebut ( kunci) yang menentukan indeks ini, dan juga berisi penunjuk ke baris dengan data nyata dalam tabel. Ini berarti bahwa sistem subkueri memerlukan operasi tambahan untuk mencari dan mengambil data yang diperlukan. Konten penunjuk data bergantung pada cara data disimpan: tabel berkerumun atau heap. Jika sebuah penunjuk menunjuk ke tabel berkerumun, ia menunjuk ke indeks berkerumun yang dapat digunakan untuk menemukan data aktual. Jika sebuah penunjuk mengacu pada heap, maka penunjuk tersebut menunjuk ke pengidentifikasi baris data tertentu. Indeks noncluster tidak dapat diurutkan seperti indeks cluster, namun Anda dapat membuat lebih dari satu indeks noncluster pada tabel atau tampilan, hingga 999. Ini tidak berarti Anda harus membuat indeks sebanyak mungkin. Indeks dapat meningkatkan atau menurunkan kinerja sistem. Selain dapat membuat beberapa indeks non-cluster, Anda juga dapat menyertakan kolom tambahan ( kolom yang disertakan) ke dalam indeksnya: daun indeks tidak hanya akan menyimpan nilai kolom yang diindeks itu sendiri, tetapi juga nilai kolom tambahan yang tidak diindeks ini. Pendekatan ini akan memungkinkan Anda untuk melewati beberapa batasan yang ditempatkan pada indeks. Misalnya, Anda dapat menyertakan kolom yang tidak dapat diindeks atau melewati batas panjang indeks (umumnya 900 byte).Jenis Indeks
Selain menjadi indeks berkerumun atau tidak berkerumun, indeks ini juga dapat dikonfigurasikan lebih lanjut sebagai indeks gabungan, indeks unik, atau indeks penutup.Indeks komposit
Indeks tersebut dapat berisi lebih dari satu kolom. Anda dapat menyertakan hingga 16 kolom dalam indeks, namun panjang totalnya dibatasi hingga 900 byte. Indeks berkerumun dan tidak berkerumun dapat berupa komposit.Indeks unik
Indeks ini memastikan bahwa setiap nilai dalam kolom yang diindeks adalah unik. Jika indeksnya gabungan, maka keunikan berlaku untuk semua kolom dalam indeks, namun tidak untuk setiap kolom individual. Misalnya, jika Anda membuat indeks unik pada kolom NAMA Dan NAMA BELAKANG, maka nama lengkap harus unik, tetapi duplikat pada nama depan atau belakang dapat dilakukan.Indeks unik secara otomatis dibuat ketika Anda menentukan batasan kolom: batasan kunci utama atau nilai unik:
- Kunci utama
Saat Anda menentukan batasan kunci utama pada satu atau lebih kolom SQLServer secara otomatis membuat indeks berkerumun unik jika indeks berkerumun belum pernah dibuat sebelumnya (dalam hal ini, indeks unik non-berkelompok dibuat pada kunci utama) - Keunikan nilai
Saat Anda menentukan batasan pada keunikan nilai, maka SQLServer secara otomatis membuat indeks non-cluster unik. Anda dapat menentukan bahwa indeks berkerumun unik akan dibuat jika belum ada indeks berkerumun yang dibuat pada tabel
Meliputi indeks
Indeks semacam itu memungkinkan kueri tertentu untuk segera mendapatkan semua data yang diperlukan dari daun indeks tanpa akses tambahan ke catatan tabel itu sendiri.Merancang Indeks
Meskipun indeks bermanfaat, indeks harus dirancang dengan hati-hati. Karena indeks dapat menghabiskan banyak ruang disk, Anda tidak ingin membuat indeks lebih banyak dari yang diperlukan. Selain itu, indeks diperbarui secara otomatis ketika baris data itu sendiri diperbarui, yang dapat menyebabkan tambahan sumber daya tambahan dan penurunan kinerja. Saat merancang indeks, beberapa pertimbangan mengenai database dan pertanyaan terhadapnya harus dipertimbangkan.Basis data
Seperti disebutkan sebelumnya, indeks dapat meningkatkan kinerja sistem karena mereka menyediakan mesin kueri cara cepat untuk menemukan data. Namun, Anda juga harus memperhitungkan seberapa sering Anda ingin menyisipkan, memperbarui, atau menghapus data. Saat Anda mengubah data, indeks juga harus diubah untuk mencerminkan tindakan terkait pada data, yang dapat mengurangi kinerja sistem secara signifikan. Pertimbangkan panduan berikut saat merencanakan strategi pengindeksan Anda:- Untuk tabel yang sering diperbarui, gunakan indeks sesedikit mungkin.
- Jika tabel berisi data dalam jumlah besar namun perubahannya kecil, gunakan indeks sebanyak yang diperlukan untuk meningkatkan performa kueri Anda. Namun, pikirkan baik-baik sebelum menggunakan indeks pada tabel kecil, karena... Ada kemungkinan bahwa penggunaan pencarian indeks memerlukan waktu lebih lama daripada sekadar memindai semua baris.
- Untuk indeks berkerumun, cobalah untuk membuat kolom sesingkat mungkin. Pendekatan terbaik adalah dengan menggunakan indeks berkerumun pada kolom yang memiliki nilai unik dan tidak mengizinkan NULL. Inilah sebabnya mengapa kunci utama sering digunakan sebagai indeks berkerumun.
- Keunikan nilai dalam suatu kolom mempengaruhi kinerja indeks. Secara umum, semakin banyak duplikat yang Anda miliki dalam sebuah kolom, semakin buruk kinerja indeksnya. Di sisi lain, semakin banyak nilai unik yang dimilikinya, semakin baik kinerja indeksnya. Gunakan indeks unik bila memungkinkan.
- Untuk indeks gabungan, perhatikan urutan kolom dalam indeks. Kolom yang digunakan dalam ekspresi DI MANA(Misalnya, DIMANA Nama Depan = "Charlie") harus menjadi yang pertama dalam indeks. Kolom berikutnya harus dicantumkan berdasarkan keunikan nilainya (kolom dengan jumlah nilai unik terbanyak didahulukan).
- Anda juga dapat menentukan indeks pada kolom terhitung jika memenuhi persyaratan tertentu. Misalnya, ekspresi yang digunakan untuk mendapatkan nilai kolom harus bersifat deterministik (selalu memberikan hasil yang sama untuk sekumpulan parameter masukan tertentu).
Kueri basis data
Pertimbangan lain ketika merancang indeks adalah kueri apa yang dijalankan terhadap database. Seperti yang dinyatakan sebelumnya, Anda harus mempertimbangkan seberapa sering data berubah. Selain itu, prinsip-prinsip berikut harus digunakan:- Cobalah untuk menyisipkan atau memodifikasi baris sebanyak mungkin dalam satu kueri, daripada melakukannya dalam beberapa kueri tunggal.
- Buat indeks non-cluster pada kolom yang sering digunakan sebagai istilah pencarian dalam kueri Anda. DI MANA dan koneksi di BERGABUNG.
- Pertimbangkan untuk mengindeks kolom yang digunakan dalam kueri pencarian baris untuk mendapatkan nilai yang sama persis.
Dan sekarang, sebenarnya:
14 pertanyaan tentang indeks di SQL Server yang membuat Anda malu untuk bertanya
Mengapa sebuah tabel tidak dapat memiliki dua indeks berkerumun?
Ingin jawaban singkat? Indeks berkerumun adalah sebuah tabel. Saat Anda membuat indeks berkerumun pada tabel, mesin penyimpanan mengurutkan semua baris dalam tabel dalam urutan menaik atau menurun, sesuai dengan definisi indeks. Indeks berkerumun bukanlah entitas terpisah seperti indeks lainnya, tetapi merupakan mekanisme untuk mengurutkan data dalam tabel dan memfasilitasi akses cepat ke baris data.Bayangkan Anda memiliki tabel yang berisi riwayat transaksi penjualan. Tabel Penjualan memuat informasi seperti ID pesanan, posisi produk dalam pesanan, nomor produk, jumlah produk, nomor dan tanggal pesanan, dll. Anda membuat indeks berkerumun pada kolom Id pemesanan Dan ID Garis, diurutkan dalam urutan menaik seperti yang ditunjukkan berikut ini T-SQL kode:
BUAT INDEKS CLUSTERED UNIK ix_oriderid_lineid PADA dbo.Sales(OrderID, LineID);
Saat Anda menjalankan skrip ini, semua baris dalam tabel akan diurutkan secara fisik terlebih dahulu berdasarkan kolom OrderID dan kemudian berdasarkan LineID, namun datanya sendiri akan tetap berada dalam satu blok logis, yaitu tabel. Karena alasan ini, Anda tidak dapat membuat dua indeks berkerumun. Hanya ada satu tabel dengan satu data dan tabel tersebut hanya dapat diurutkan satu kali dalam urutan tertentu.
Jika tabel cluster memberikan banyak manfaat, lalu mengapa menggunakan heap?
Kamu benar. Tabel terkluster sangat bagus dan sebagian besar kueri Anda akan berperforma lebih baik pada tabel yang memiliki indeks terkluster. Namun dalam beberapa kasus, Anda mungkin ingin membiarkan tabel dalam keadaan alami dan murni, yaitu. dalam bentuk heap, dan buat hanya indeks non-cluster agar kueri Anda tetap berjalan.Heap, seperti yang Anda ingat, menyimpan data dalam urutan acak. Biasanya, subsistem penyimpanan menambahkan data ke tabel sesuai urutan penyisipannya, namun subsistem penyimpanan juga suka memindahkan baris untuk penyimpanan yang lebih efisien. Akibatnya, Anda tidak memiliki kesempatan untuk memprediksi urutan penyimpanan data.
Jika mesin kueri perlu menemukan data tanpa memanfaatkan indeks noncluster, mesin kueri akan melakukan pemindaian penuh terhadap tabel untuk menemukan baris yang diperlukan. Pada tabel yang sangat kecil, hal ini biasanya tidak menjadi masalah, namun seiring bertambahnya ukuran heap, kinerja akan menurun dengan cepat. Tentu saja, indeks non-cluster dapat membantu dengan menggunakan penunjuk ke file, halaman, dan baris tempat data yang diperlukan disimpan - ini biasanya merupakan alternatif yang jauh lebih baik daripada pemindaian tabel. Meski begitu, sulit untuk membandingkan manfaat indeks berkerumun ketika mempertimbangkan kinerja kueri.
Namun, heap dapat membantu meningkatkan kinerja dalam situasi tertentu. Pertimbangkan sebuah tabel dengan banyak sisipan tetapi sedikit pembaruan atau penghapusan. Misalnya, tabel yang menyimpan log terutama digunakan untuk memasukkan nilai hingga diarsipkan. Di heap, Anda tidak akan melihat paging dan fragmentasi data seperti yang Anda lihat dengan indeks berkerumun karena baris hanya ditambahkan ke akhir heap. Memisahkan halaman terlalu banyak dapat berdampak signifikan pada kinerja, dan tidak berdampak baik. Secara umum, heap memungkinkan Anda memasukkan data dengan relatif mudah dan Anda tidak perlu berurusan dengan biaya penyimpanan dan pemeliharaan seperti yang Anda lakukan dengan indeks berkerumun.
Namun kurangnya pembaruan dan penghapusan data tidak boleh dianggap sebagai satu-satunya alasan. Cara pengambilan sampel data juga merupakan faktor penting. Misalnya, Anda tidak boleh menggunakan heap jika Anda sering menanyakan rentang data atau data yang Anda kueri sering kali perlu diurutkan atau dikelompokkan.
Artinya, Anda sebaiknya hanya mempertimbangkan penggunaan heap ketika Anda bekerja dengan tabel yang sangat kecil atau semua interaksi Anda dengan tabel terbatas pada penyisipan data dan kueri Anda sangat sederhana (dan Anda menggunakan indeks non-cluster). Bagaimanapun). Jika tidak, tetap gunakan indeks berkerumun yang dirancang dengan baik, seperti indeks yang ditentukan pada bidang kunci menaik sederhana, seperti kolom yang banyak digunakan dengan IDENTITAS.
Bagaimana cara mengubah faktor pengisian indeks default?
Mengubah faktor pengisian indeks default adalah satu hal. Memahami cara kerja rasio default adalah masalah lain. Tapi pertama-tama, mundurlah beberapa langkah. Faktor pengisian indeks menentukan jumlah ruang pada halaman untuk menyimpan indeks di tingkat paling bawah (tingkat daun) sebelum mulai mengisi halaman baru. Misalnya, jika koefisien disetel ke 90, maka ketika indeks bertambah, ia akan menempati 90% halaman dan kemudian berpindah ke halaman berikutnya.Secara default, nilai faktor pengisian indeks ada di SQLServer adalah 0, yang sama dengan 100. Hasilnya, semua indeks baru secara otomatis mewarisi pengaturan ini kecuali Anda secara spesifik menentukan nilai dalam kode Anda yang berbeda dari nilai standar sistem atau mengubah perilaku default. Anda dapat gunakan Studio Manajemen SQL Server untuk menyesuaikan nilai default atau menjalankan prosedur tersimpan sistem sp_configure. Misalnya himpunan berikut T-SQL perintah menetapkan nilai koefisien menjadi 90 (Anda harus terlebih dahulu beralih ke mode pengaturan lanjutan):
EXEC sp_configure "tampilkan opsi lanjutan", 1; PERGI KONFIGURASI ULANG; GO EXEC sp_configure "faktor pengisian", 90; PERGI KONFIGURASI ULANG; PERGI
Setelah mengubah nilai faktor pengisian indeks, Anda perlu memulai ulang layanan SQLServer. Anda sekarang dapat memeriksa nilai yang ditetapkan dengan menjalankan sp_configure tanpa argumen kedua yang ditentukan:
EXEC sp_configure "faktor pengisian" GO
Perintah ini harus mengembalikan nilai 90. Akibatnya, semua indeks yang baru dibuat akan menggunakan nilai ini. Anda dapat mengujinya dengan membuat indeks dan menanyakan nilai faktor pengisian:
GUNAKAN AdventureWorks2012; -- database Anda BUAT INDEKS NONCLUSTERED ix_people_lastname PADA Person.Person(LastName); PILIH fill_factor DARI sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Dalam contoh ini, kami membuat indeks non-cluster pada sebuah tabel Orang dalam basis data PetualanganWorks2012. Setelah membuat indeks, kita bisa mendapatkan nilai faktor pengisian dari tabel sistem sys.indexes. Kueri harus menghasilkan 90.
Namun, bayangkan kita menghapus indeks dan membuatnya lagi, namun sekarang kita menentukan nilai faktor pengisian tertentu:
BUAT INDEKS NONCLUSTERED ix_people_lastname PADA Person.Person(LastName) DENGAN (fillfactor=80); PILIH fill_factor DARI sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Kali ini kami telah menambahkan instruksi DENGAN dan pilihan faktor pengisi untuk operasi pembuatan indeks kami BUAT INDEKS dan menentukan nilainya 80. Operator PILIH sekarang mengembalikan nilai yang sesuai.
Sejauh ini, semuanya berjalan cukup mudah. Hal yang membuat Anda benar-benar bosan dalam keseluruhan proses ini adalah saat Anda membuat indeks yang menggunakan nilai koefisien default, dengan asumsi Anda mengetahui nilai tersebut. Misalnya, seseorang mengutak-atik pengaturan server dan begitu keras kepala sehingga menetapkan faktor pengisian indeks ke 20. Sementara itu, Anda terus membuat indeks, dengan asumsi nilai defaultnya adalah 0. Sayangnya, Anda tidak memiliki cara untuk mengetahui isiannya. faktorkan sampai selama Anda tidak membuat indeks dan kemudian memeriksa nilainya seperti yang kami lakukan dalam contoh kami. Jika tidak, Anda harus menunggu saat kinerja kueri turun drastis sehingga Anda mulai mencurigai sesuatu.
Masalah lain yang harus Anda waspadai adalah membangun kembali indeks. Seperti halnya membuat indeks, Anda dapat menentukan nilai faktor pengisian indeks saat Anda membangunnya kembali. Namun, tidak seperti perintah buat indeks, pembangunan kembali tidak menggunakan pengaturan default server, apa pun tampilannya. Terlebih lagi, jika Anda tidak secara spesifik menentukan nilai faktor pengisian indeks, maka SQLServer akan menggunakan nilai koefisien yang dimiliki indeks ini sebelum direstrukturisasi. Misalnya operasi berikut MENGUBAH INDEKS membangun kembali indeks yang baru saja kita buat:
ALTER INDEX ix_people_lastname PADA Person.Person REBUILD; PILIH fill_factor DARI sys.indexes WHERE object_id = object_id("Person.Person") AND name="ix_people_lastname";
Saat kita mengecek nilai faktor pengisian, kita akan mendapatkan nilai 80, karena itulah yang kita tentukan saat terakhir kali kita membuat indeks. Nilai default diabaikan.
Seperti yang Anda lihat, mengubah nilai faktor pengisian indeks tidaklah sulit. Jauh lebih sulit untuk mengetahui nilai saat ini dan memahami kapan nilai tersebut diterapkan. Jika Anda selalu menentukan koefisien secara spesifik saat membuat dan membangun kembali indeks, maka Anda selalu mengetahui hasil spesifiknya. Kecuali Anda harus khawatir untuk memastikan orang lain tidak mengacaukan pengaturan server lagi, menyebabkan semua indeks dibangun kembali dengan faktor pengisian indeks yang sangat rendah.
Apakah mungkin membuat indeks berkerumun pada kolom yang berisi duplikat?
Iya dan tidak. Ya, Anda dapat membuat indeks berkerumun pada kolom kunci yang berisi nilai duplikat. Tidak, nilai kolom kunci tidak boleh tetap dalam keadaan tidak unik. Biar saya jelaskan. Jika Anda membuat indeks berkerumun non-unik pada kolom, mesin penyimpanan menambahkan keunikan ke nilai duplikat untuk memastikan keunikan dan oleh karena itu dapat mengidentifikasi setiap baris dalam tabel berkerumun.Misalnya, Anda mungkin memutuskan untuk membuat indeks berkerumun pada kolom yang berisi data pelanggan Nama keluarga menjaga nama keluarga. Kolom tersebut berisi nilai Franklin, Hancock, Washington, dan Smith. Kemudian Anda memasukkan nilai Adams, Hancock, Smith dan Smith lagi. Namun nilai kolom kunci harus unik, sehingga mesin penyimpanan akan mengubah nilai duplikat sehingga terlihat seperti ini: Adams, Franklin, Hancock, Hancock1234, Washington, Smith, Smith4567, dan Smith5678.
Pada pandangan pertama, pendekatan ini tampak baik-baik saja, tetapi nilai integer meningkatkan ukuran kunci, yang dapat menjadi masalah jika ada banyak duplikat, dan nilai-nilai ini akan menjadi dasar dari indeks non-cluster atau indeks asing. referensi kunci. Karena alasan ini, Anda harus selalu mencoba membuat indeks berkerumun unik jika memungkinkan. Jika hal ini tidak memungkinkan, setidaknya coba gunakan kolom dengan konten nilai unik yang sangat tinggi.
Bagaimana tabel disimpan jika indeks berkerumun belum dibuat?
SQLServer mendukung dua jenis tabel: tabel berkerumun yang memiliki indeks berkerumun dan tabel tumpukan atau hanya tumpukan. Tidak seperti tabel berkerumun, data di heap tidak diurutkan dengan cara apa pun. Intinya, ini adalah tumpukan (heap) data. Jika Anda menambahkan baris ke tabel tersebut, mesin penyimpanan hanya akan menambahkannya ke akhir halaman. Jika halaman sudah terisi data, maka akan ditambahkan ke halaman baru. Dalam kebanyakan kasus, Anda ingin membuat indeks berkerumun pada tabel untuk memanfaatkan kemampuan penyortiran dan kecepatan kueri (coba bayangkan mencari nomor telepon di buku alamat yang tidak diurutkan). Namun, jika Anda memilih untuk tidak membuat indeks berkerumun, Anda masih dapat membuat indeks tidak berkerumun di heap. Dalam hal ini, setiap baris indeks akan memiliki penunjuk ke baris heap. Indeks mencakup ID file, nomor halaman, dan nomor baris data.Apa hubungan antara batasan keunikan nilai dan kunci utama dengan indeks tabel?
Kunci utama dan batasan unik memastikan bahwa nilai dalam kolom bersifat unik. Anda hanya dapat membuat satu kunci utama untuk sebuah tabel dan tidak boleh berisi nilai BATAL. Anda dapat membuat beberapa batasan pada keunikan suatu nilai untuk sebuah tabel, dan masing-masing batasan tersebut dapat memiliki satu catatan BATAL.Saat Anda membuat kunci utama, mesin penyimpanan juga membuat indeks berkerumun unik jika indeks berkerumun belum dibuat. Namun, Anda dapat mengganti perilaku default dan indeks non-cluster akan dibuat. Jika indeks berkerumun ada saat Anda membuat kunci utama, indeks noncluster unik akan dibuat.
Saat Anda membuat batasan unik, mesin penyimpanan membuat indeks unik dan tidak terkluster. Namun, Anda dapat menentukan pembuatan indeks berkerumun unik jika belum pernah dibuat sebelumnya.
Secara umum, batasan nilai unik dan indeks unik adalah hal yang sama.
Mengapa indeks berkerumun dan tidak berkerumun disebut B-tree di SQL Server?
Indeks dasar di SQL Server, berkerumun atau tidak berkerumun, didistribusikan ke seluruh kumpulan halaman yang disebut simpul indeks. Halaman-halaman ini disusun dalam hierarki tertentu dengan struktur pohon yang disebut pohon seimbang. Pada tingkat atas terdapat simpul akar, pada bagian bawah terdapat simpul daun, dengan simpul perantara antara tingkat atas dan bawah, seperti terlihat pada gambar:Node akar menyediakan titik masuk utama untuk kueri yang mencoba mengambil data melalui indeks. Mulai dari node ini, mesin kueri memulai navigasi ke bawah struktur hierarki ke node daun yang sesuai yang berisi data.
Misalnya, bayangkan permintaan telah diterima untuk memilih baris yang berisi nilai kunci 82. Subsistem kueri mulai bekerja dari simpul akar, yang merujuk ke simpul perantara yang sesuai, dalam kasus kita 1-100. Dari node perantara 1-100 terjadi transisi ke node 51-100, dan dari sana ke node akhir 76-100. Jika ini adalah indeks berkerumun, maka daun simpul berisi data dari baris yang terkait dengan kunci sama dengan 82. Jika ini adalah indeks yang tidak berkerumun, maka daun indeks berisi penunjuk ke tabel berkerumun atau baris tertentu di tumpukan.
Bagaimana indeks dapat meningkatkan kinerja kueri jika Anda harus melintasi semua node indeks ini?
Pertama, indeks tidak selalu meningkatkan kinerja. Terlalu banyak indeks yang salah dibuat mengubah sistem menjadi rawa dan menurunkan kinerja kueri. Lebih tepat dikatakan bahwa jika indeks diterapkan dengan hati-hati, indeks dapat memberikan peningkatan kinerja yang signifikan.Bayangkan sebuah buku besar yang didedikasikan untuk penyetelan kinerja SQLServer(versi kertas, bukan versi elektronik). Bayangkan Anda ingin mencari informasi tentang mengonfigurasi Resource Governor. Anda dapat menyeret jari Anda halaman demi halaman ke seluruh buku, atau membuka daftar isi dan mencari tahu nomor halaman pasti dengan informasi yang Anda cari (asalkan buku tersebut diindeks dengan benar dan isinya memiliki indeks yang benar). Hal ini tentunya akan menghemat banyak waktu Anda, meskipun Anda harus mengakses struktur yang sama sekali berbeda (indeks) terlebih dahulu untuk mendapatkan informasi yang Anda perlukan dari struktur utama (buku).
Seperti indeks buku, indeks masuk SQLServer memungkinkan Anda menjalankan kueri yang tepat pada data yang Anda perlukan alih-alih memindai seluruh data yang terdapat dalam tabel. Untuk tabel kecil, pemindaian penuh biasanya tidak menjadi masalah, namun tabel besar memakan banyak halaman data, yang dapat mengakibatkan waktu eksekusi kueri yang signifikan kecuali ada indeks yang memungkinkan mesin kueri segera mendapatkan lokasi data yang benar. Bayangkan tersesat di persimpangan jalan bertingkat di depan kota metropolitan besar tanpa peta dan Anda akan mendapatkan idenya.
Jika indeks sangat bagus, mengapa tidak membuatnya saja di setiap kolom?
Tidak ada perbuatan baik yang dibiarkan begitu saja. Setidaknya itulah yang terjadi dengan indeks. Tentu saja, indeks berfungsi dengan baik selama Anda menjalankan kueri pengambilan operator PILIH, tetapi segera setelah panggilan rutin ke operator dimulai MENYISIPKAN, MEMPERBARUI Dan MENGHAPUS, jadi lanskap berubah dengan sangat cepat.Saat Anda memulai permintaan data oleh operator PILIH, mesin kueri menemukan indeks, menelusuri struktur pohonnya, dan menemukan data yang dicarinya. Apa yang lebih sederhana? Tapi segalanya berubah jika Anda memulai pernyataan perubahan seperti MEMPERBARUI. Ya, untuk bagian pertama pernyataan, mesin kueri dapat kembali menggunakan indeks untuk menemukan baris yang sedang dimodifikasi - itu kabar baik. Dan jika ada perubahan sederhana pada data dalam satu baris yang tidak mempengaruhi perubahan pada kolom kunci, maka proses perubahan tidak akan menimbulkan kesulitan sama sekali. Namun bagaimana jika perubahan menyebabkan halaman berisi data terpecah, atau nilai kolom kunci diubah sehingga dipindahkan ke node indeks lain - hal ini akan mengakibatkan indeks mungkin memerlukan reorganisasi yang memengaruhi semua indeks dan operasi terkait , mengakibatkan penurunan produktivitas secara luas.
Proses serupa terjadi saat memanggil operator MENGHAPUS. Indeks dapat membantu menemukan lokasi data yang dihapus, namun menghapus data itu sendiri dapat mengakibatkan perombakan halaman. Mengenai operator MENYISIPKAN, musuh utama semua indeks: Anda mulai menambahkan sejumlah besar data, yang menyebabkan perubahan dalam indeks dan reorganisasinya dan semua orang menderita.
Jadi pertimbangkan jenis kueri ke database Anda ketika memikirkan jenis indeks apa dan berapa banyak yang harus dibuat. Lebih banyak tidak berarti lebih baik. Sebelum menambahkan indeks baru ke tabel, pertimbangkan biaya tidak hanya dari kueri yang mendasarinya, tetapi juga jumlah ruang disk yang dikonsumsi, biaya pemeliharaan fungsionalitas, dan indeks, yang dapat menyebabkan efek domino pada operasi lainnya. Strategi desain indeks Anda adalah salah satu aspek terpenting dalam penerapan Anda dan harus mencakup banyak pertimbangan, mulai dari ukuran indeks, jumlah nilai unik, hingga jenis kueri yang akan didukung indeks.
Apakah perlu membuat indeks berkerumun pada kolom dengan kunci utama?
Anda dapat membuat indeks berkerumun pada kolom mana pun yang memenuhi ketentuan yang diperlukan. Memang benar bahwa indeks berkerumun dan batasan kunci utama dibuat untuk satu sama lain dan merupakan kecocokan yang dibuat di surga, jadi pahami fakta bahwa ketika Anda membuat kunci utama, maka indeks berkerumun akan otomatis dibuat jika belum ada. dibuat sebelumnya. Namun, Anda mungkin memutuskan bahwa indeks berkerumun akan berkinerja lebih baik di tempat lain, dan sering kali keputusan Anda dapat dibenarkan.Tujuan utama indeks berkerumun adalah untuk mengurutkan semua baris dalam tabel Anda berdasarkan kolom kunci yang ditentukan saat menentukan indeks. Ini memberikan pencarian cepat dan akses mudah ke data tabel.
Kunci utama suatu tabel dapat menjadi pilihan yang baik karena kunci tersebut secara unik mengidentifikasi setiap baris dalam tabel tanpa harus menambahkan data tambahan. Dalam beberapa kasus, pilihan terbaik adalah kunci utama pengganti, yang tidak hanya unik, tetapi juga berukuran kecil dan nilainya meningkat secara berurutan, membuat indeks noncluster berdasarkan nilai ini menjadi lebih efisien. Pengoptimal kueri juga menyukai kombinasi indeks berkerumun dan kunci utama ini karena menggabungkan tabel lebih cepat daripada menggabungkan dengan cara lain yang tidak menggunakan kunci utama dan indeks berkerumun terkait. Seperti yang saya katakan, ini adalah pasangan yang dibuat di surga.
Namun yang terakhir, perlu dicatat bahwa saat membuat indeks berkerumun, ada beberapa aspek yang perlu dipertimbangkan: berapa banyak indeks non-kluster yang akan didasarkan pada indeks tersebut, seberapa sering nilai kolom indeks kunci akan berubah, dan seberapa besar. Jika nilai dalam kolom indeks berkerumun berubah atau kinerja indeks tidak sesuai yang diharapkan, semua indeks lain pada tabel dapat terpengaruh. Indeks berkerumun harus didasarkan pada kolom paling persisten yang nilainya meningkat dalam urutan tertentu tetapi tidak berubah secara acak. Indeks harus mendukung kueri terhadap data tabel yang paling sering diakses, sehingga kueri memanfaatkan sepenuhnya fakta bahwa data diurutkan dan dapat diakses di node akar, bagian daun indeks. Jika kunci utama cocok dengan skenario ini, gunakanlah. Jika tidak, pilih kumpulan kolom lain.
Bagaimana jika Anda mengindeks suatu tampilan, apakah masih berupa tampilan?
Tampilan adalah tabel virtual yang menghasilkan data dari satu atau lebih tabel. Pada dasarnya, ini adalah kueri bernama yang mengambil data dari tabel yang mendasarinya saat Anda menanyakan tampilan tersebut. Anda dapat meningkatkan kinerja kueri dengan membuat indeks berkerumun dan indeks non-kluster pada tampilan ini, mirip dengan cara Anda membuat indeks pada tabel, namun peringatan utamanya adalah Anda terlebih dahulu membuat indeks berkerumun, lalu Anda dapat membuat indeks yang tidak berkerumun.Ketika tampilan yang diindeks (tampilan terwujud) dibuat, definisi tampilan itu sendiri tetap menjadi entitas terpisah. Bagaimanapun, ini hanyalah operator yang dikodekan secara keras PILIH, disimpan dalam database. Namun indeksnya adalah cerita yang sangat berbeda. Saat Anda membuat indeks berkerumun atau tidak berkerumun pada penyedia, data disimpan secara fisik ke disk, seperti indeks biasa. Selain itu, ketika data dalam tabel yang mendasarinya berubah, indeks tampilan secara otomatis berubah (ini berarti Anda mungkin ingin menghindari pengindeksan tampilan pada tabel yang sering berubah). Bagaimanapun, tampilan tetap merupakan tampilan - tampilan tabel, tetapi yang dieksekusi saat ini, dengan indeks yang sesuai dengannya.
Sebelum Anda dapat membuat indeks pada suatu tampilan, indeks tersebut harus memenuhi beberapa batasan. Misalnya, suatu tampilan hanya dapat mereferensikan tabel dasar, namun tidak dapat mereferensikan tampilan lainnya, dan tabel tersebut harus berada dalam database yang sama. Sebenarnya masih banyak batasan lainnya, jadi pastikan untuk memeriksa dokumentasinya SQLServer untuk semua detail kotornya.
Mengapa menggunakan indeks penutup dan bukan indeks gabungan?
Pertama, mari pastikan kita memahami perbedaan keduanya. Indeks gabungan hanyalah indeks biasa yang berisi lebih dari satu kolom. Beberapa kolom kunci dapat digunakan untuk memastikan bahwa setiap baris dalam tabel bersifat unik, atau Anda mungkin memiliki beberapa kolom untuk memastikan bahwa kunci utama bersifat unik, atau Anda mungkin mencoba mengoptimalkan eksekusi kueri yang sering dipanggil pada beberapa kolom. Namun secara umum, semakin banyak kolom kunci yang terdapat dalam suatu indeks, semakin tidak efisien indeks tersebut, yang berarti bahwa indeks gabungan harus digunakan dengan bijaksana.Seperti yang dinyatakan, sebuah kueri bisa mendapatkan keuntungan besar jika semua data yang diperlukan segera ditempatkan di daun indeks, sama seperti indeks itu sendiri. Ini bukan masalah untuk indeks berkerumun karena semua data sudah ada (itulah sebabnya sangat penting untuk berpikir hati-hati saat membuat indeks berkerumun). Namun indeks non-cluster pada daun hanya berisi kolom kunci. Untuk mengakses semua data lainnya, pengoptimal kueri memerlukan langkah tambahan, yang dapat menambah overhead yang signifikan untuk mengeksekusi kueri Anda.
Di sinilah indeks cakupan berperan sebagai penyelamat. Saat Anda menentukan indeks noncluster, Anda bisa menentukan kolom tambahan ke kolom kunci Anda. Misalnya, aplikasi Anda sering menanyakan data kolom Id pemesanan Dan Tanggal pemesanan di meja Penjualan:
PILIH ID Pesanan, Tanggal Pesanan DARI Penjualan DI MANA ID Pesanan = 12345;
Anda dapat membuat indeks gabungan non-cluster pada kedua kolom, namun kolom OrderDate hanya akan menambahkan overhead pemeliharaan indeks tanpa berfungsi sebagai kolom kunci yang sangat berguna. Solusi terbaik adalah dengan membuat indeks penutup pada kolom kunci Id pemesanan dan tambahan termasuk kolom Tanggal pemesanan:
BUAT INDEKS NONCLUSTERED ix_orderid PADA dbo.Sales(OrderID) INCLUDE (OrderDate);
Hal ini menghindari kerugian pengindeksan kolom redundan sambil tetap mempertahankan manfaat menyimpan data di daun saat menjalankan kueri. Kolom yang disertakan bukan bagian dari kunci, namun data disimpan pada node daun, daun indeks. Hal ini dapat meningkatkan kinerja kueri tanpa biaya tambahan apa pun. Selain itu, kolom-kolom yang termasuk dalam indeks penutup memiliki batasan yang lebih sedikit dibandingkan kolom-kolom utama indeks.
Apakah jumlah duplikat di kolom kunci penting?
Saat Anda membuat indeks, Anda harus mencoba mengurangi jumlah duplikat di kolom kunci Anda. Atau lebih tepatnya: usahakan untuk menjaga tingkat pengulangan serendah mungkin.Jika Anda bekerja dengan indeks komposit, maka duplikasi berlaku untuk semua kolom kunci secara keseluruhan. Satu kolom bisa berisi banyak nilai duplikat, namun harus ada pengulangan minimal di antara semua kolom indeks. Misalnya, Anda membuat indeks gabungan noncluster pada kolom Nama depan Dan Nama keluarga, Anda dapat memiliki banyak nilai John Doe dan banyak nilai Doe, tetapi Anda ingin memiliki nilai John Doe sesedikit mungkin, atau sebaiknya hanya satu nilai John Doe.
Rasio keunikan nilai kolom kunci disebut selektivitas indeks. Semakin banyak nilai uniknya, semakin tinggi selektivitasnya: indeks unik memiliki selektivitas sebesar mungkin. Mesin kueri sangat menyukai kolom dengan nilai selektivitas tinggi, terutama jika kolom tersebut termasuk dalam klausa WHERE dari kueri yang paling sering Anda jalankan. Semakin selektif indeksnya, semakin cepat mesin kueri dapat mengurangi ukuran kumpulan data yang dihasilkan. Kelemahannya, tentu saja, kolom dengan nilai unik yang relatif sedikit jarang menjadi kandidat yang baik untuk diindeks.
Apakah mungkin membuat indeks non-cluster hanya pada subset tertentu dari data kolom kunci?
Secara default, indeks noncluster berisi satu baris untuk setiap baris dalam tabel. Tentu saja, Anda dapat mengatakan hal yang sama tentang indeks berkerumun, dengan asumsi bahwa indeks tersebut adalah sebuah tabel. Namun jika menyangkut indeks non-cluster, hubungan satu-ke-satu merupakan konsep yang penting karena, dimulai dengan versi SQLServer 2008, Anda memiliki opsi untuk membuat indeks yang dapat difilter yang membatasi baris yang disertakan di dalamnya. Indeks yang difilter dapat meningkatkan kinerja kueri karena... ukurannya lebih kecil dan berisi statistik yang terfilter dan lebih akurat daripada semua statistik tabel - hal ini mengarah pada pembuatan rencana pelaksanaan yang lebih baik. Indeks yang difilter juga memerlukan lebih sedikit ruang penyimpanan dan biaya pemeliharaan yang lebih rendah. Indeks diperbarui hanya ketika data yang cocok dengan filter berubah.Selain itu, indeks yang dapat disaring juga mudah dibuat. Di operator BUAT INDEKS Anda hanya perlu masuk DI MANA kondisi penyaring. Misalnya, Anda dapat memfilter semua baris yang mengandung NULL dari indeks, seperti yang ditunjukkan dalam kode:
BUAT INDEKS NONCLUSTERED ix_trackingnumber PADA Sales.SalesOrderDetail(CarrierTrackingNumber) DI MANA CarrierTrackingNumber BUKAN NULL;
Faktanya, kami dapat memfilter data apa pun yang tidak penting dalam kueri penting. Tapi hati-hati, karena... SQLServer menerapkan beberapa batasan pada indeks yang dapat difilter, seperti ketidakmampuan membuat indeks yang dapat difilter pada tampilan, jadi bacalah dokumentasi dengan cermat.
Mungkin juga Anda bisa mencapai hasil serupa dengan membuat tampilan yang diindeks. Namun, indeks yang difilter memiliki beberapa keuntungan, seperti kemampuan untuk mengurangi biaya pemeliharaan dan meningkatkan kualitas rencana pelaksanaan Anda. Indeks yang difilter juga dapat dibuat ulang secara online. Coba ini dengan tampilan yang diindeks.
Dan lagi sedikit dari penerjemah
Tujuan munculnya terjemahan ini di halaman Habrahabr adalah untuk menceritakan atau mengingatkan Anda tentang blog SimpleTalk dari Gerbang Merah.
Ini menerbitkan banyak posting yang menghibur dan menarik.
Saya tidak berafiliasi dengan produk perusahaan mana pun Gerbang Merah, maupun dengan penjualannya.
Seperti yang dijanjikan, buku untuk mereka yang ingin tahu lebih banyak
Saya merekomendasikan tiga buku yang sangat bagus dari saya sendiri (tautan mengarah ke menyalakan versi di toko Amazon):
 |
Dasar-Dasar T-SQL Microsoft SQL Server 2012 (Referensi Pengembang) Penulis Itzik Ben-Gan Tanggal Publikasi: 15 Juli 2012 Penulis, seorang ahli dalam bidangnya, memberikan pengetahuan dasar tentang bekerja dengan database. Jika Anda lupa segalanya atau tidak pernah mengetahuinya, ini pasti layak untuk dibaca. | Pada prinsipnya, Anda dapat membuka indeks sederhana